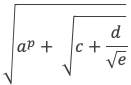
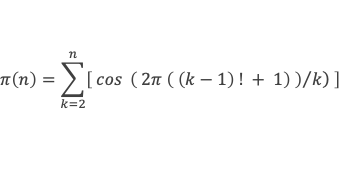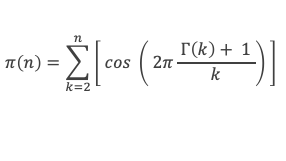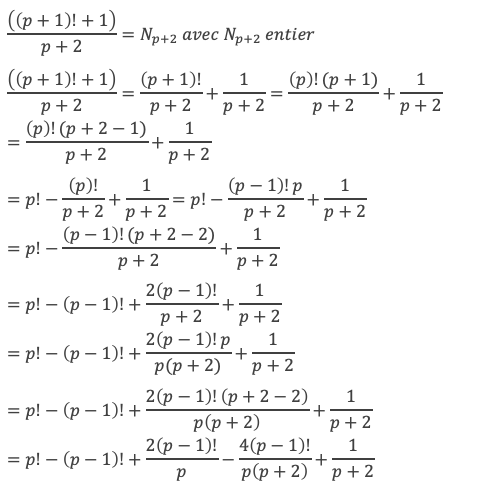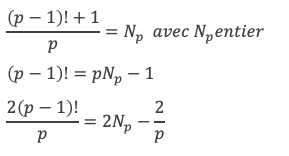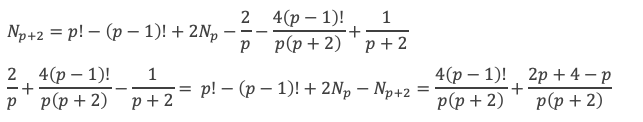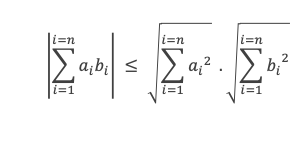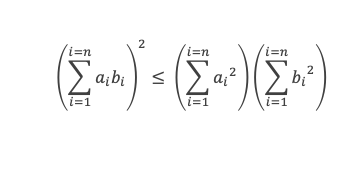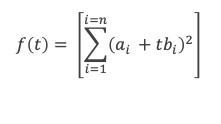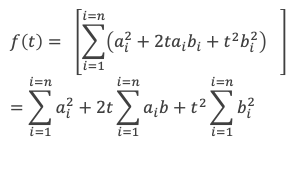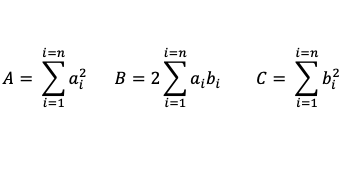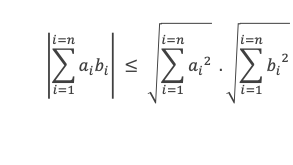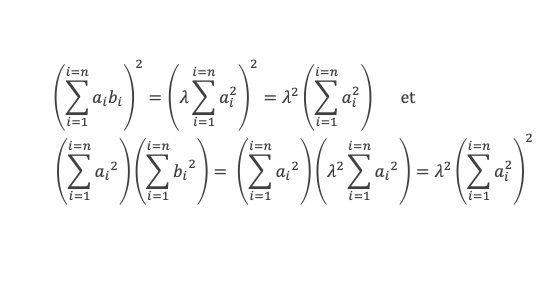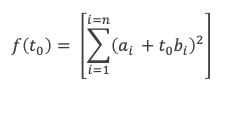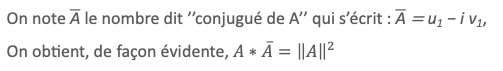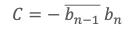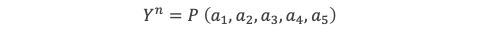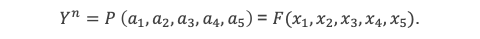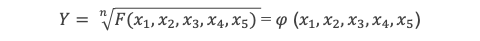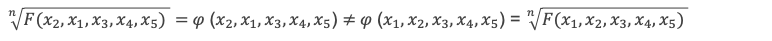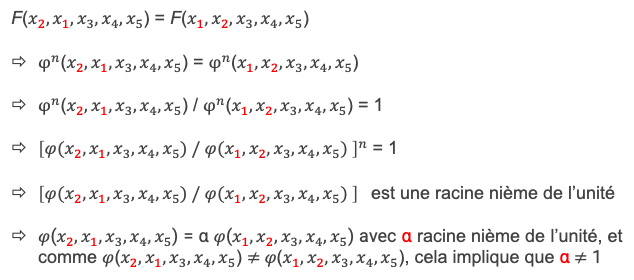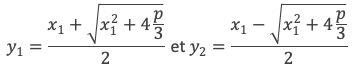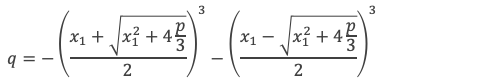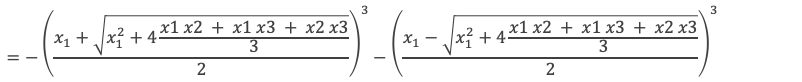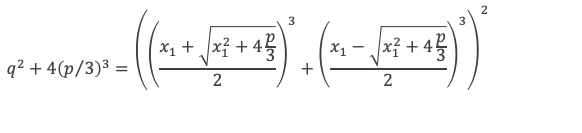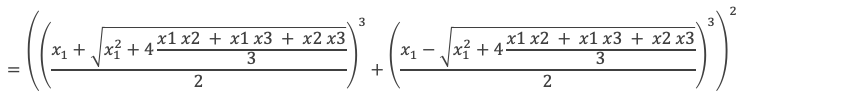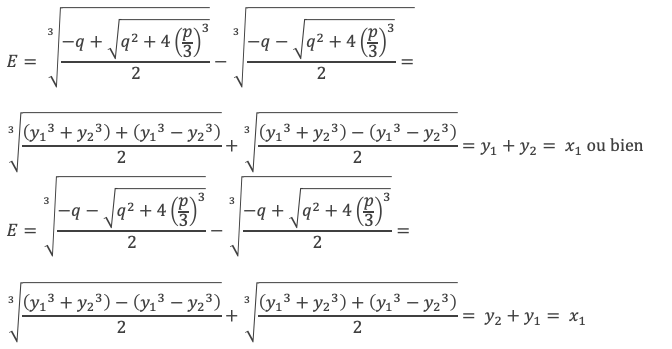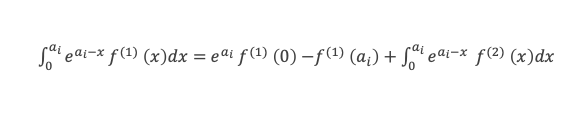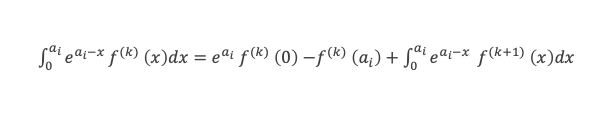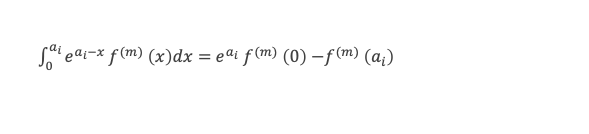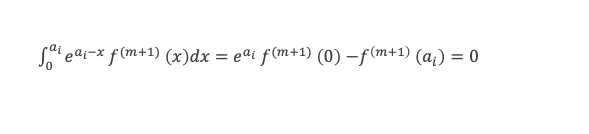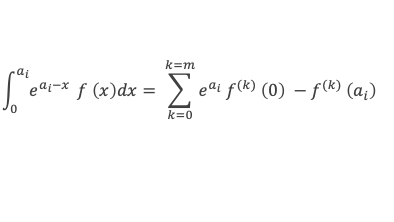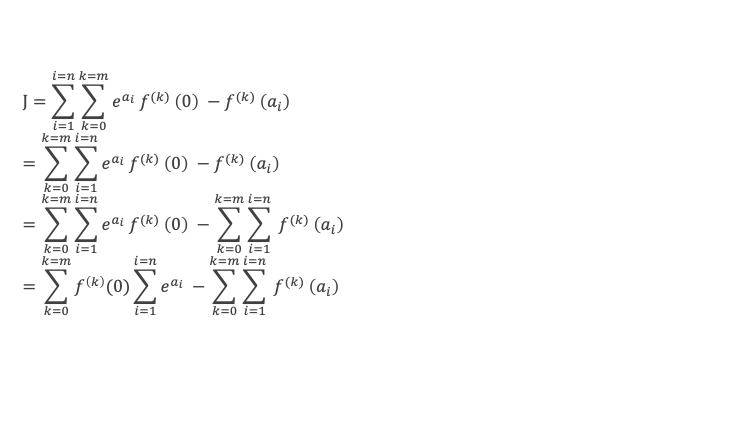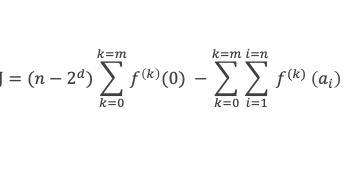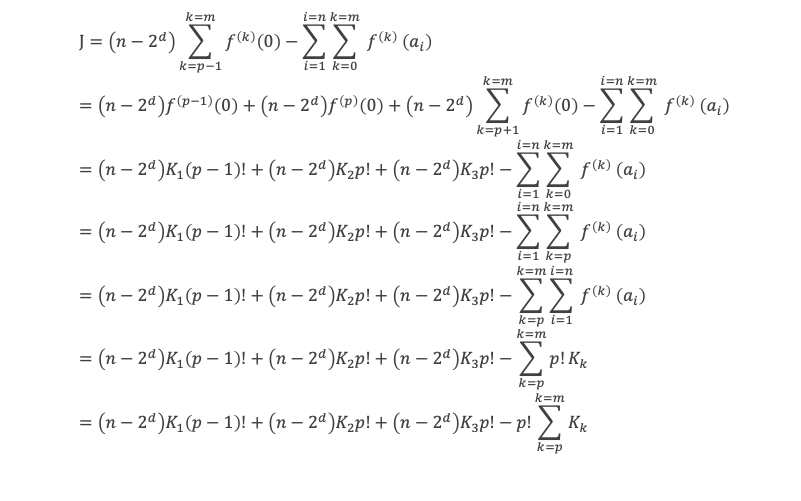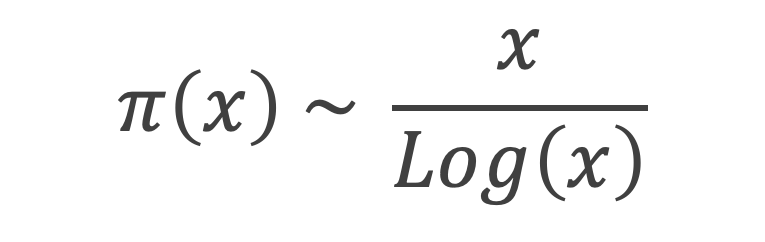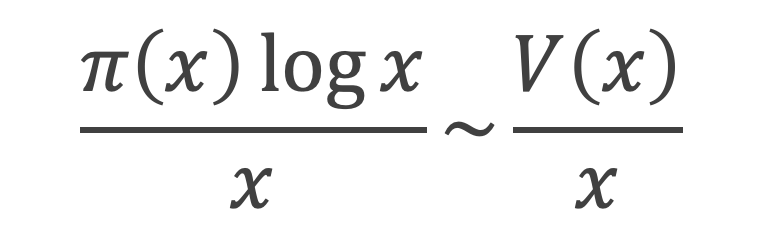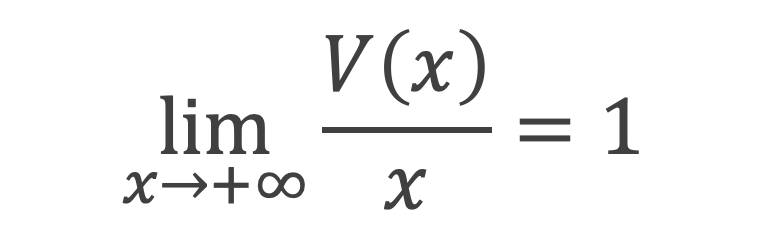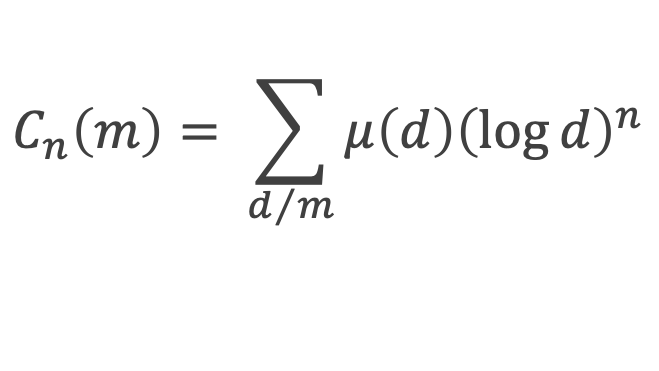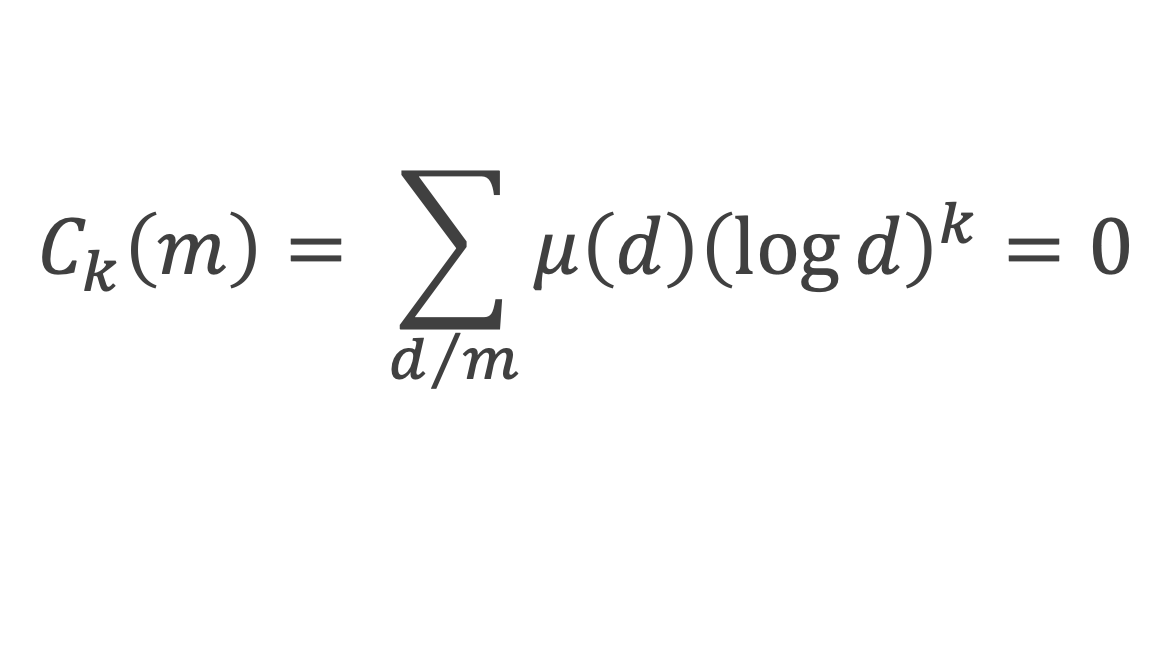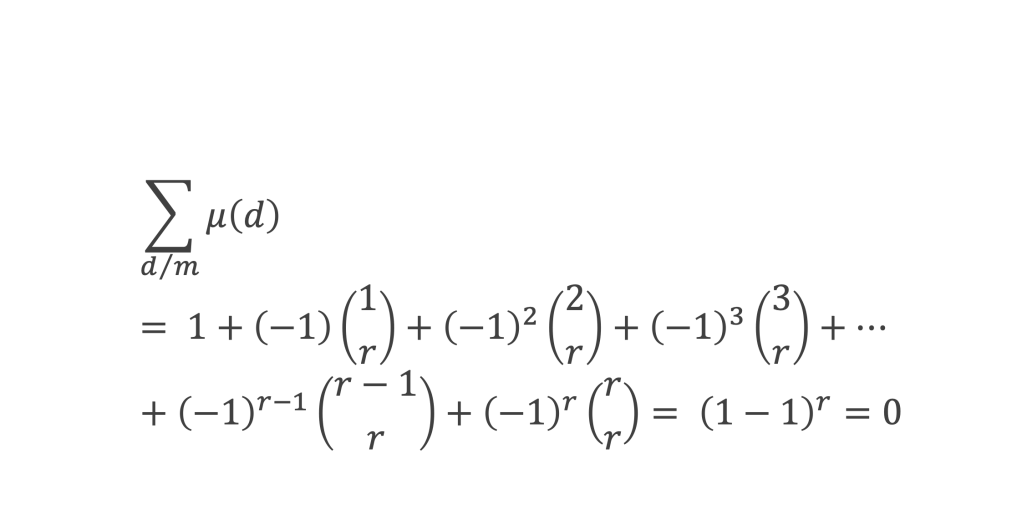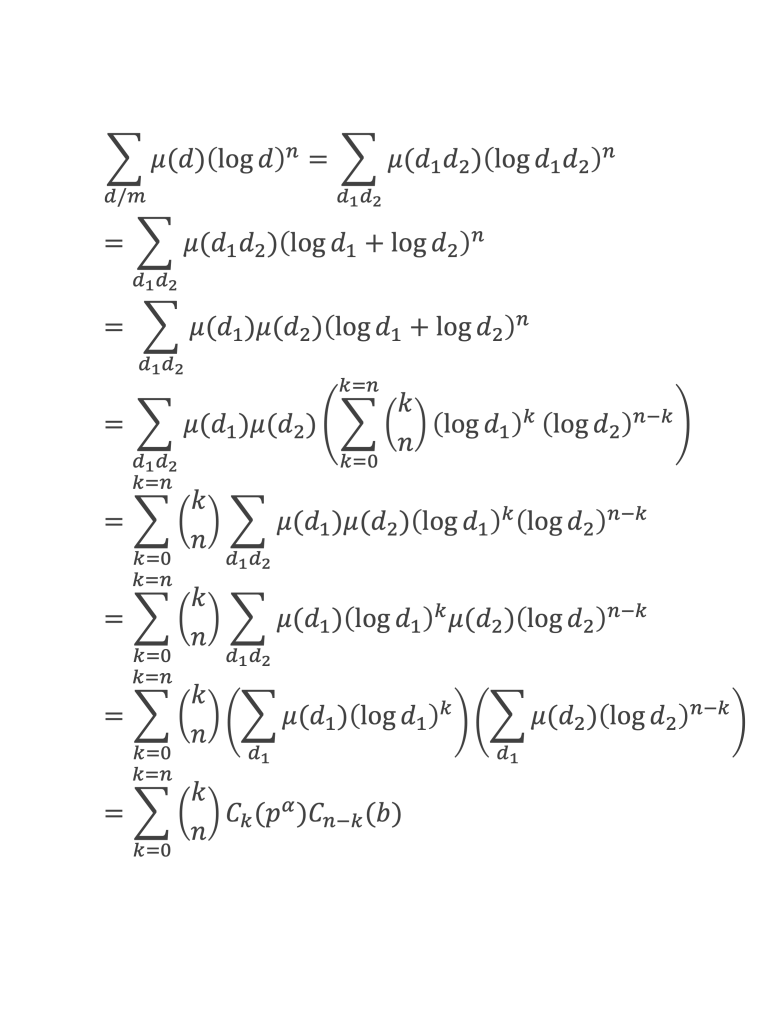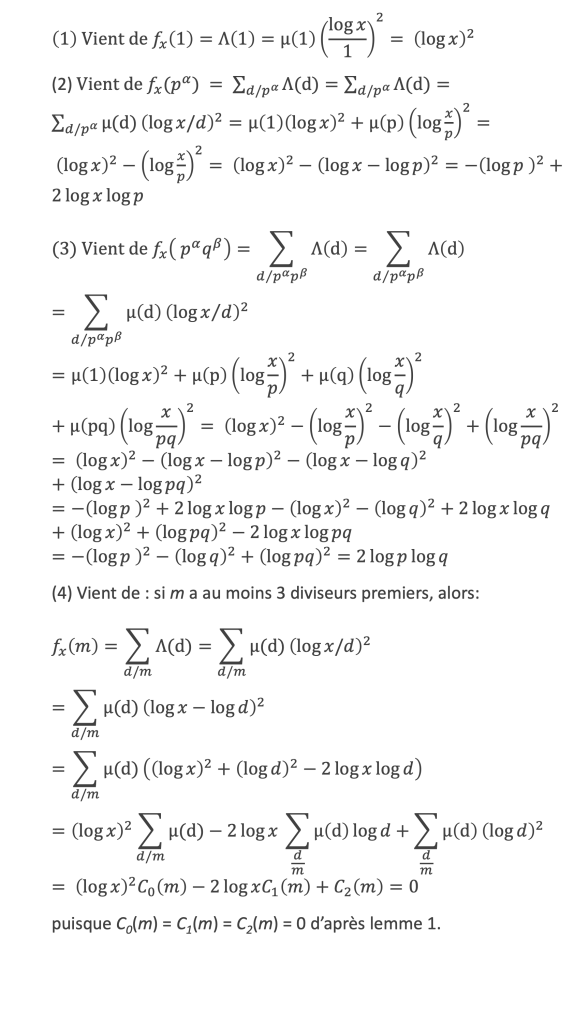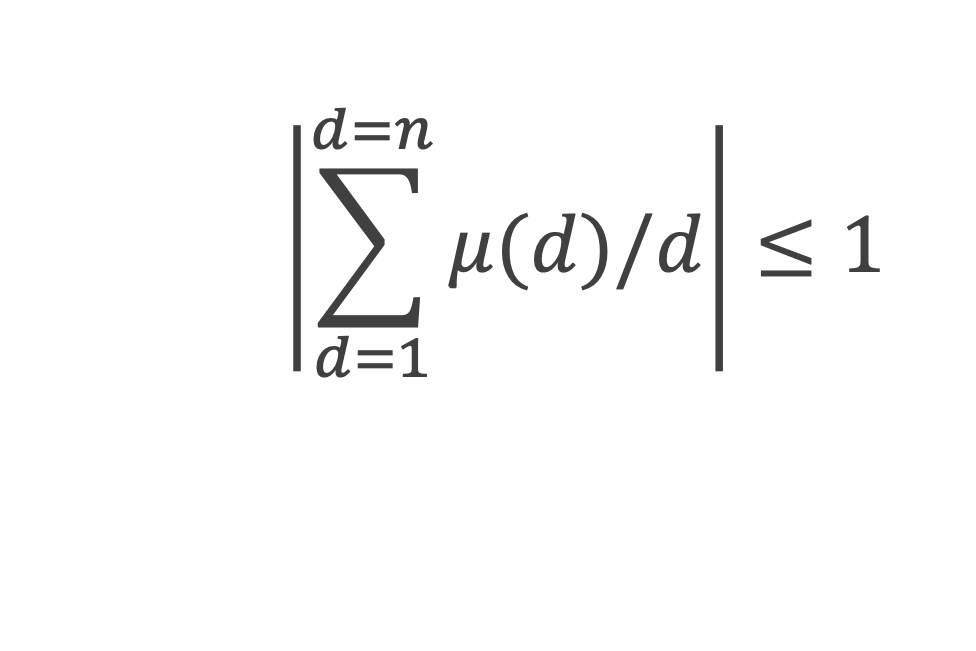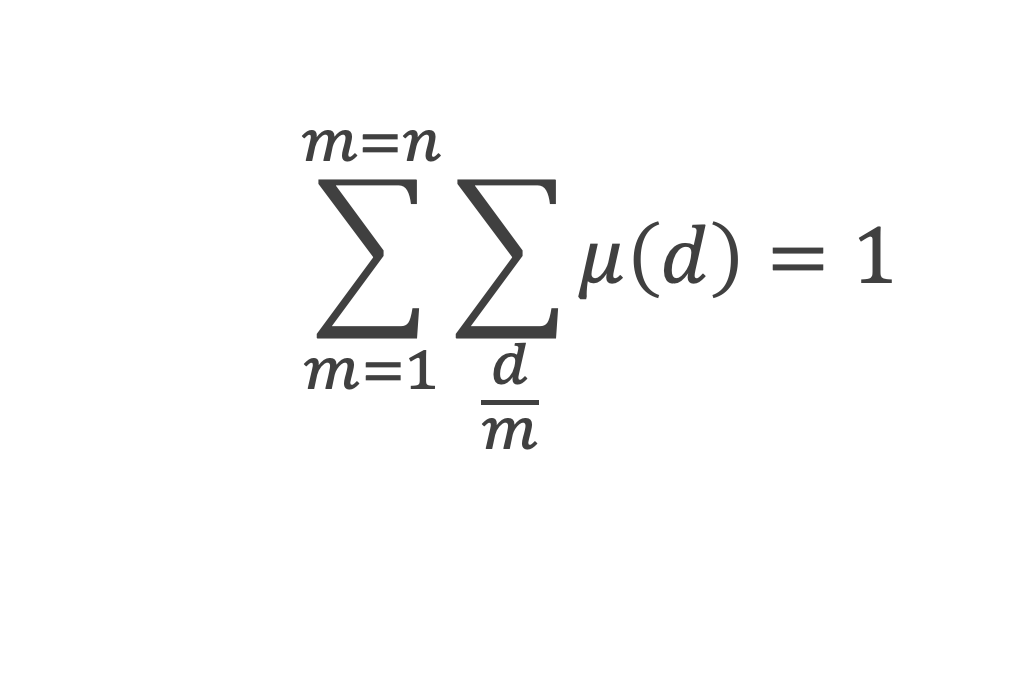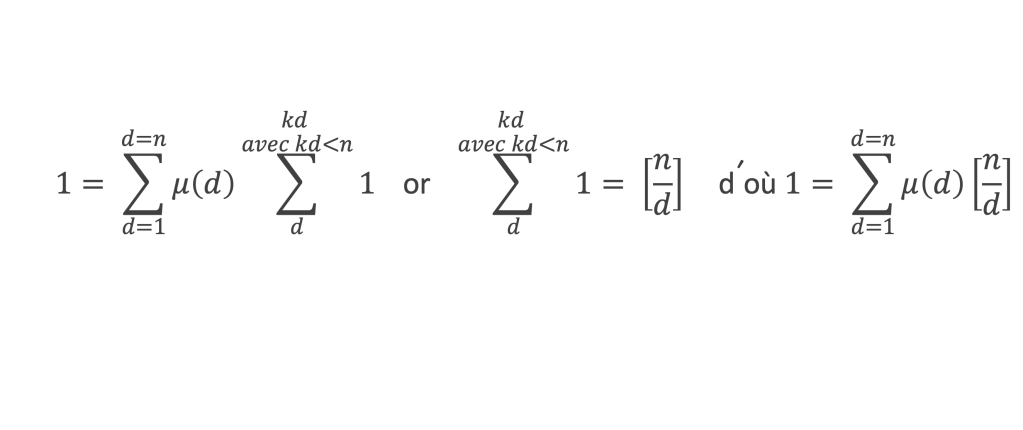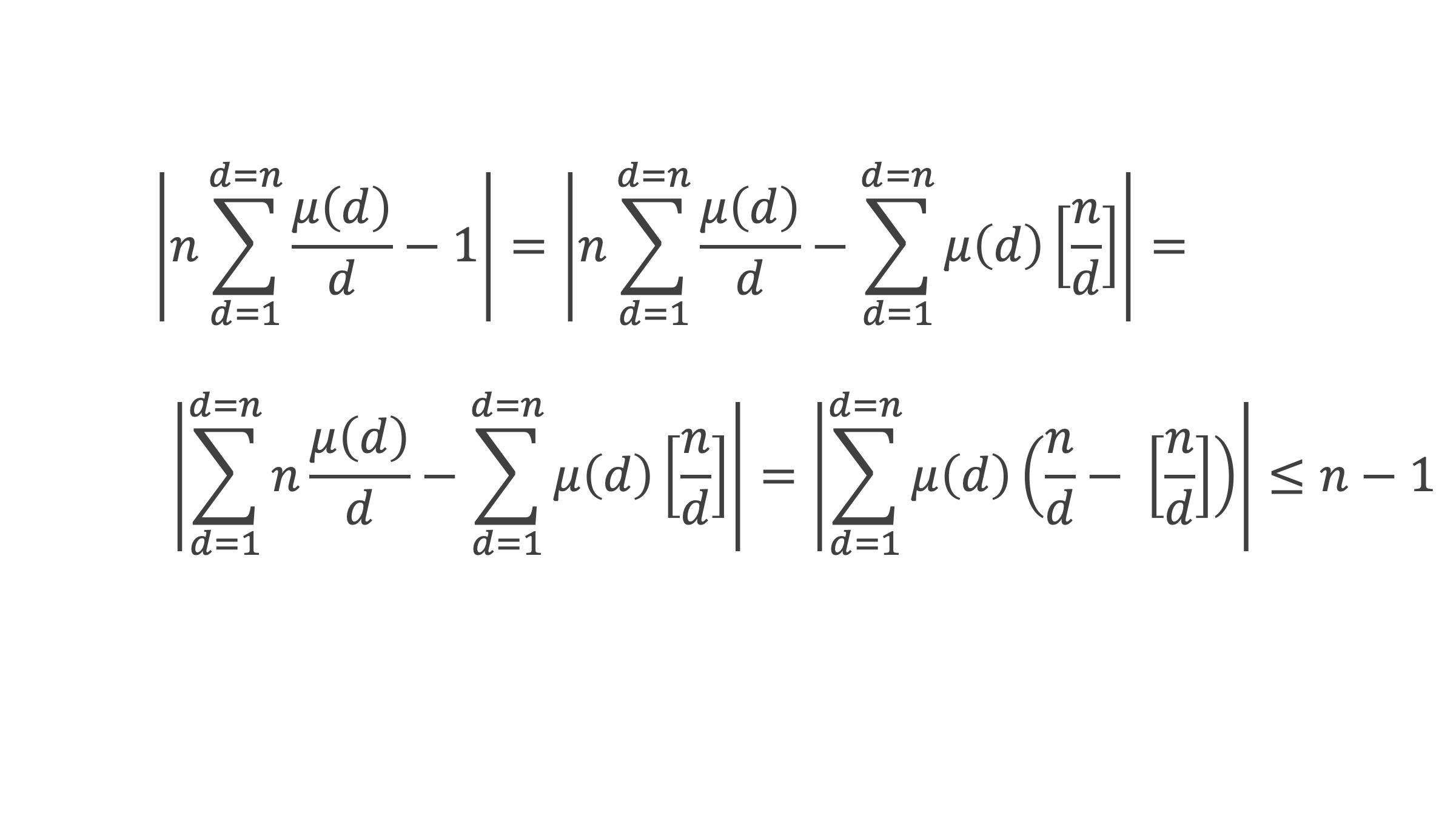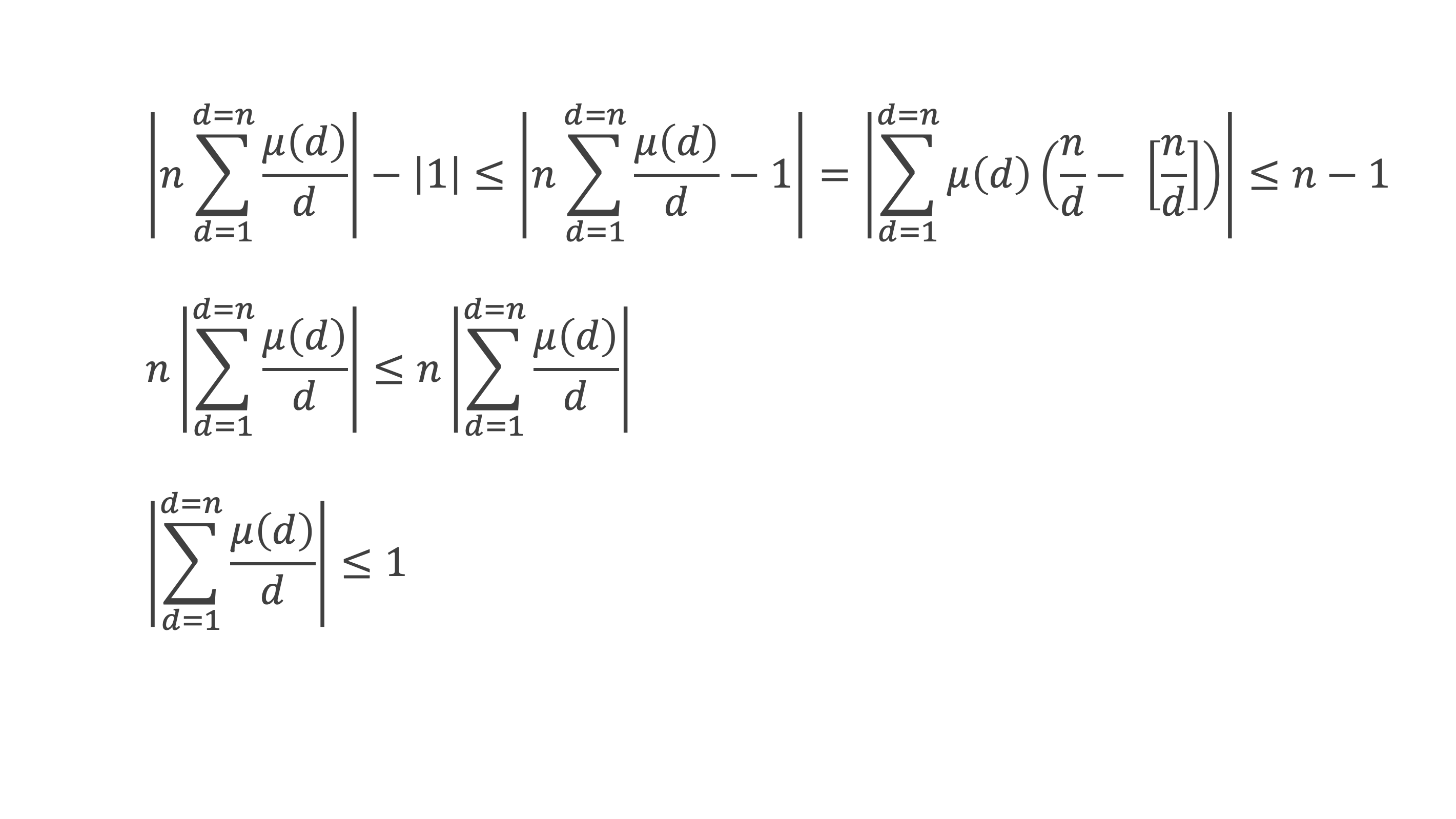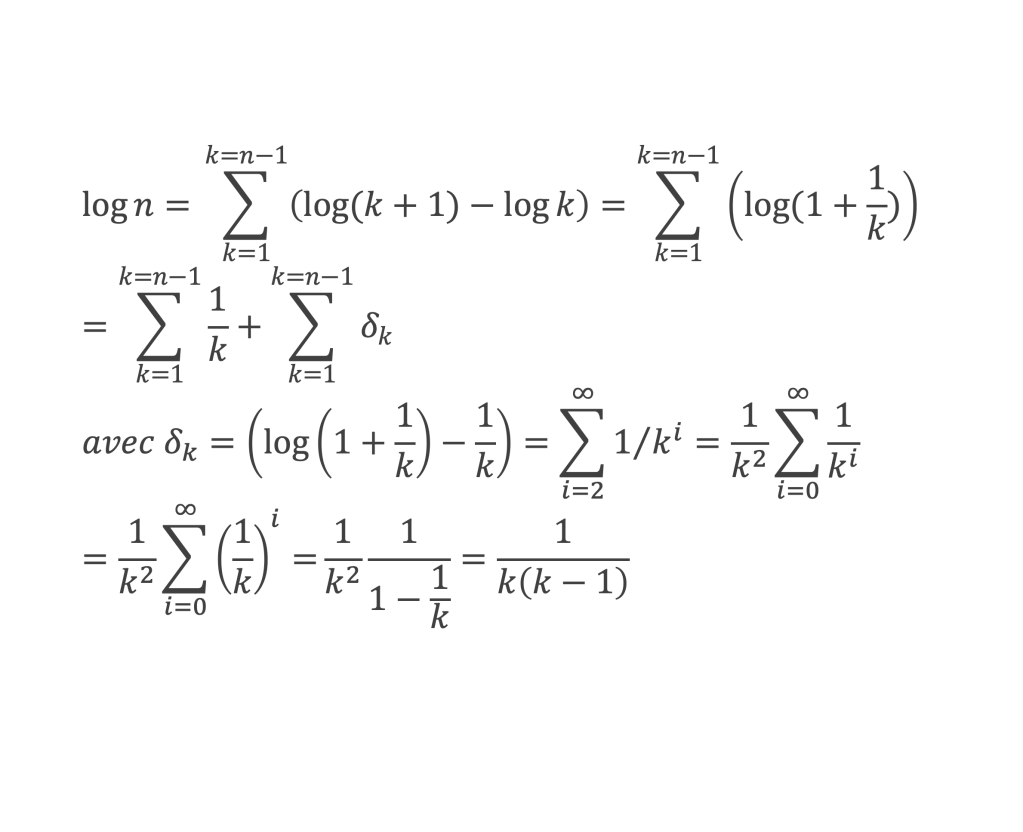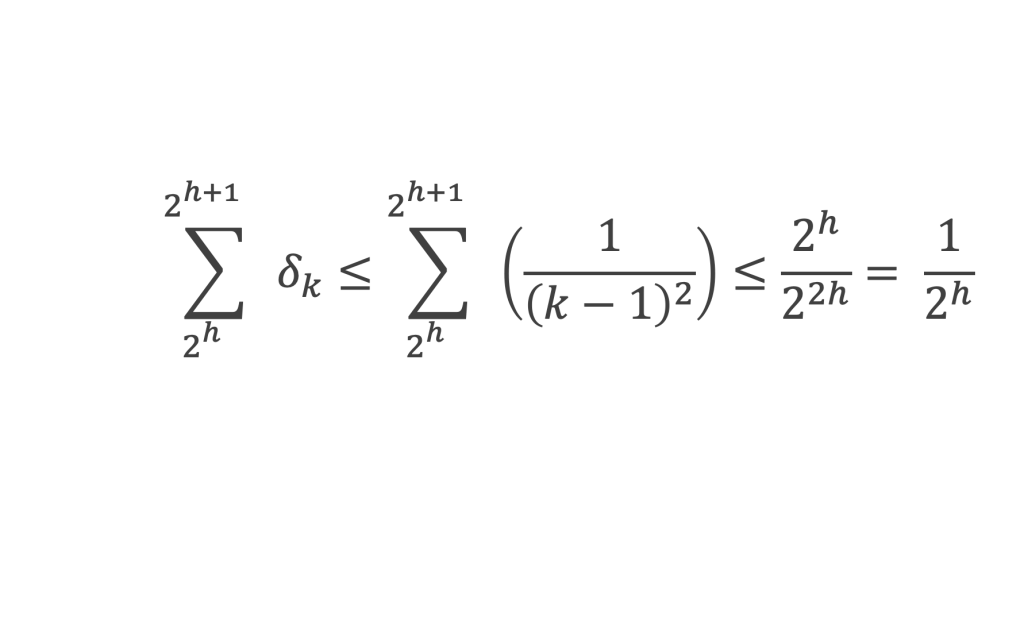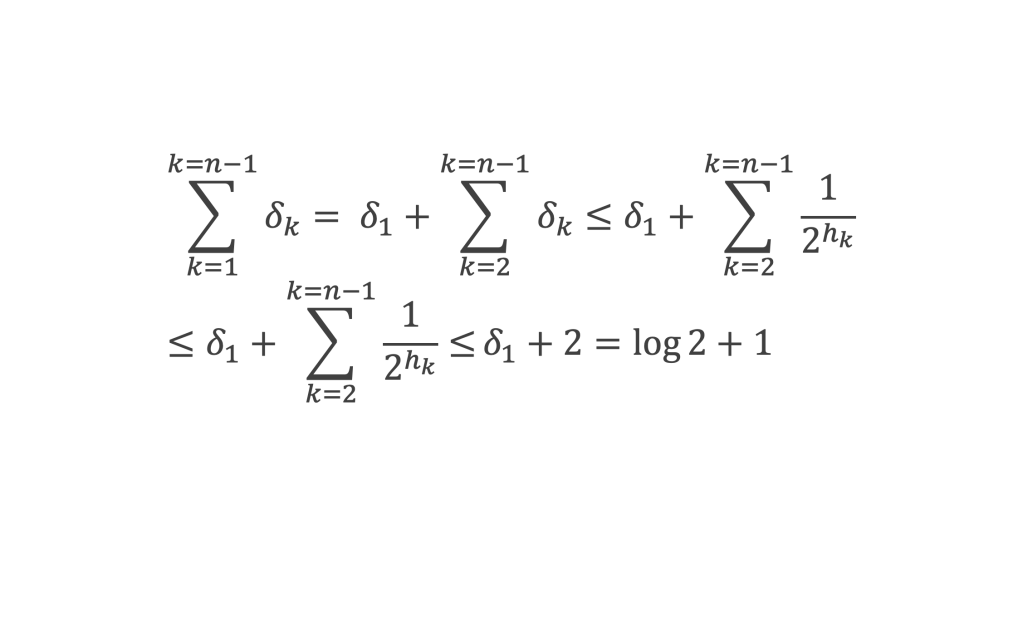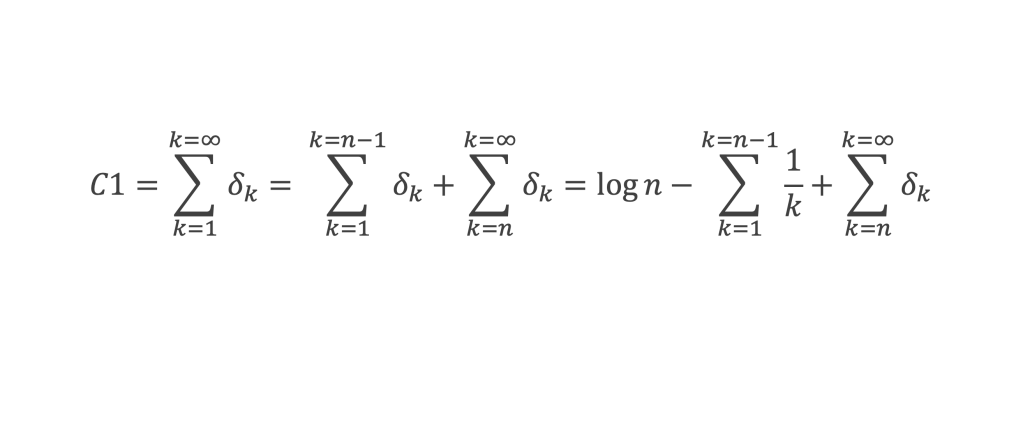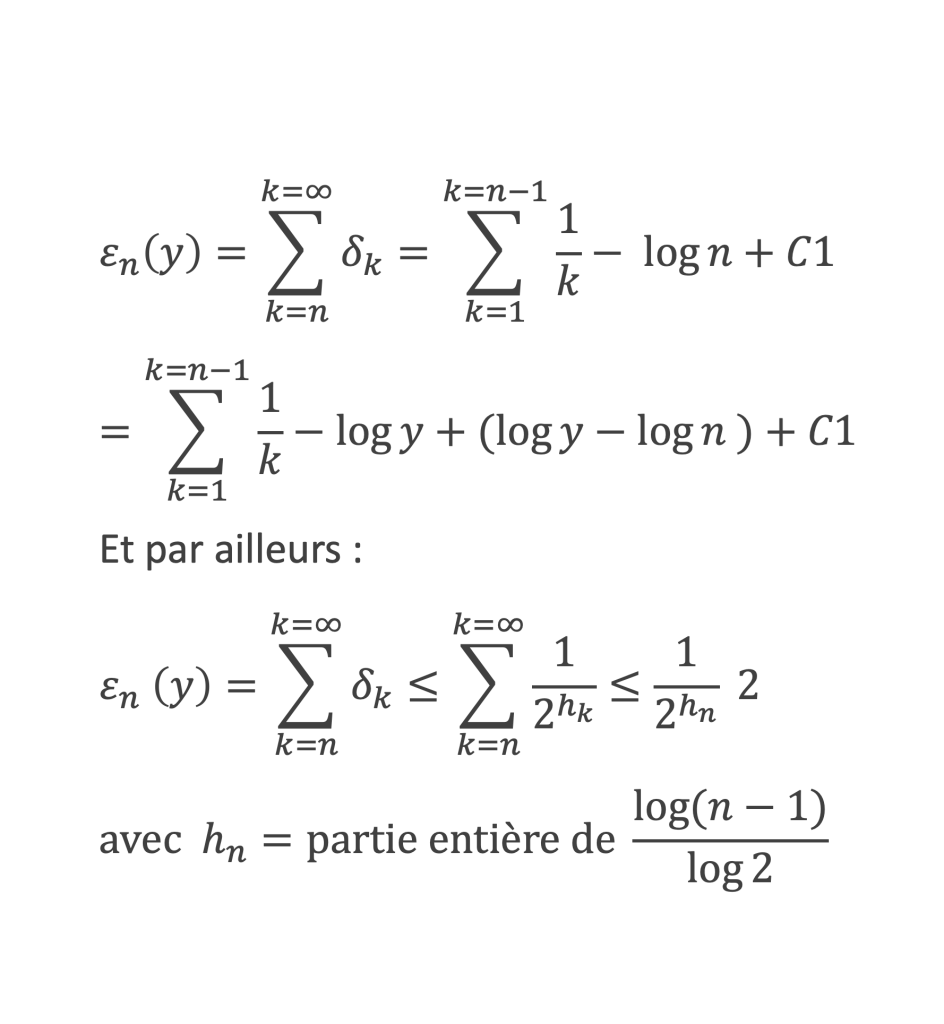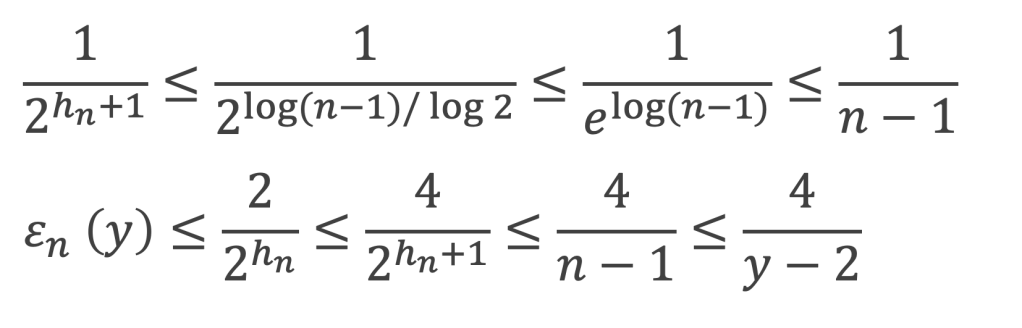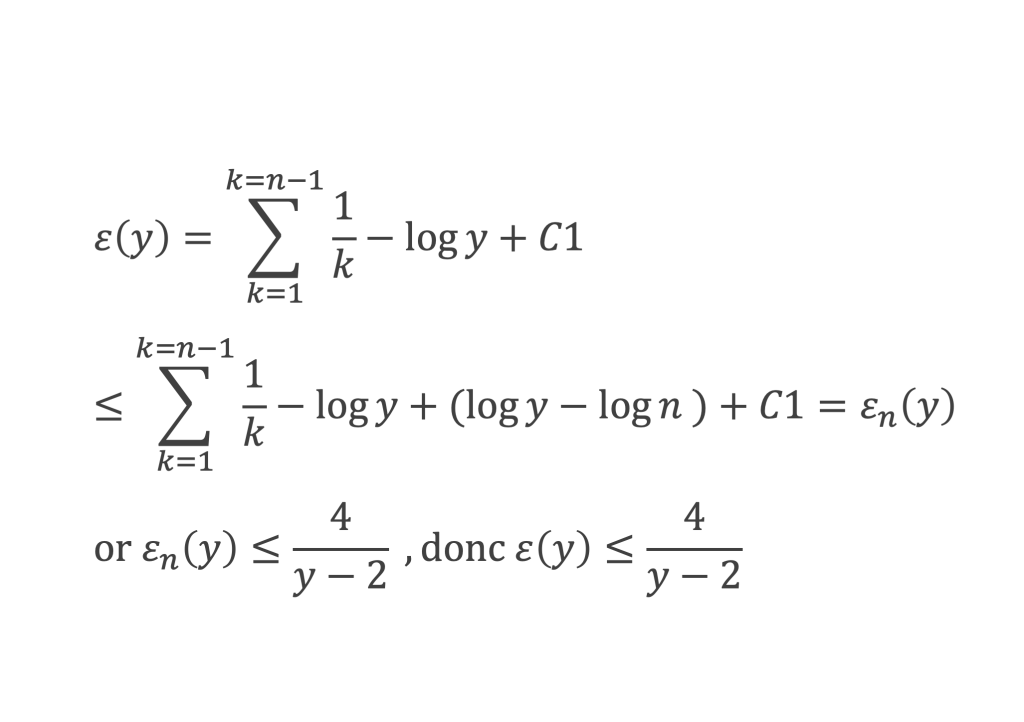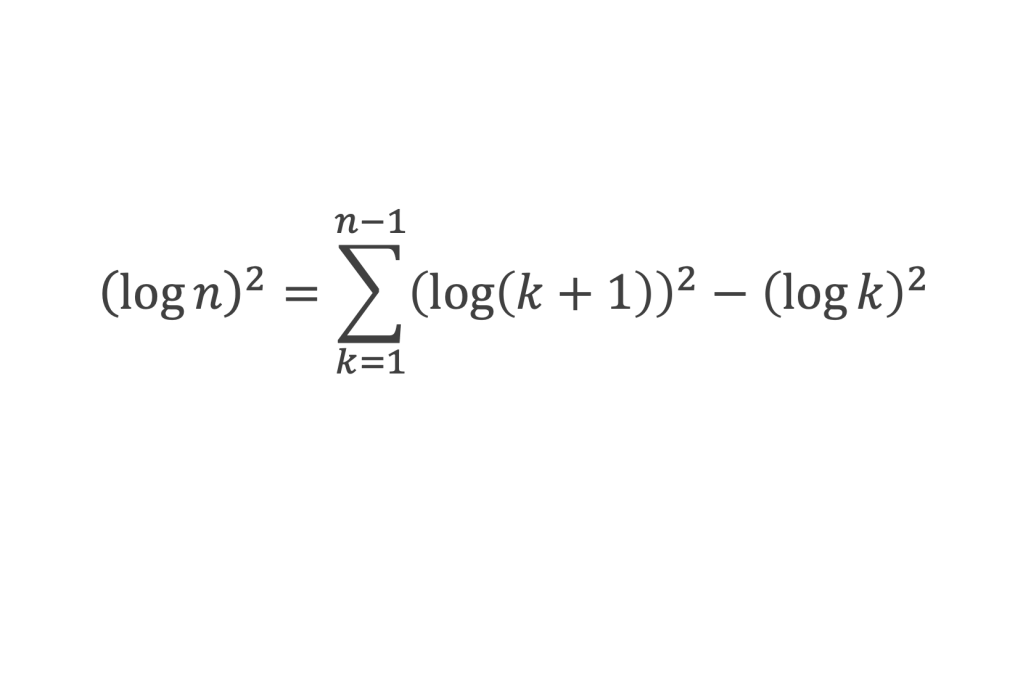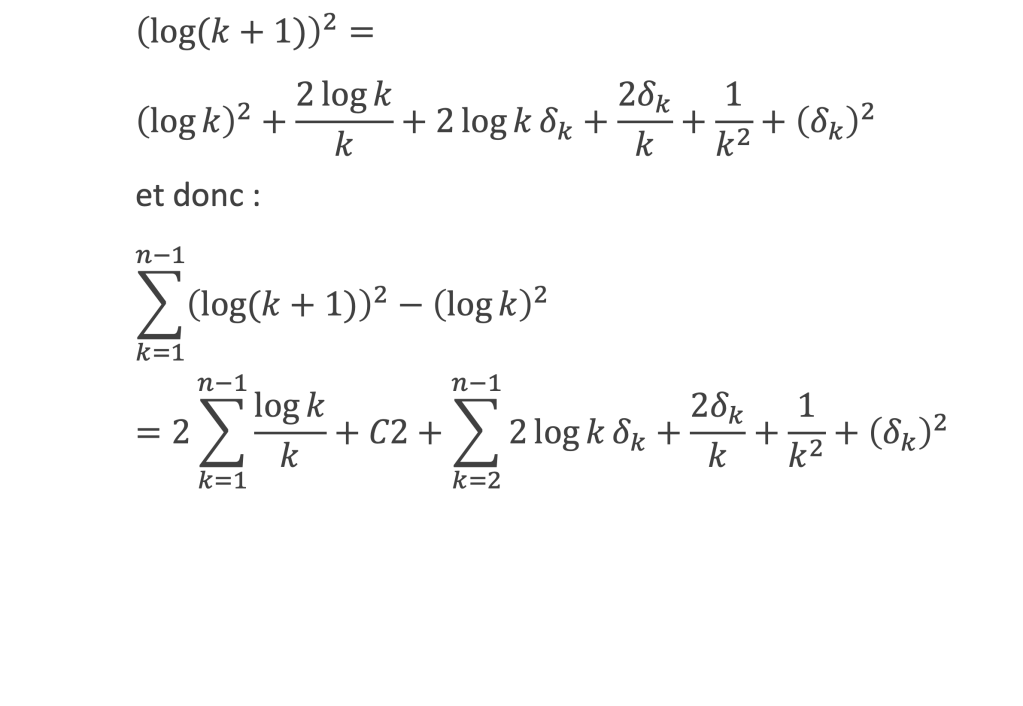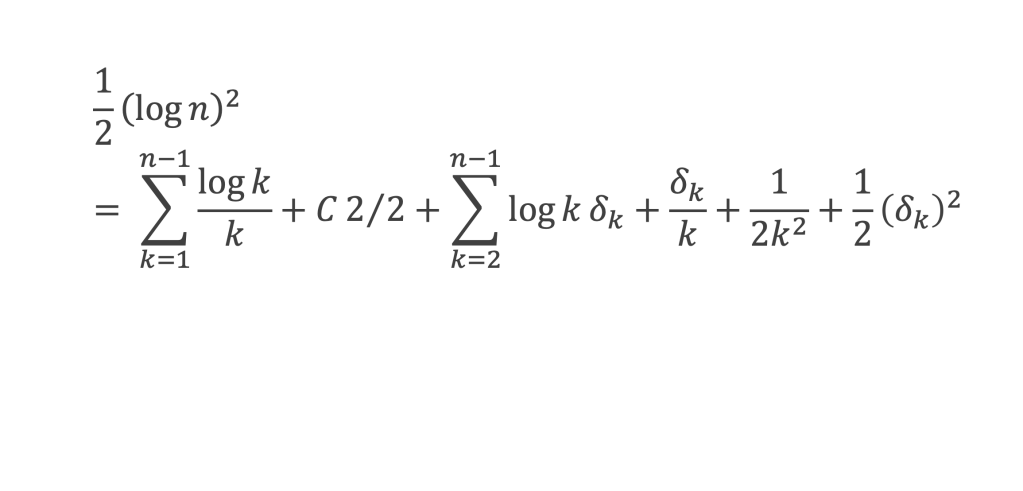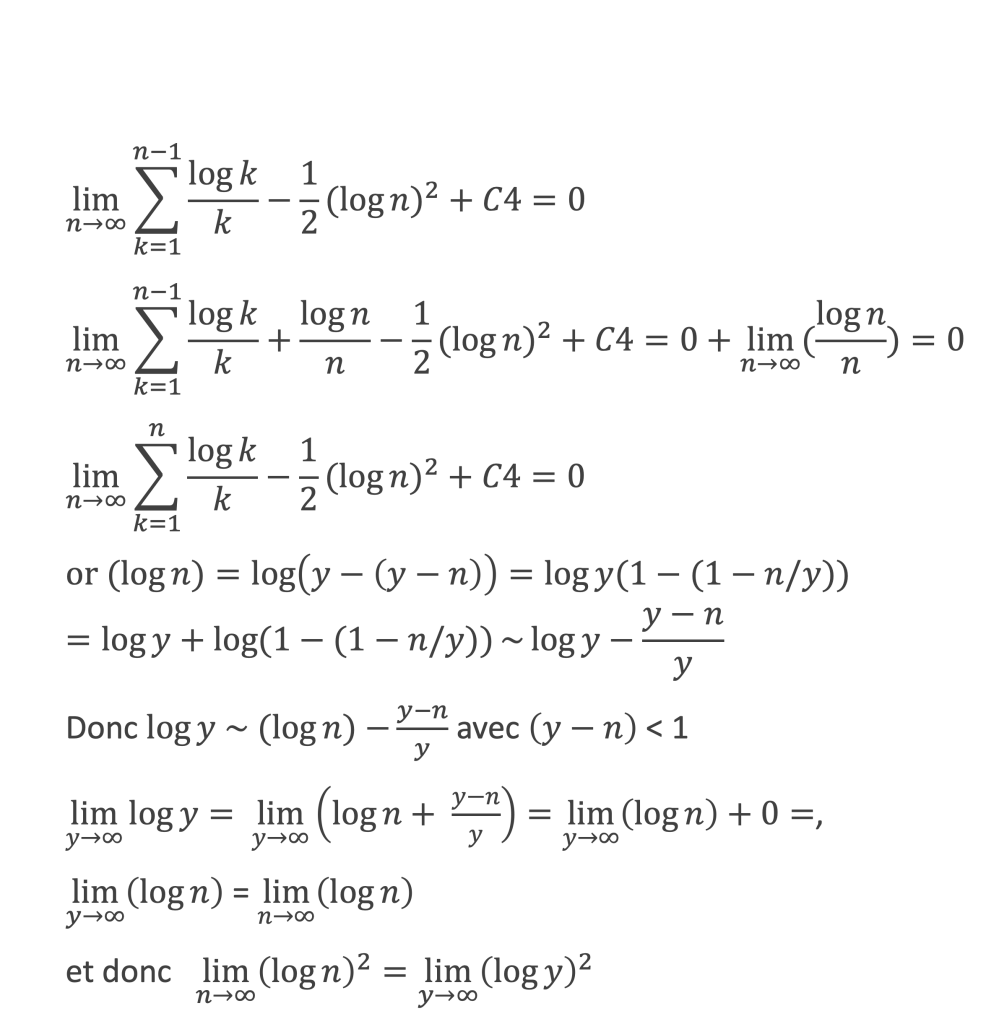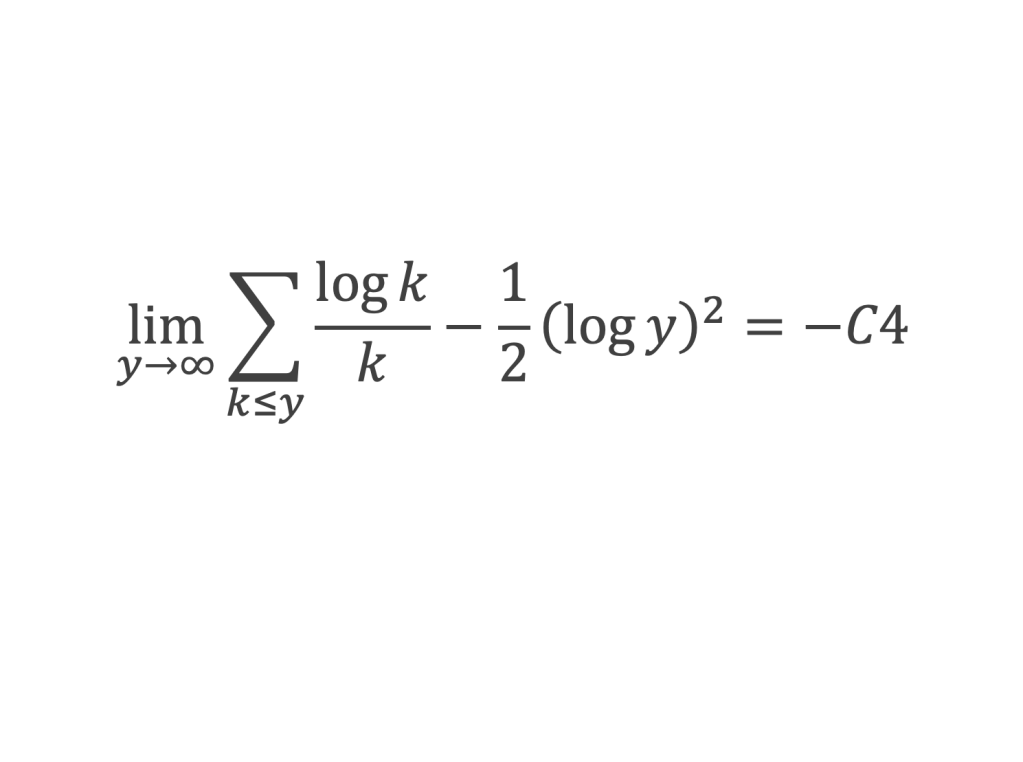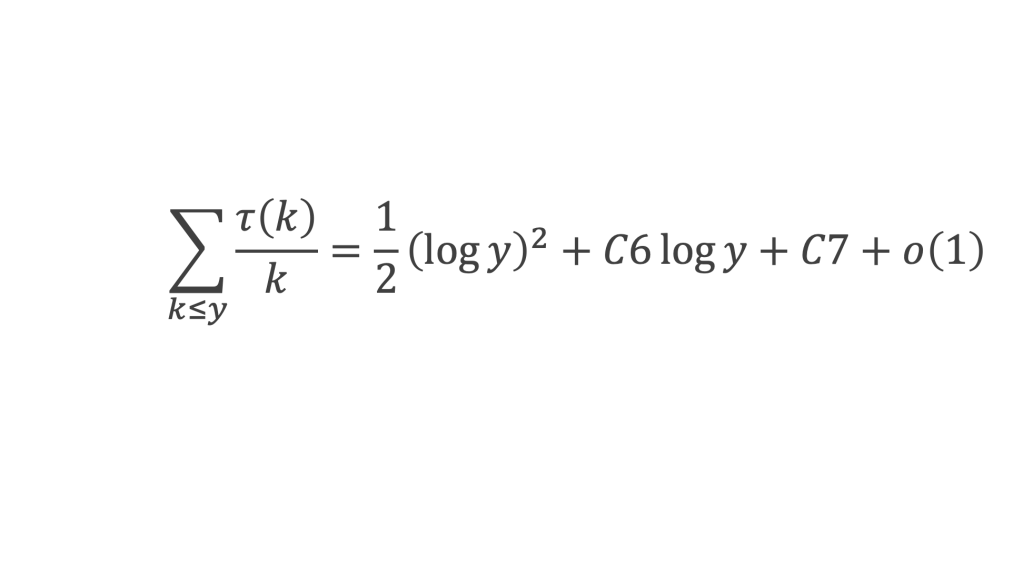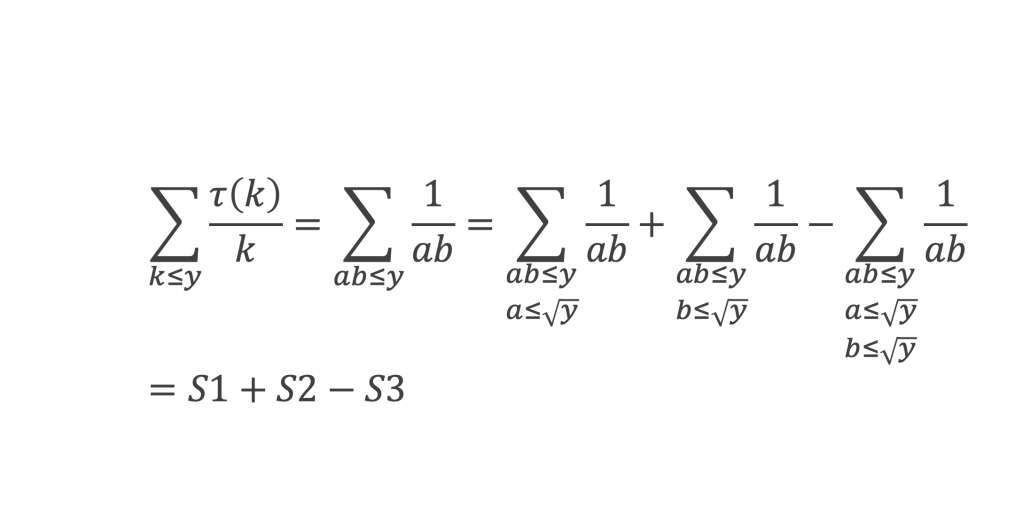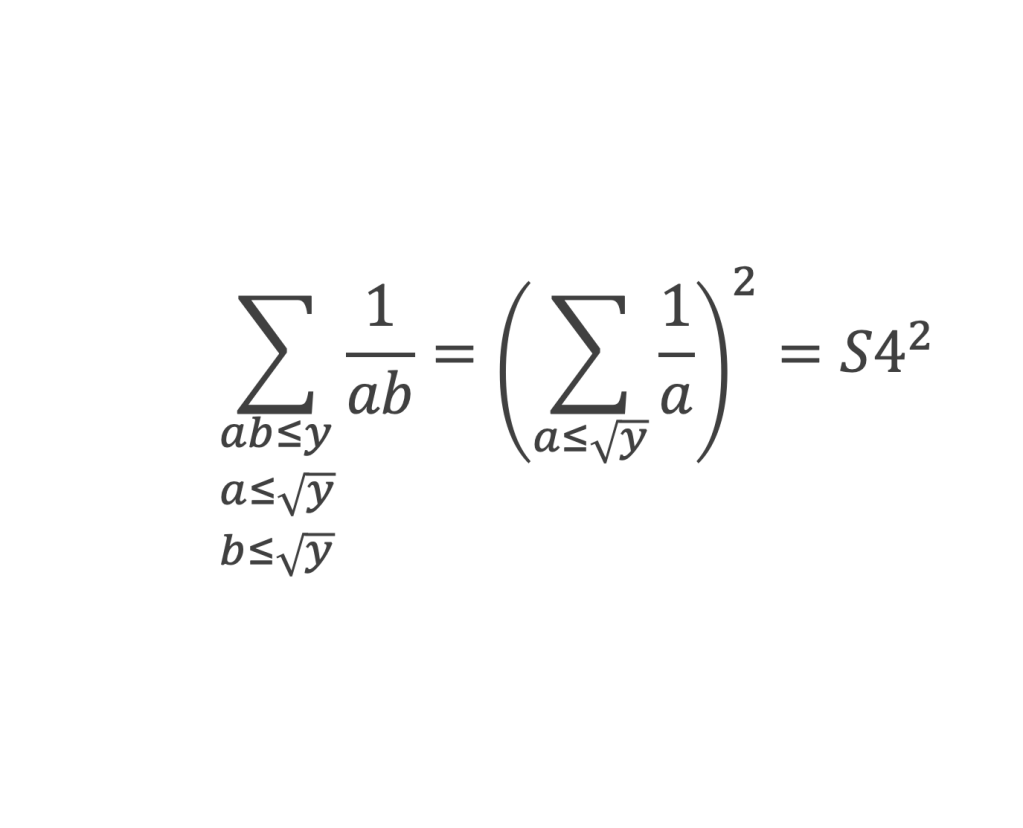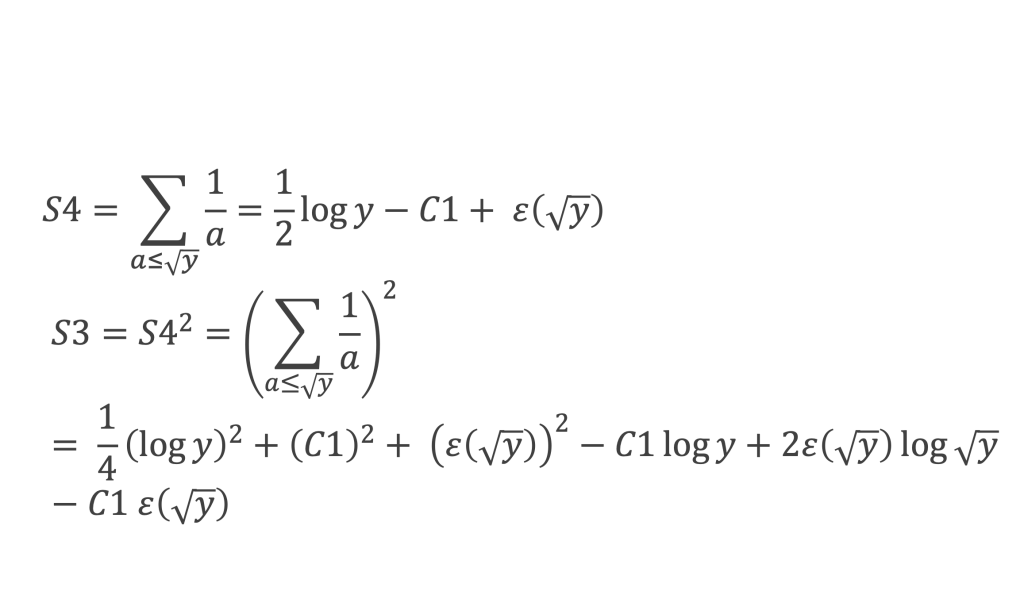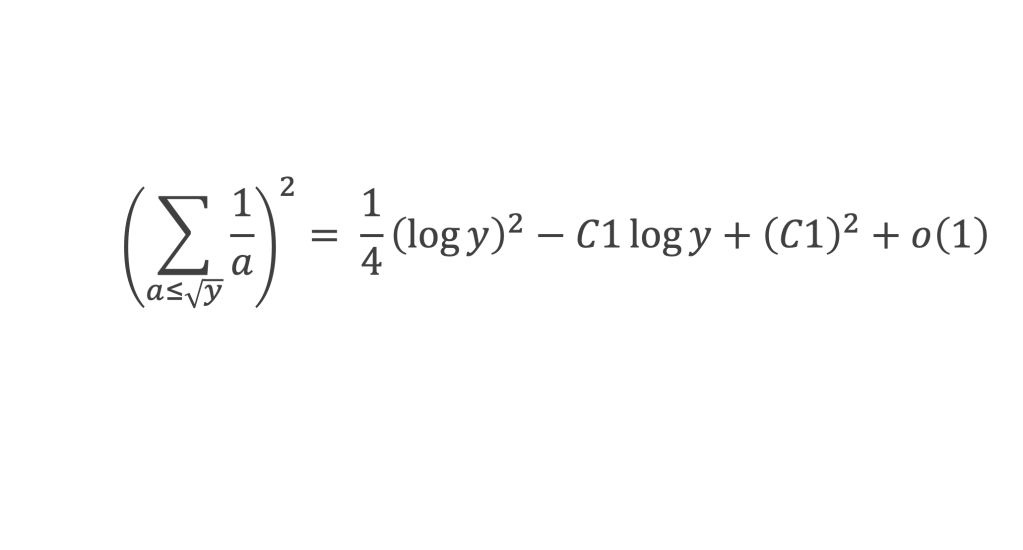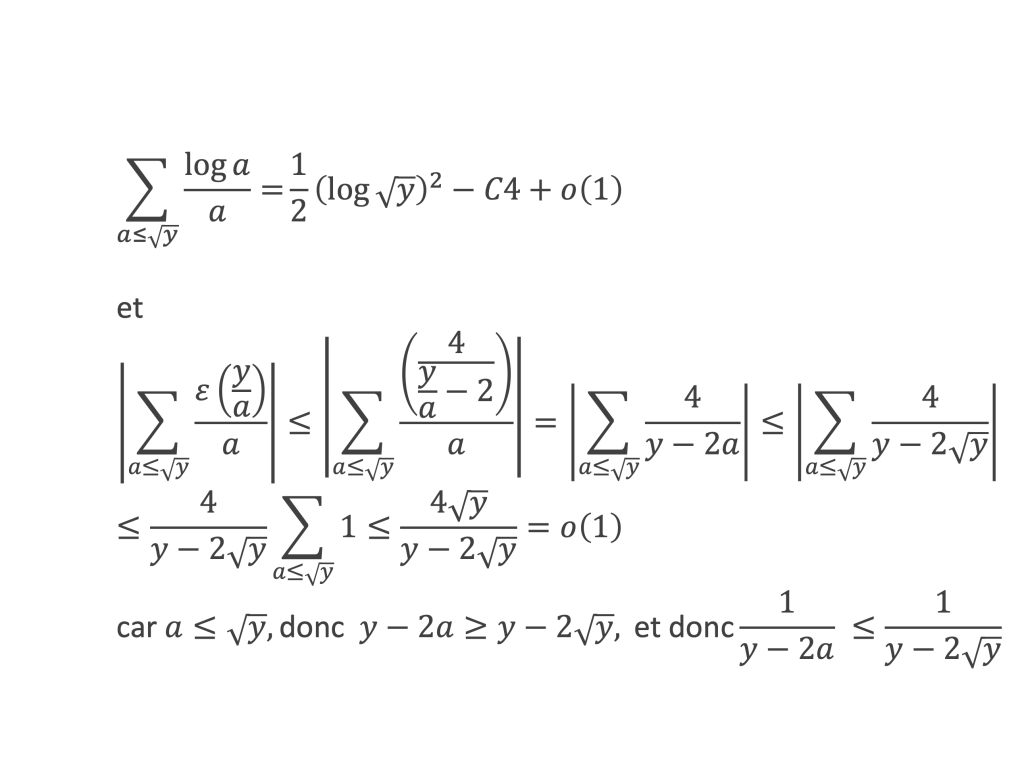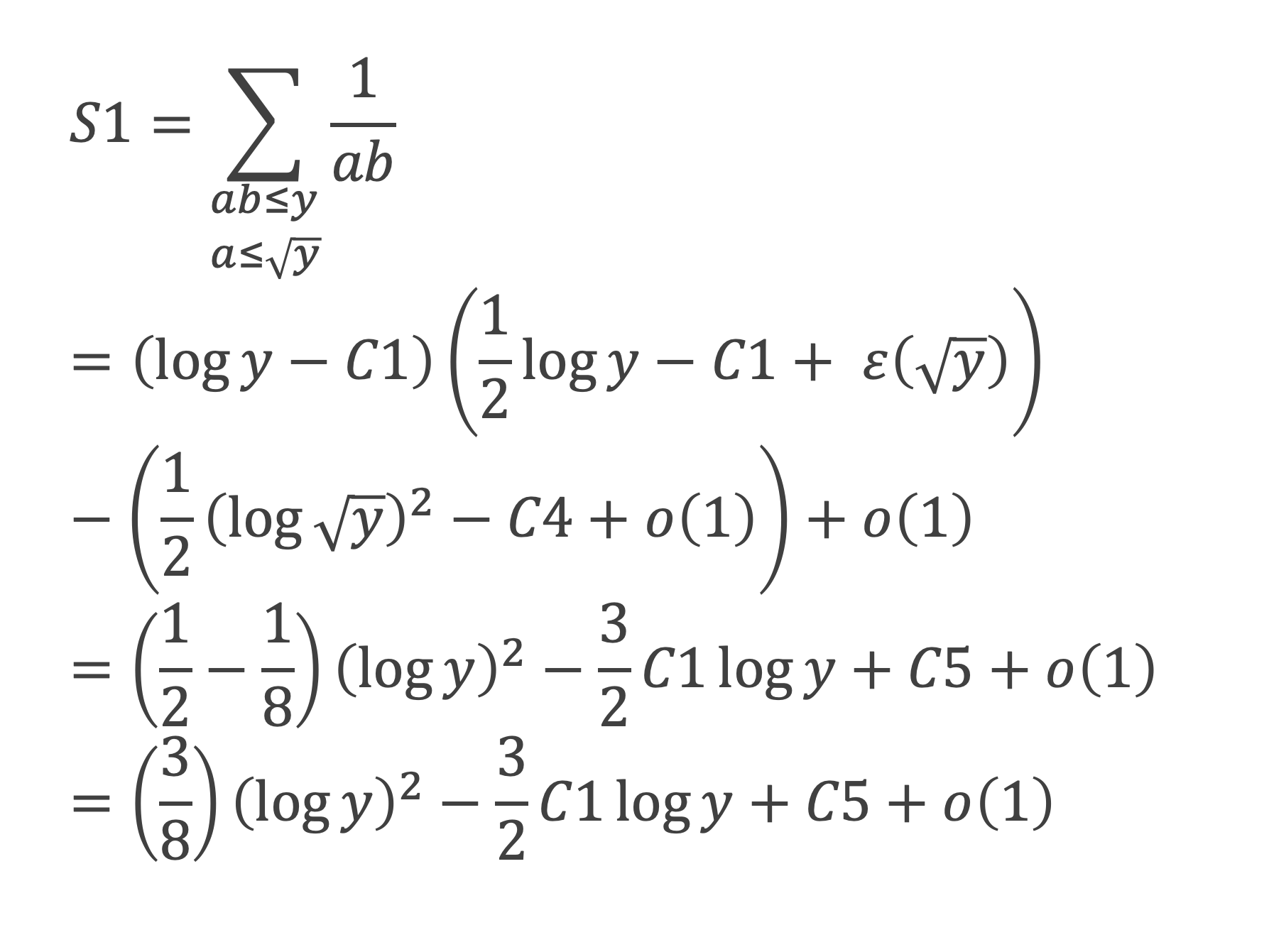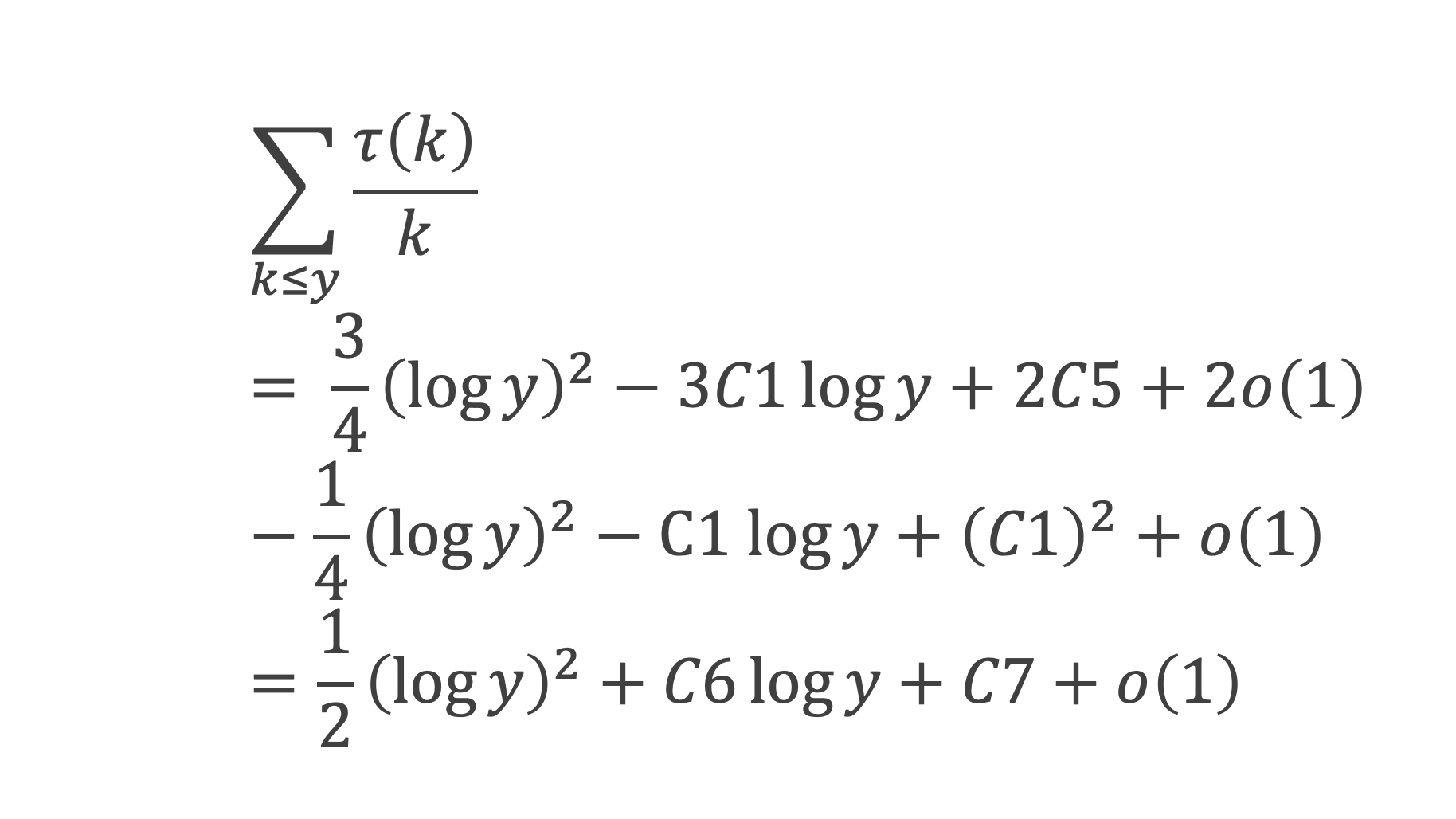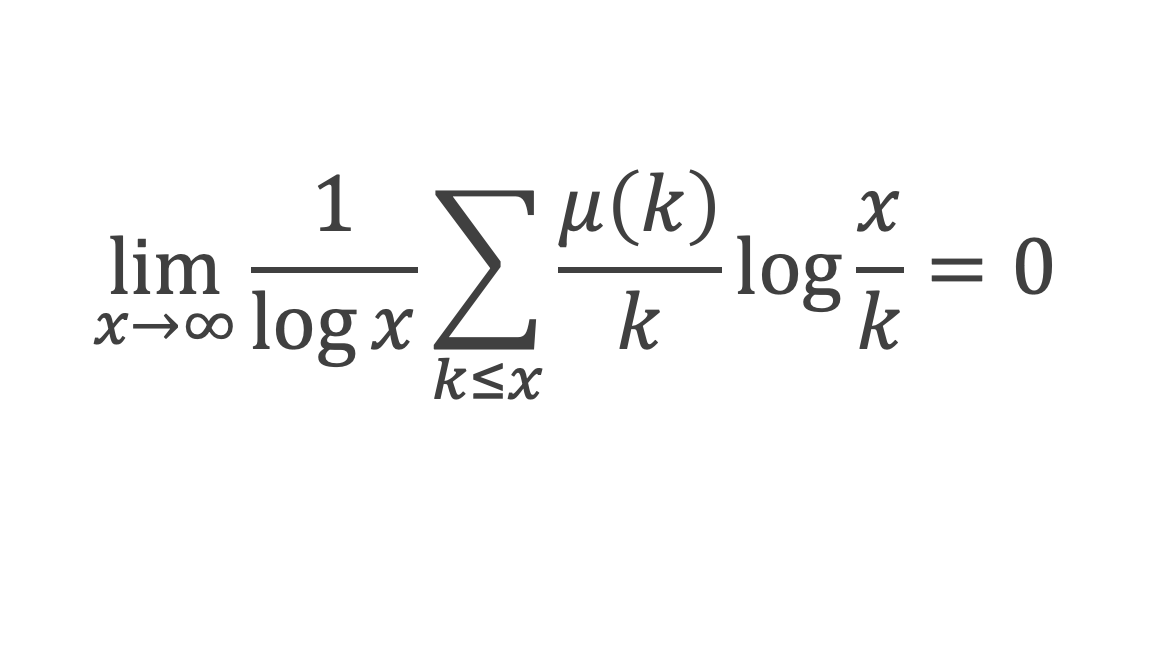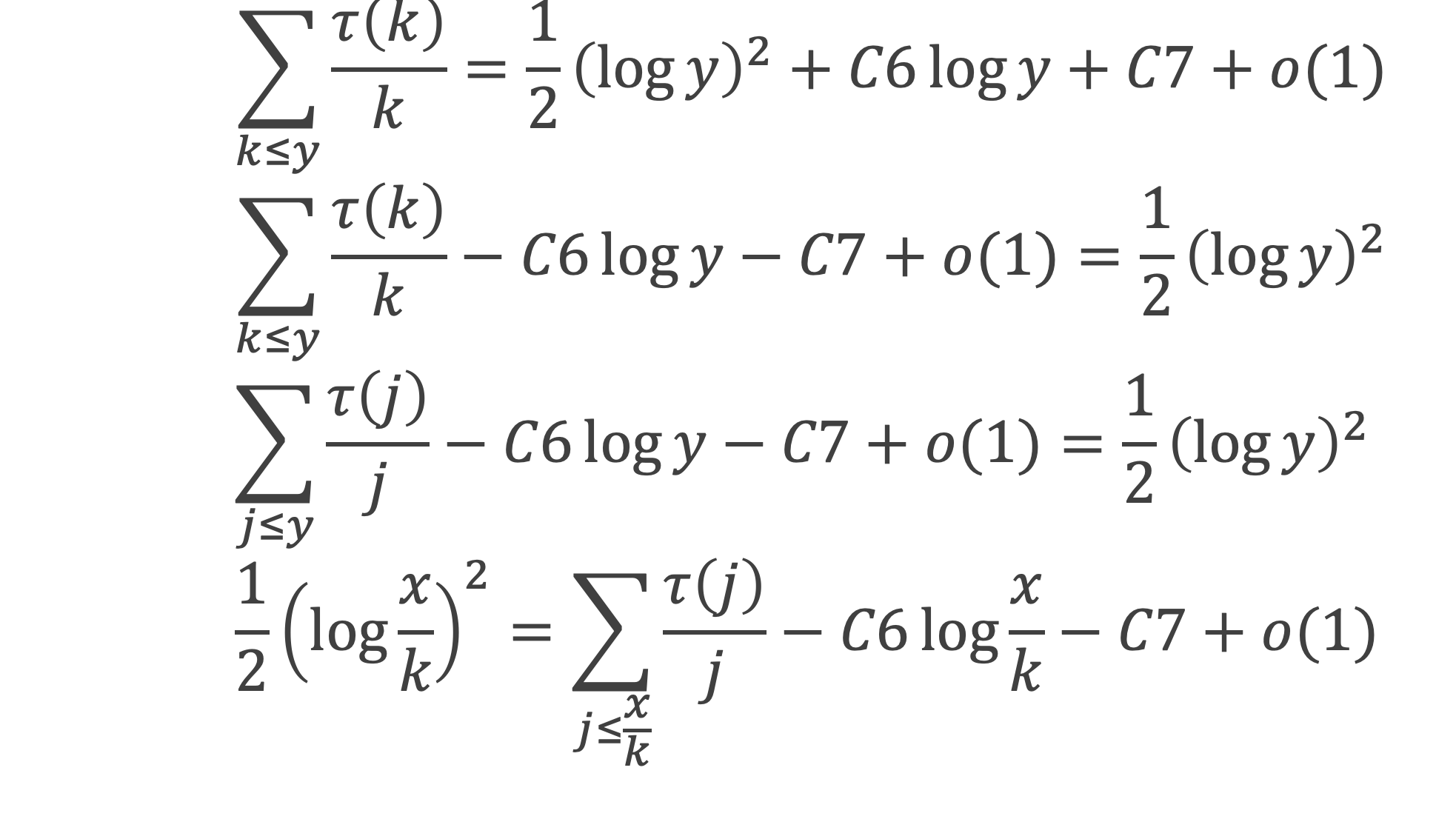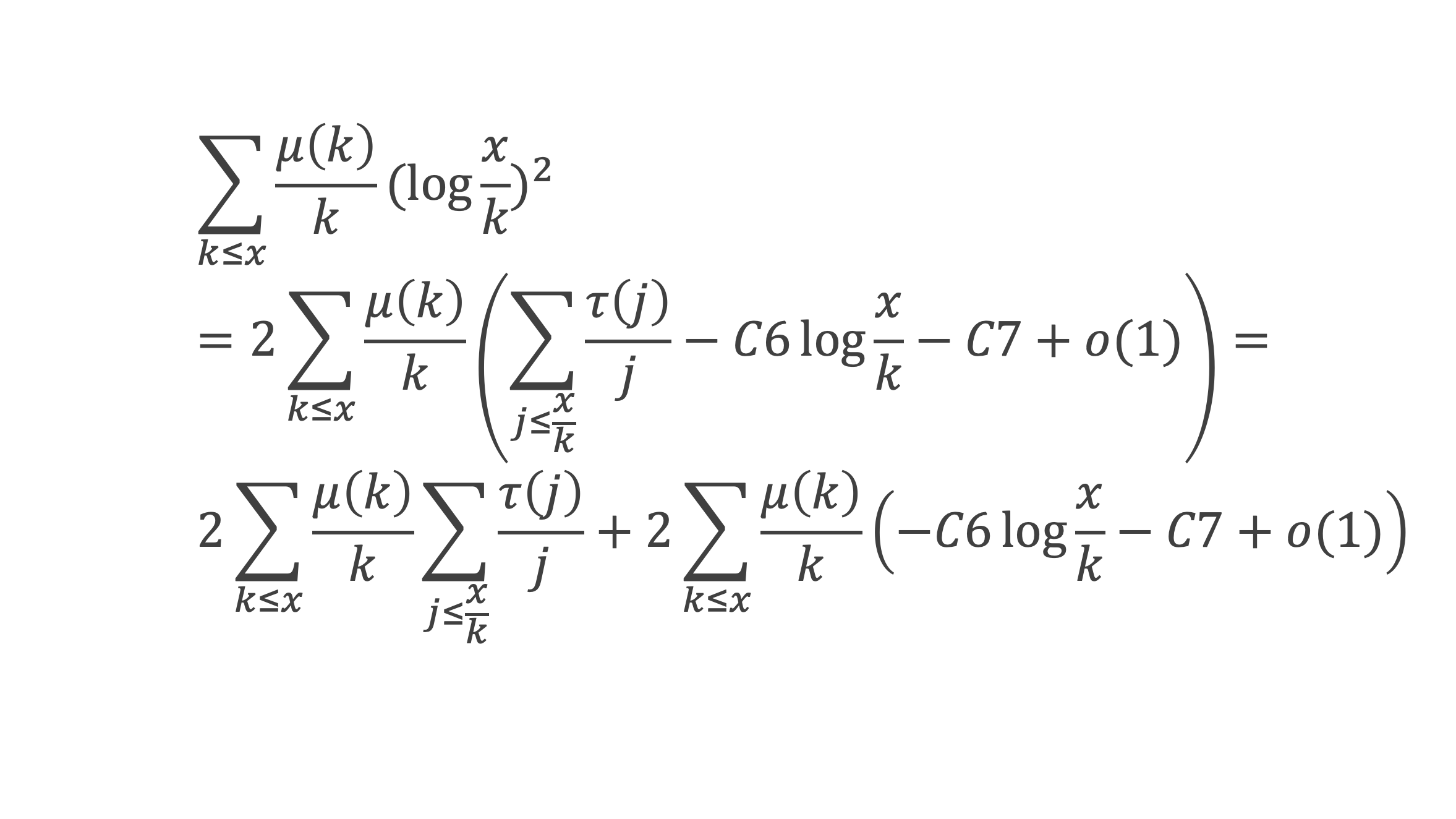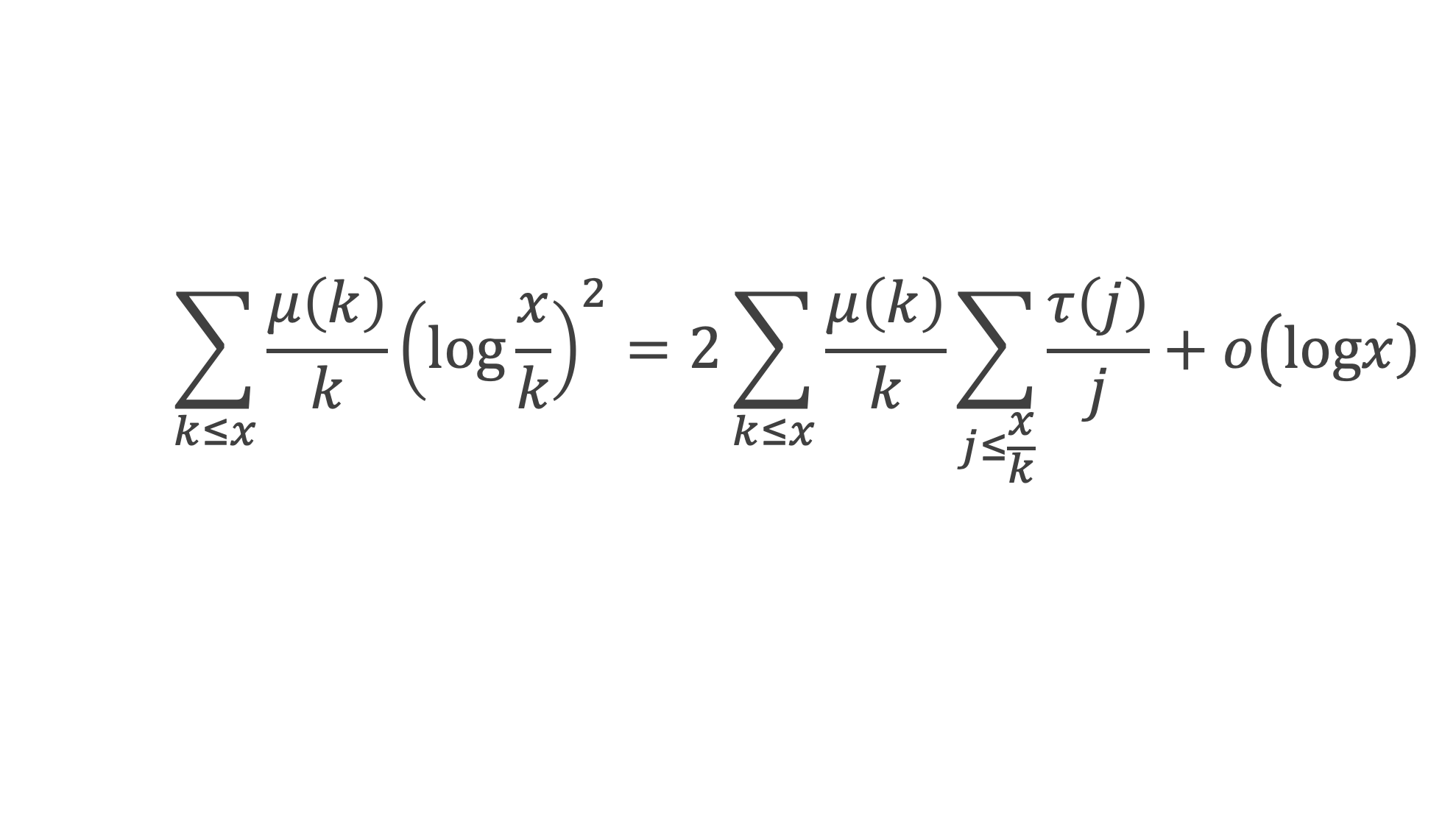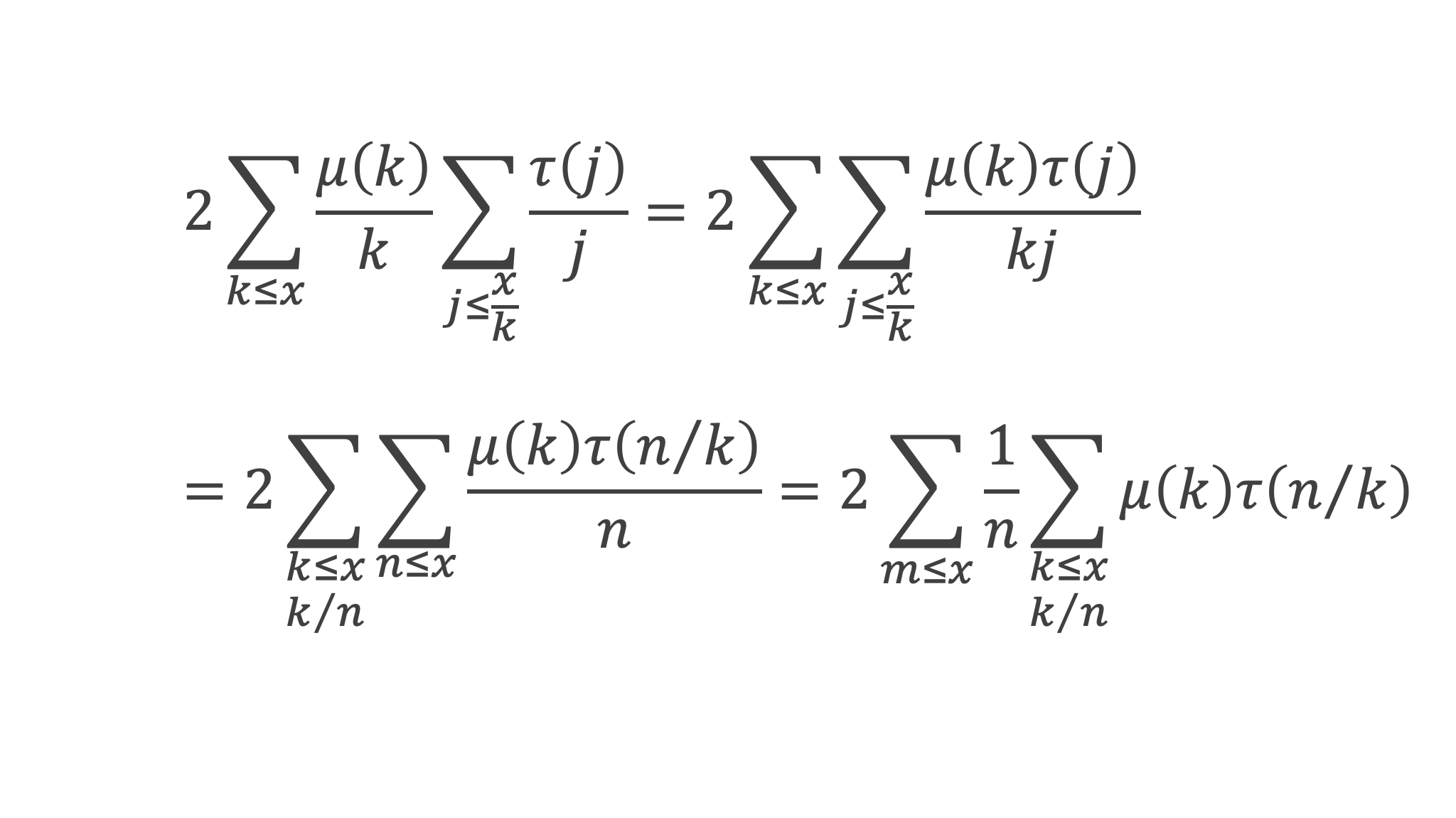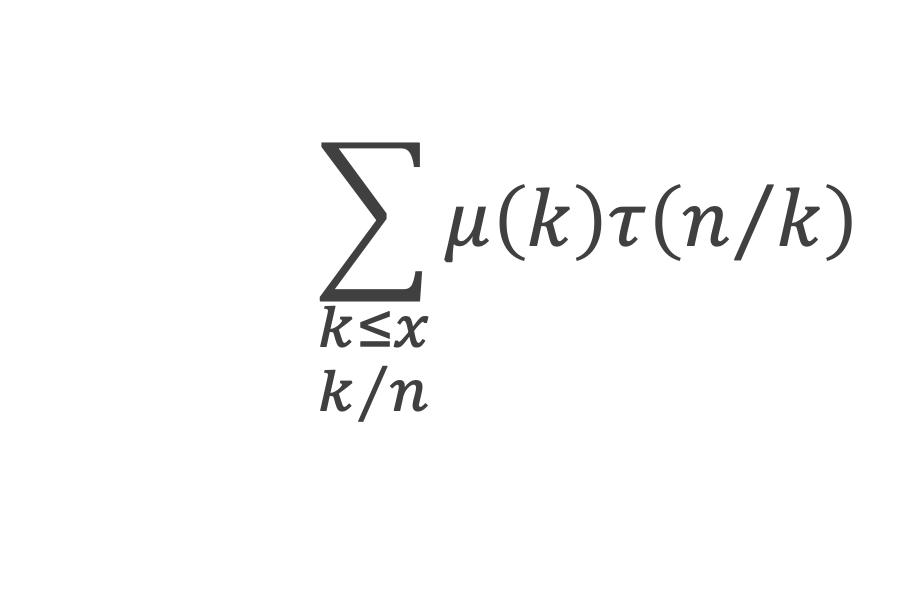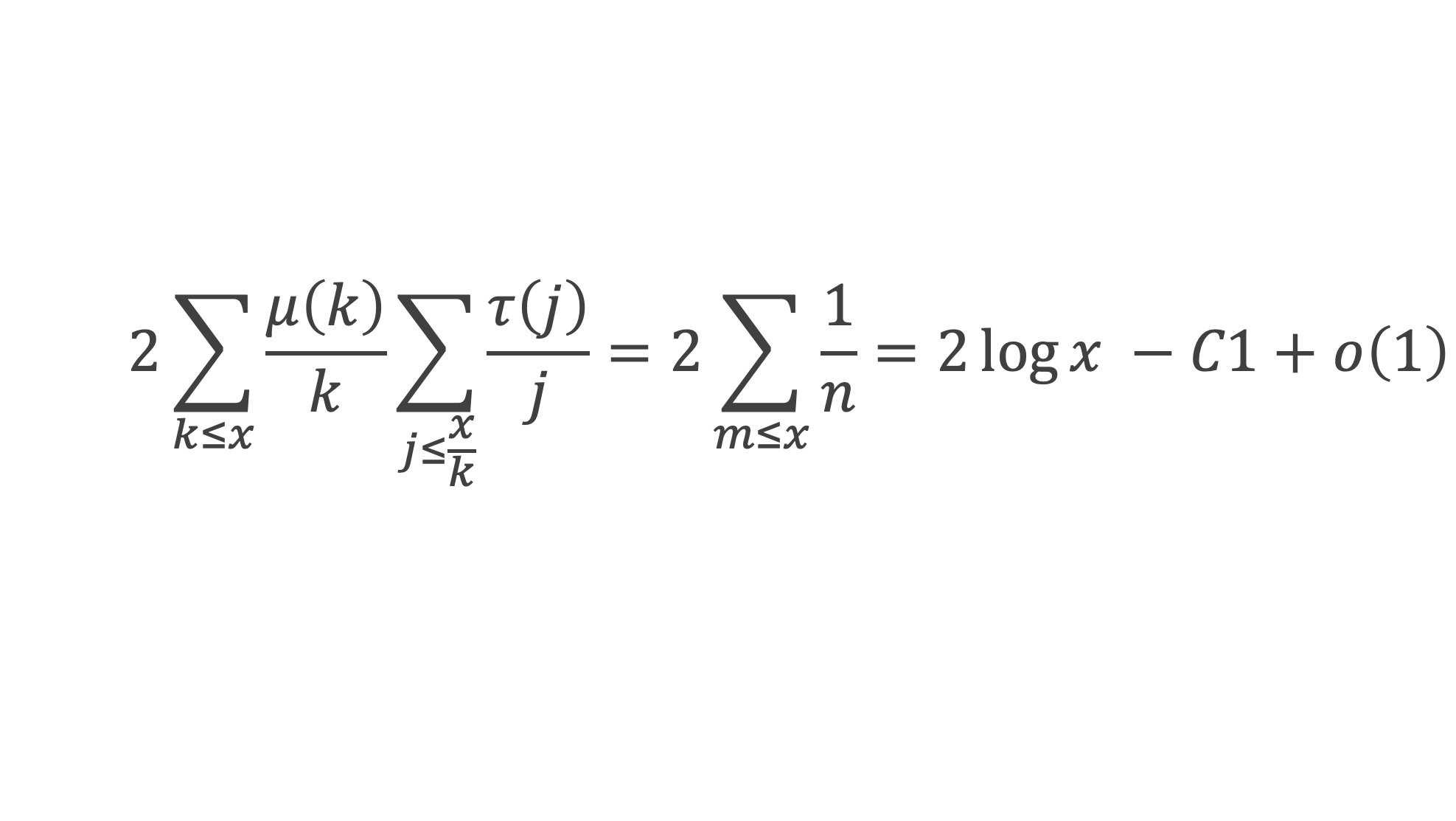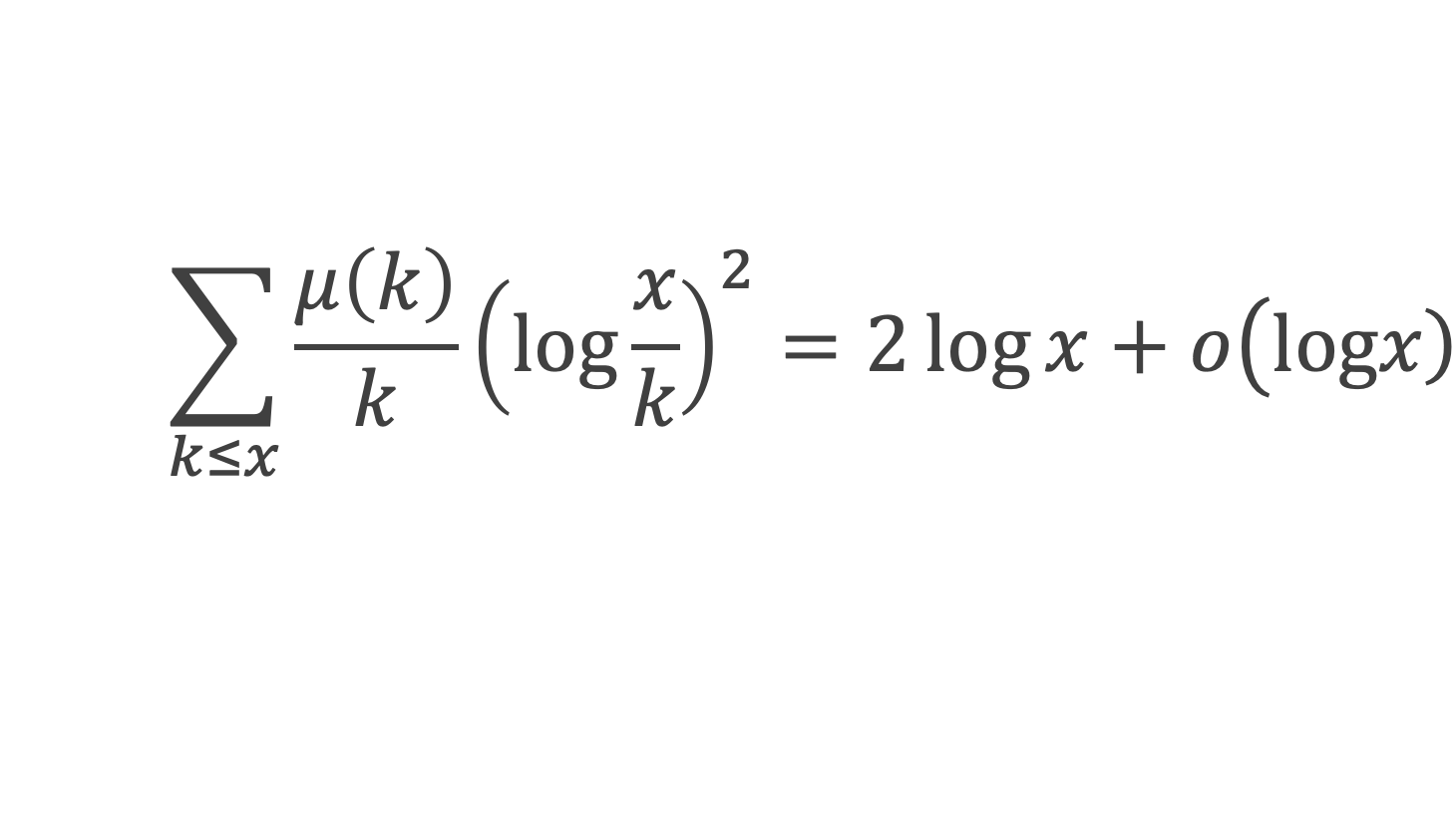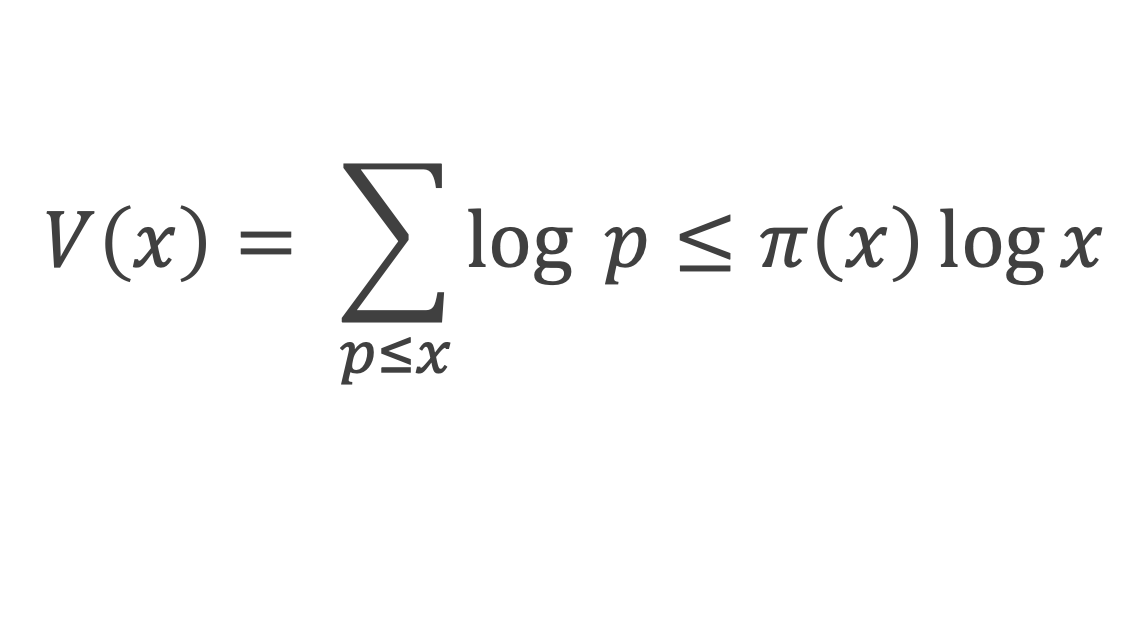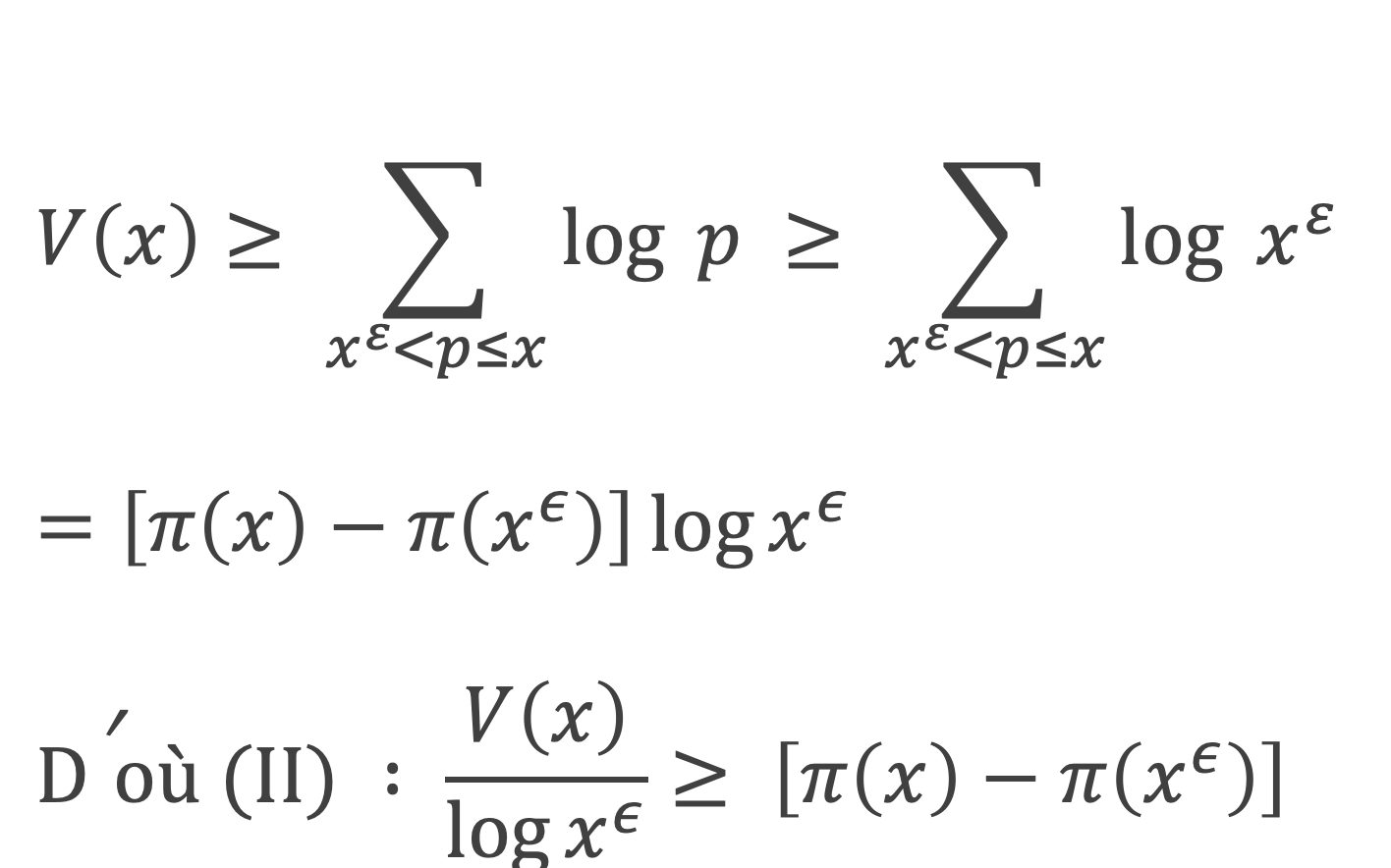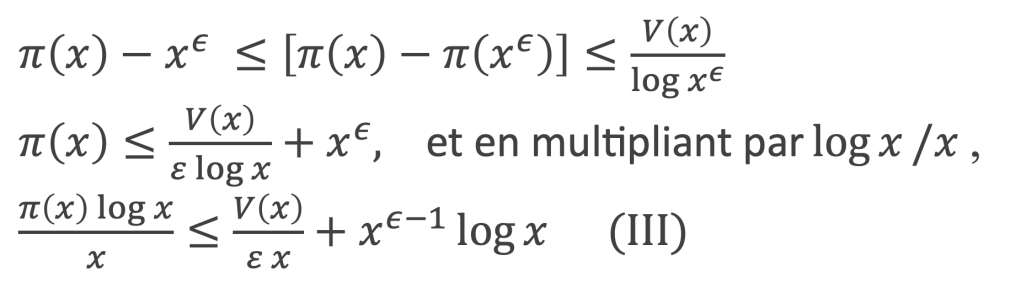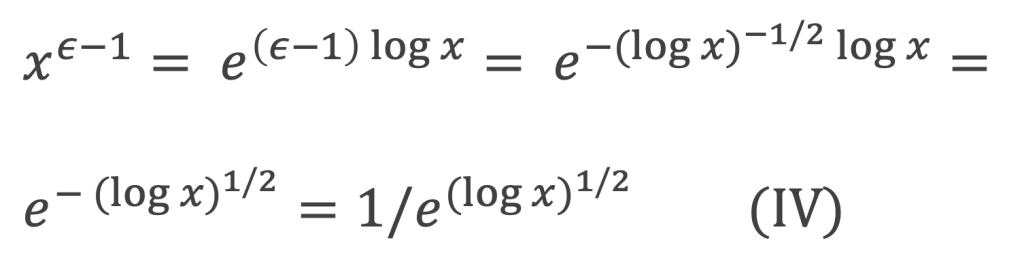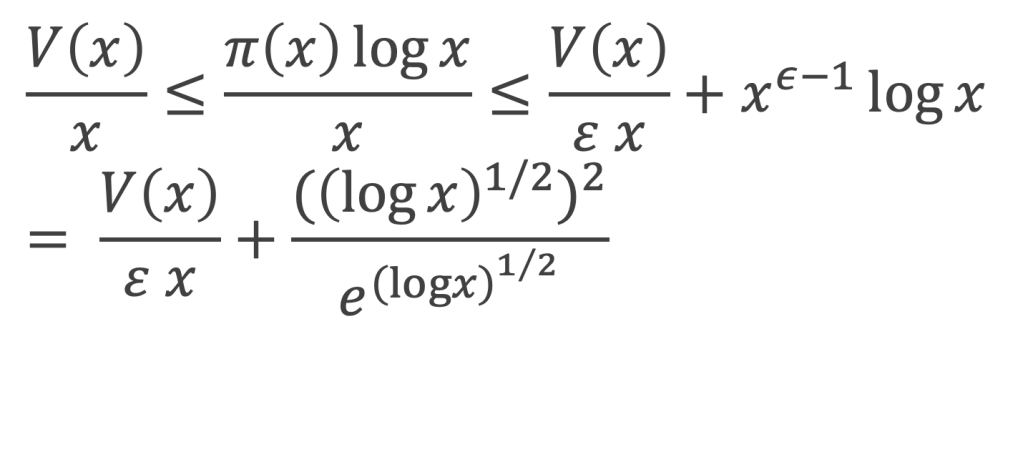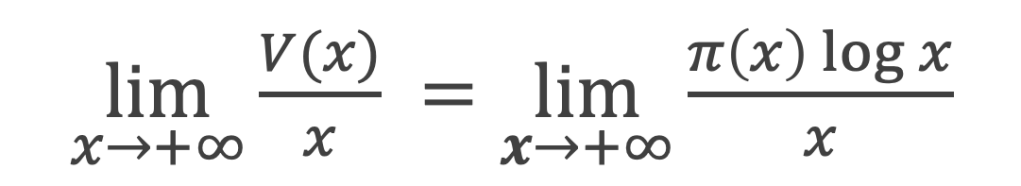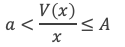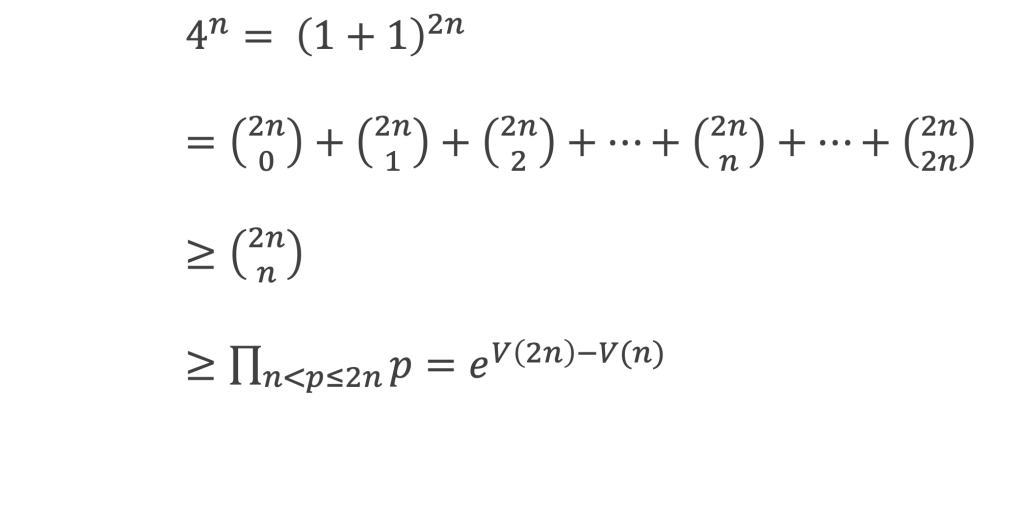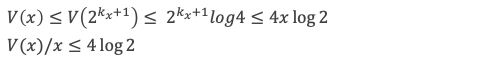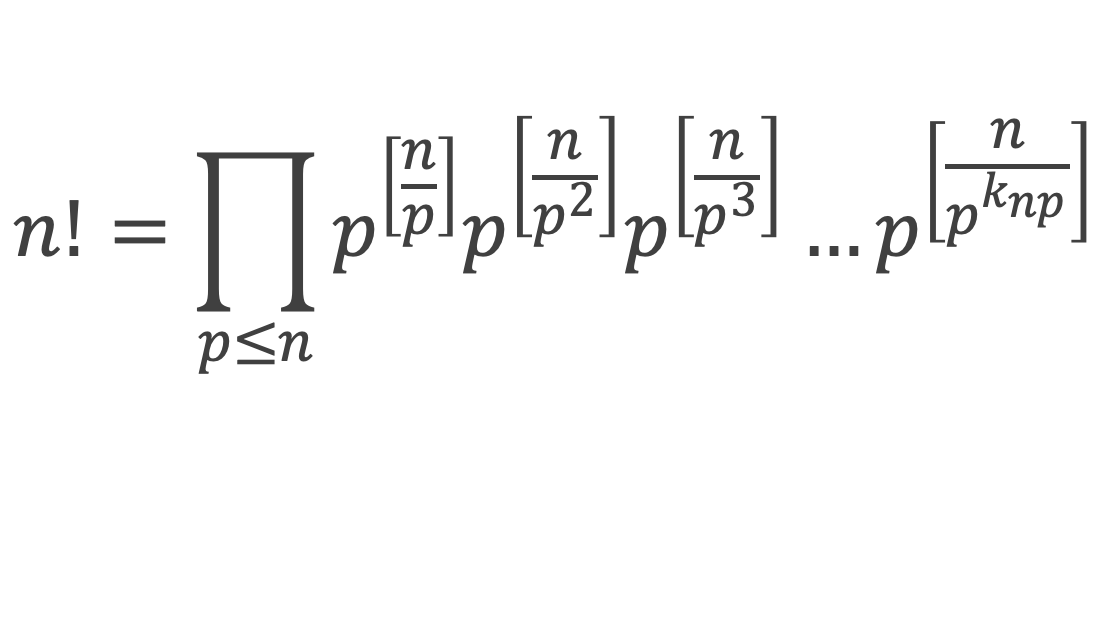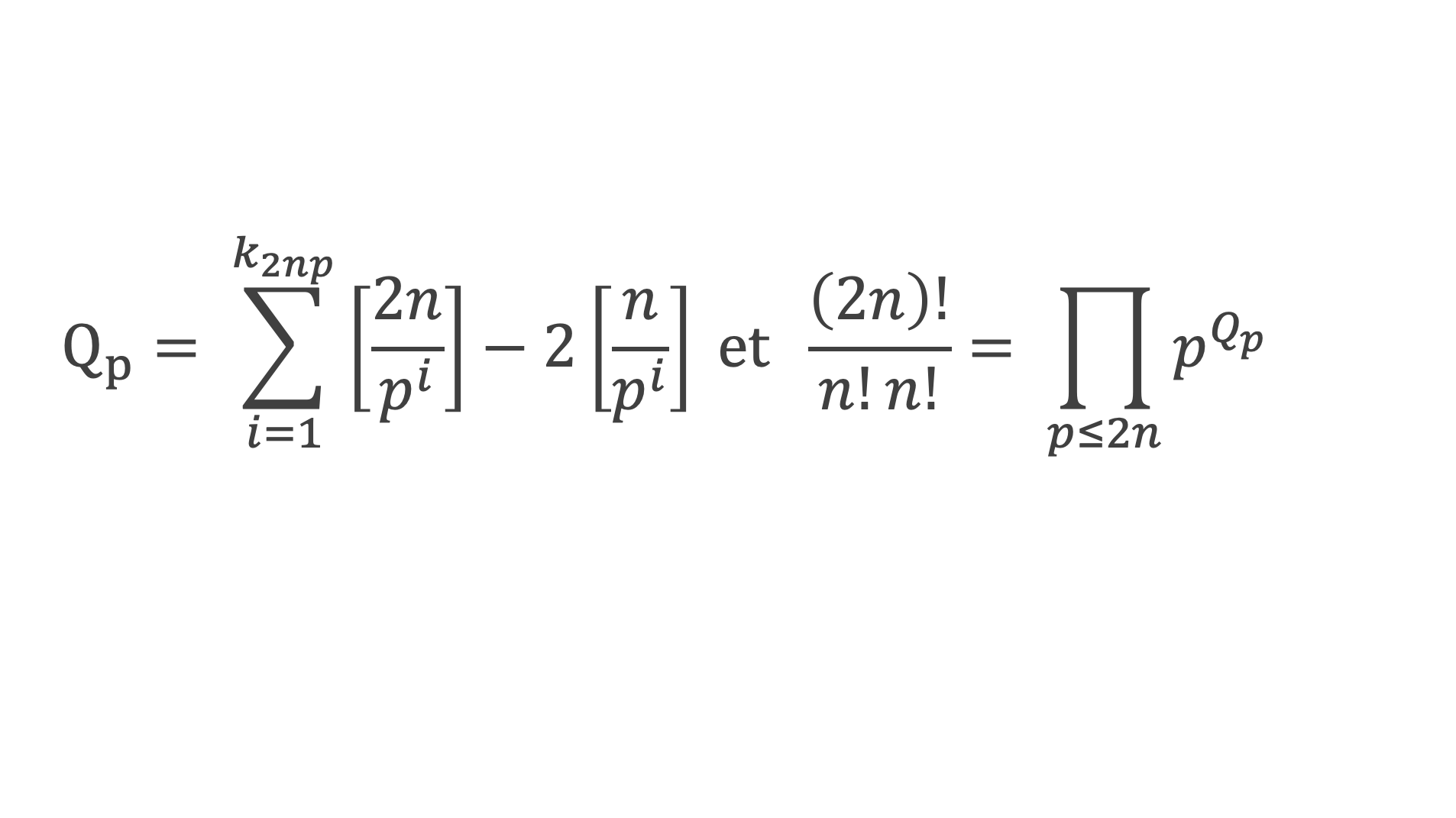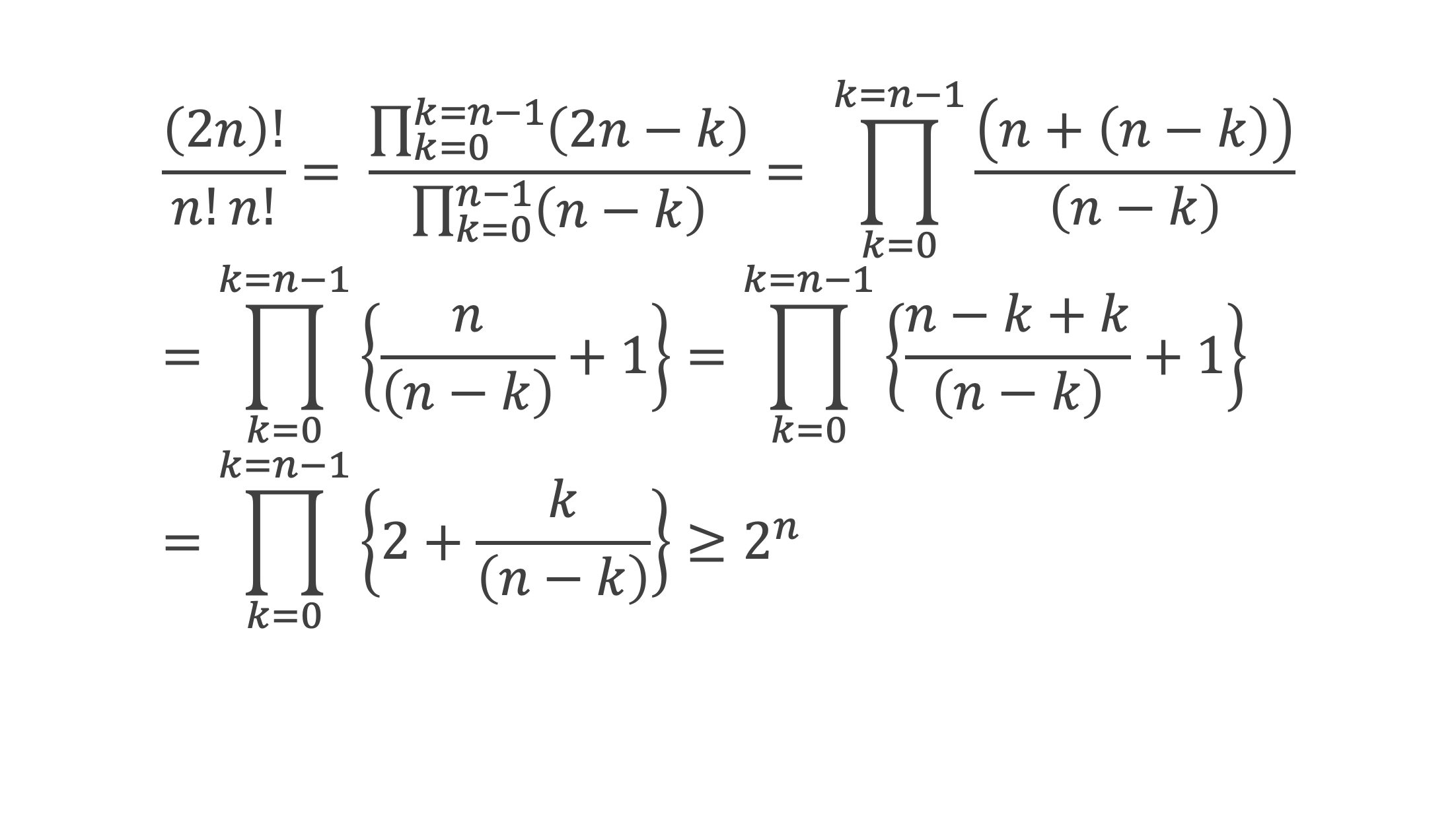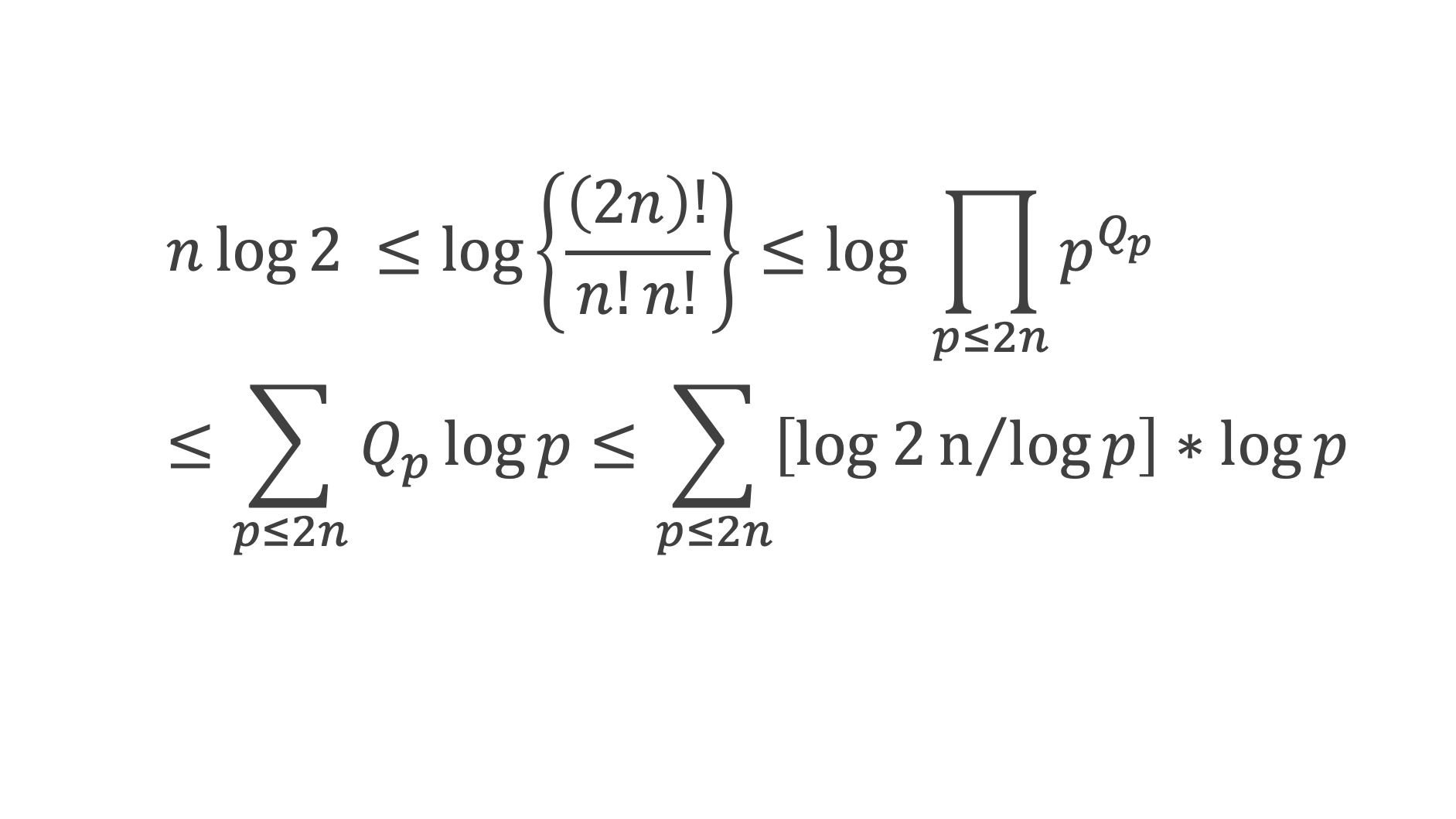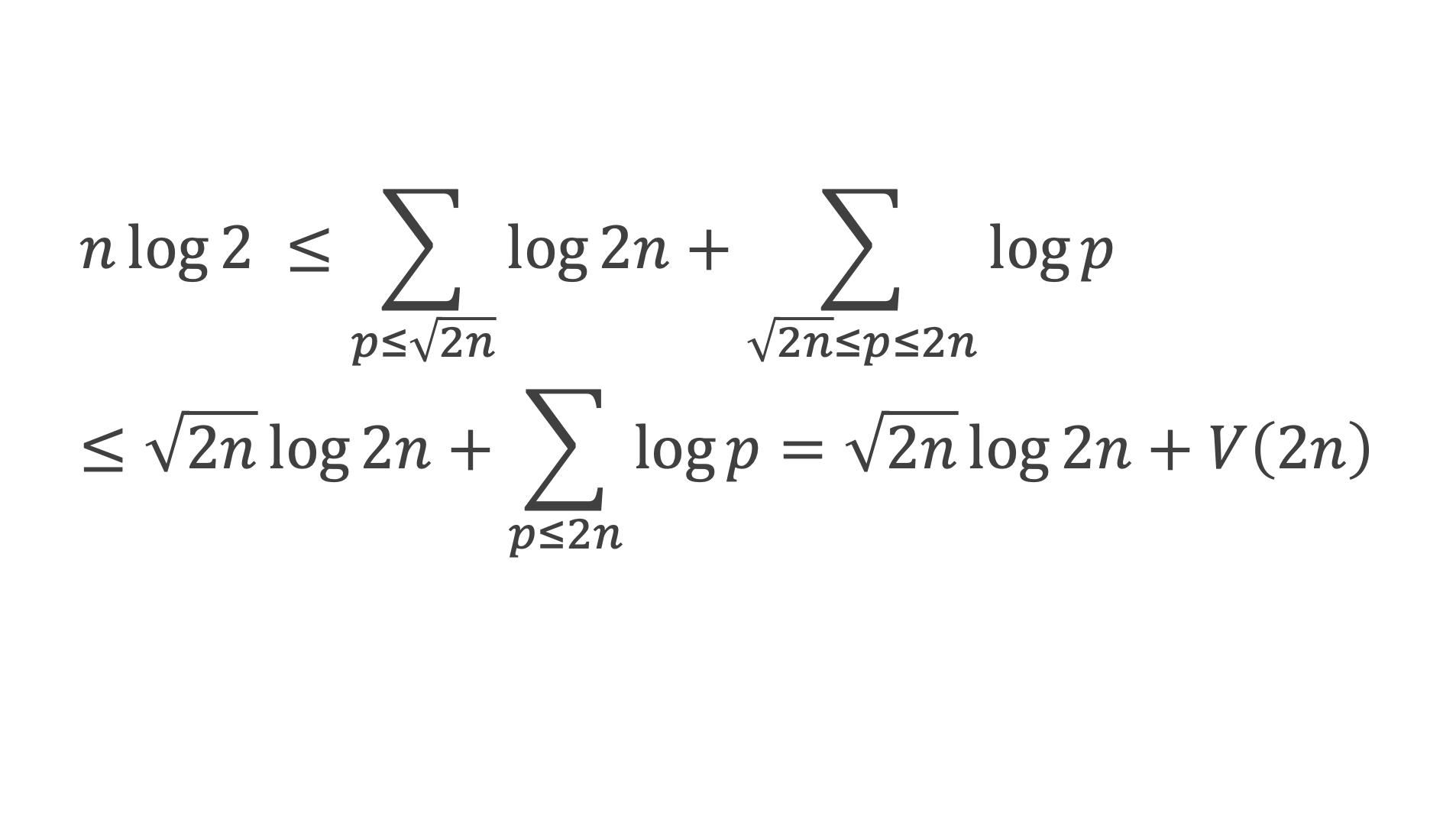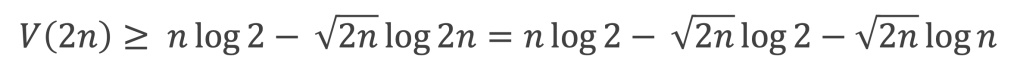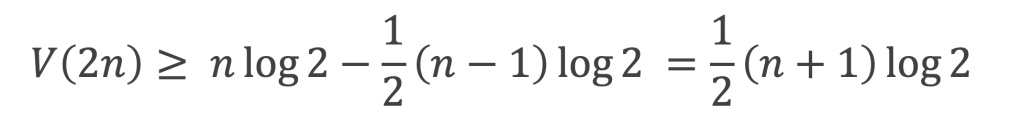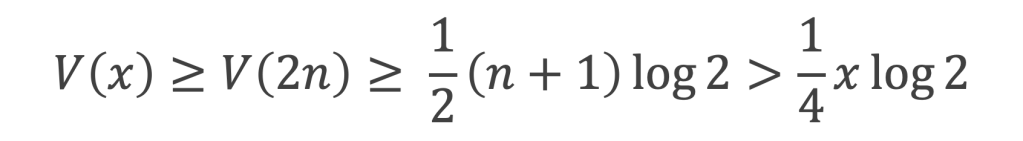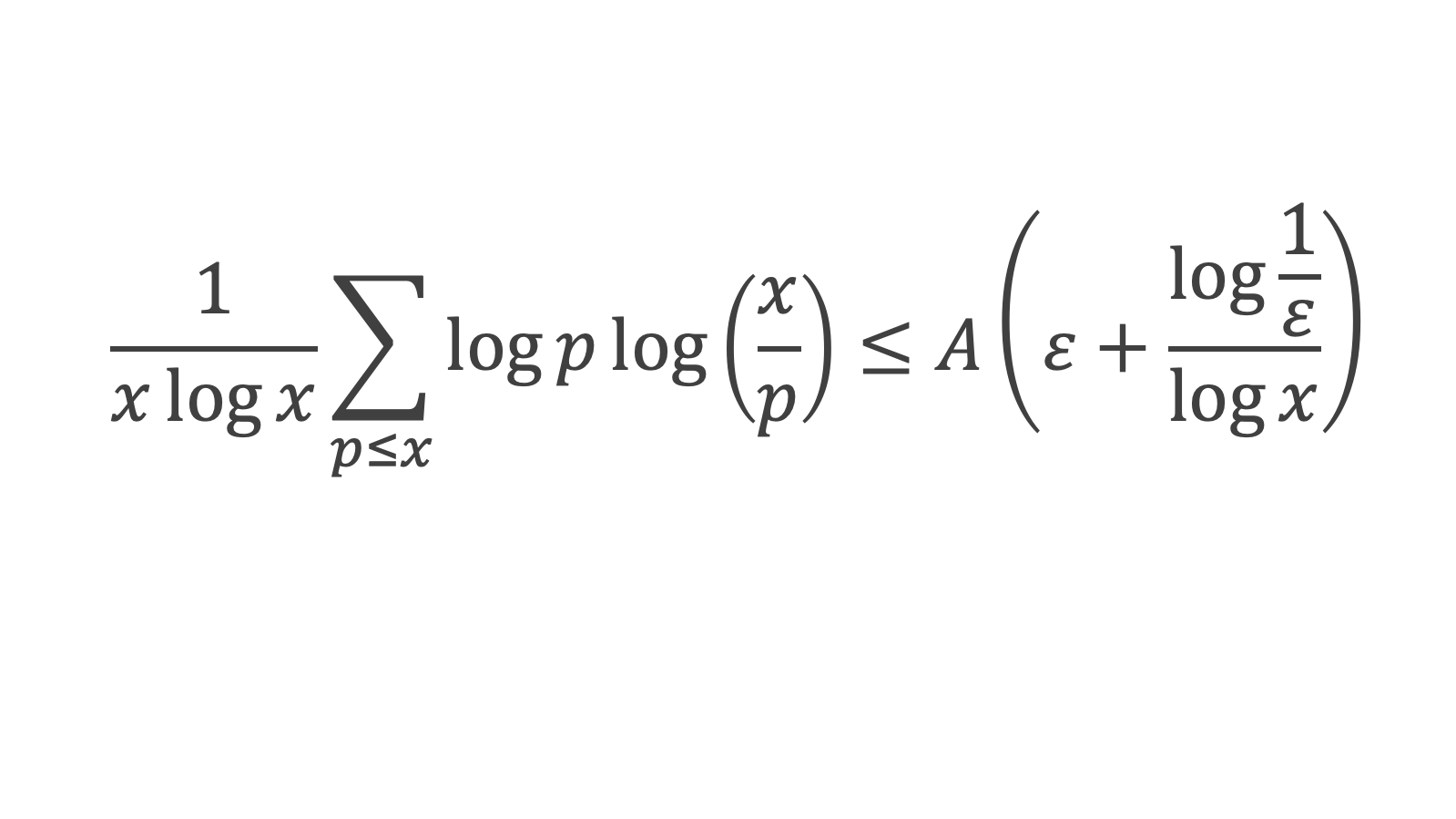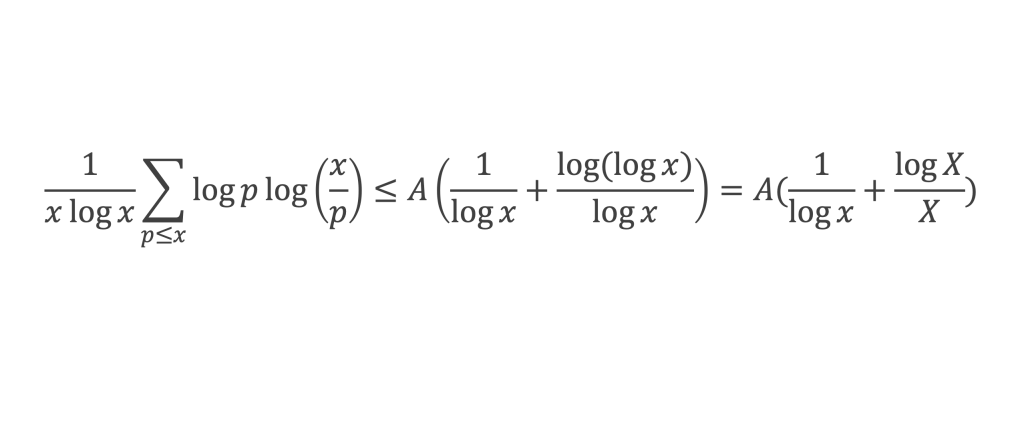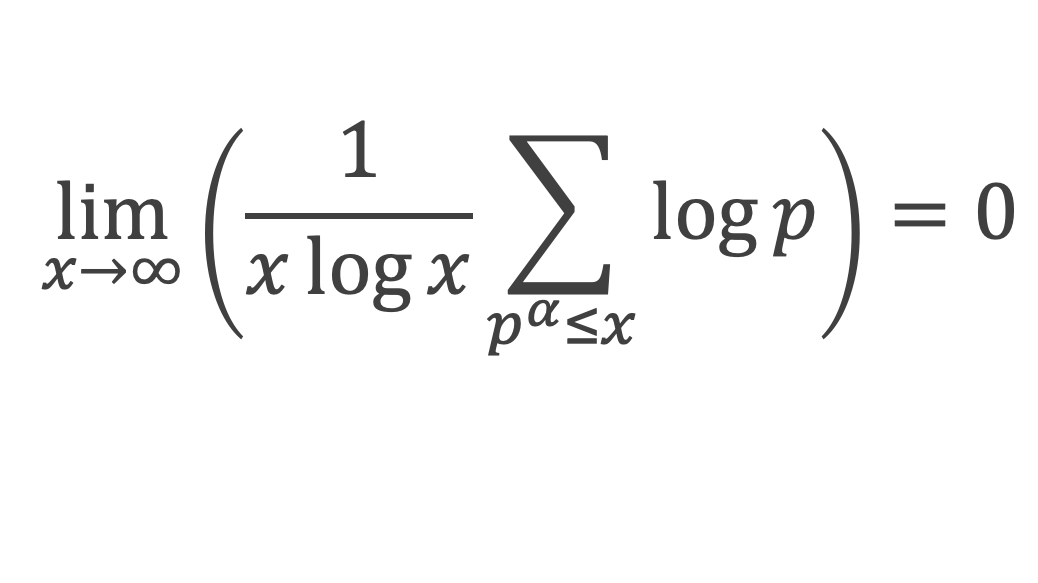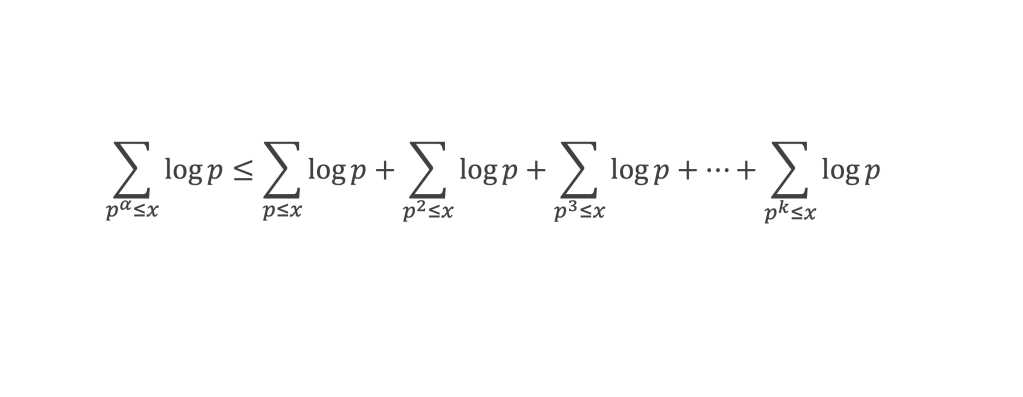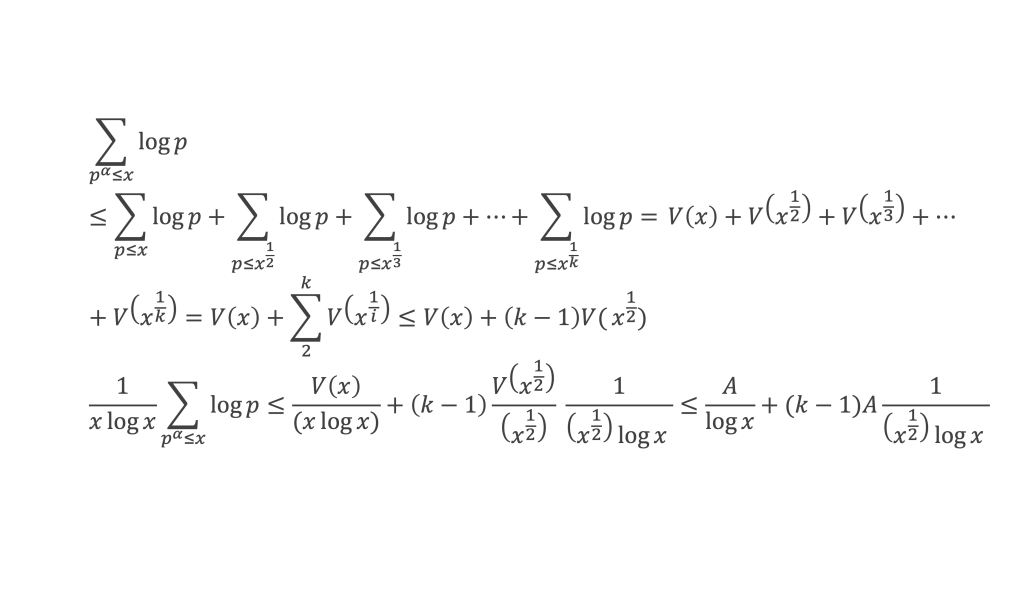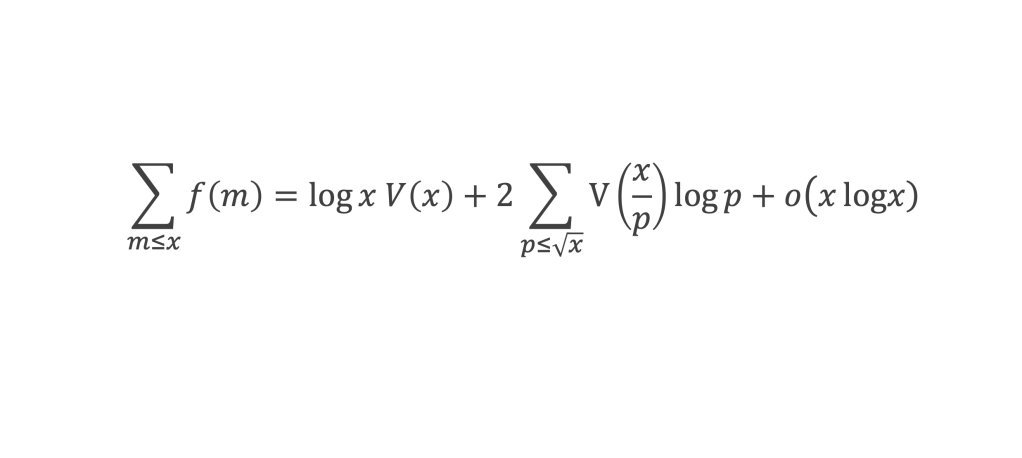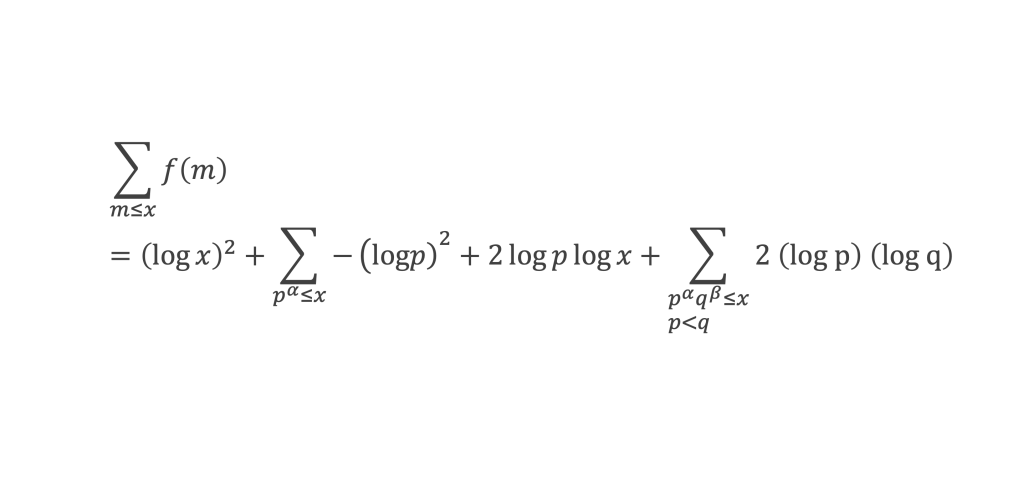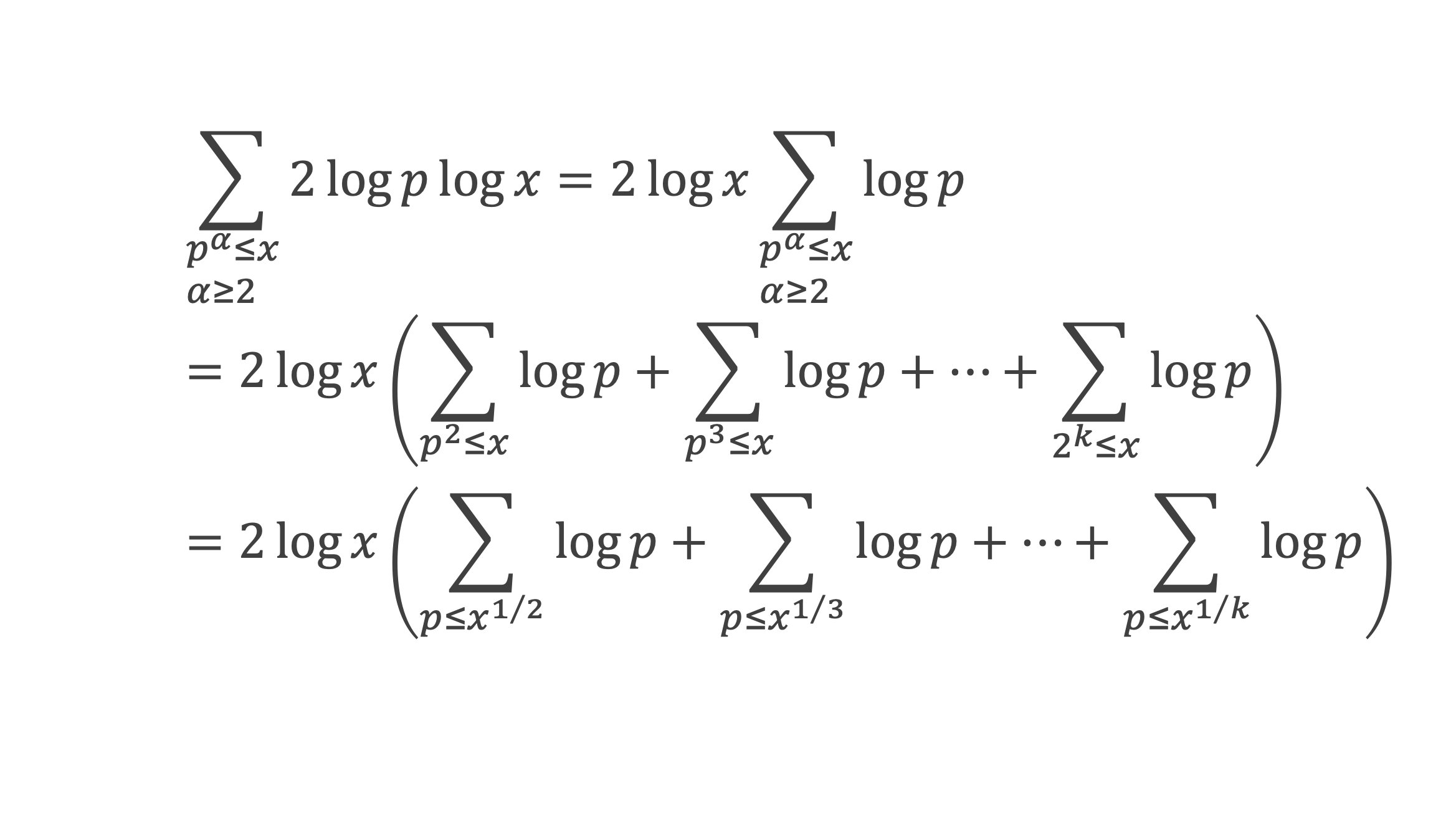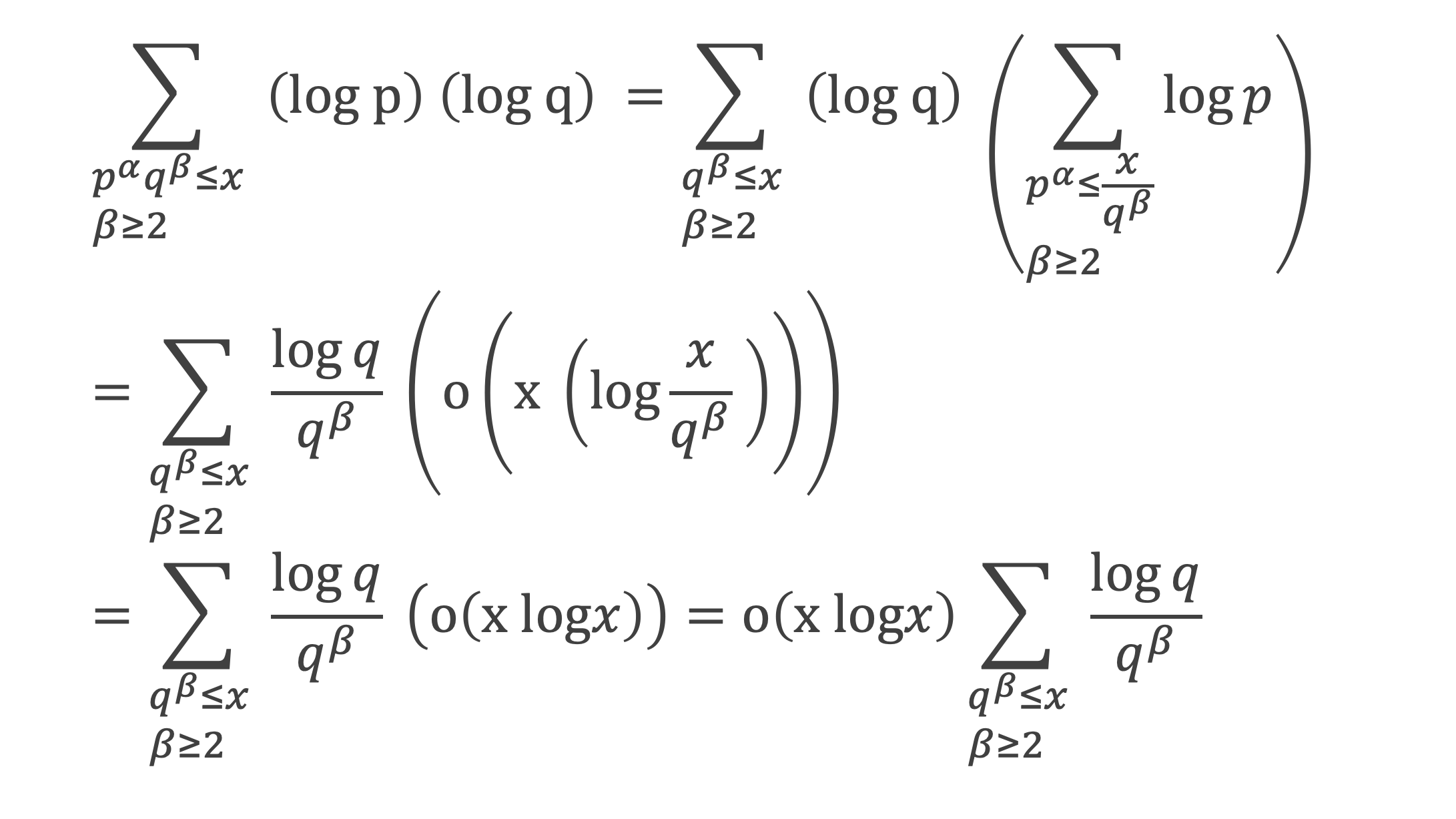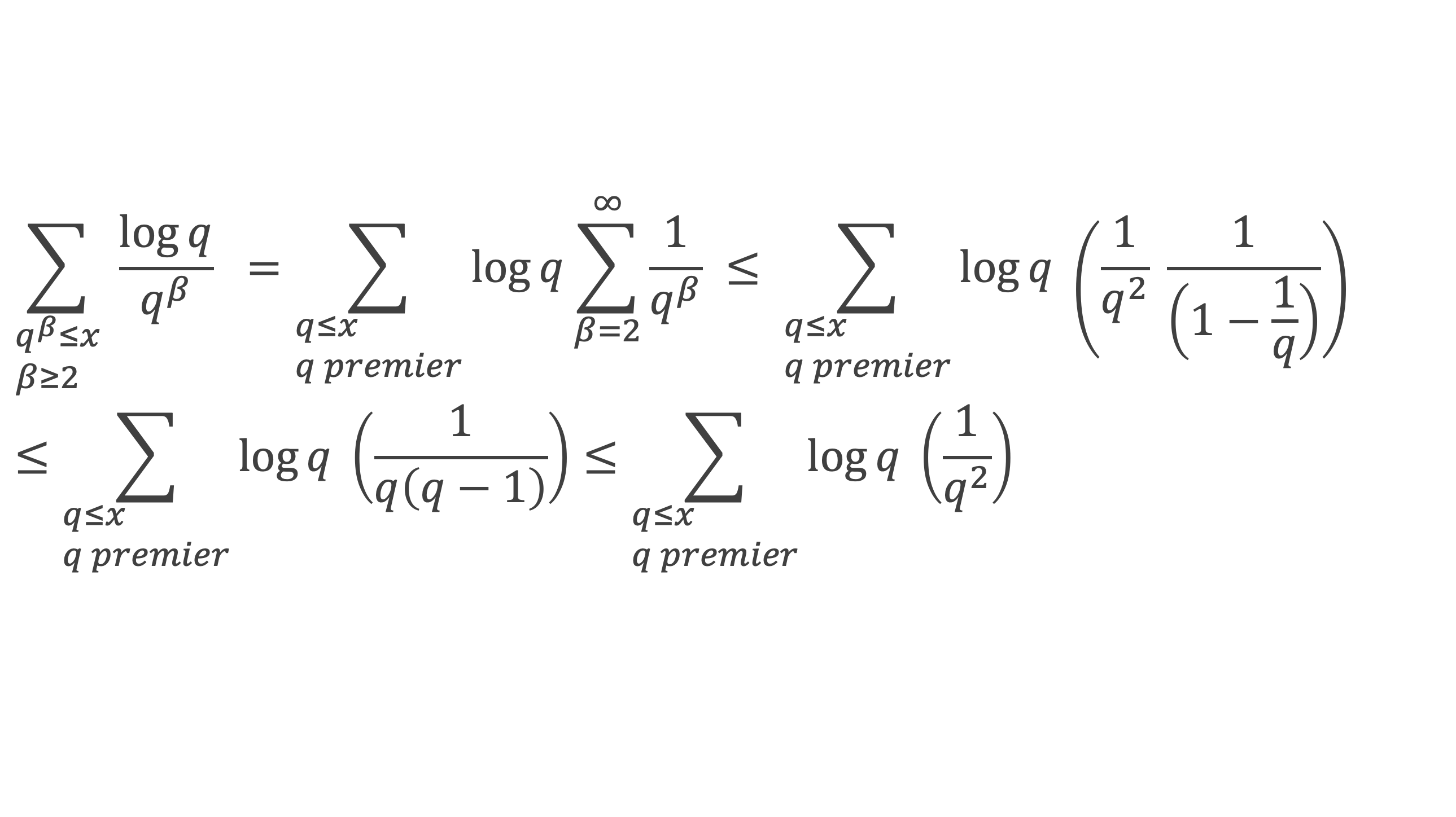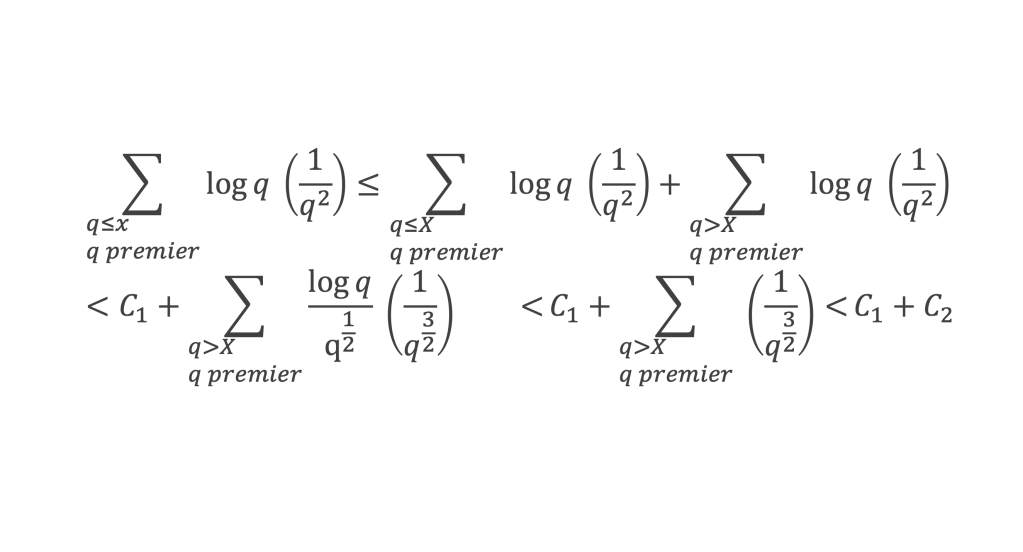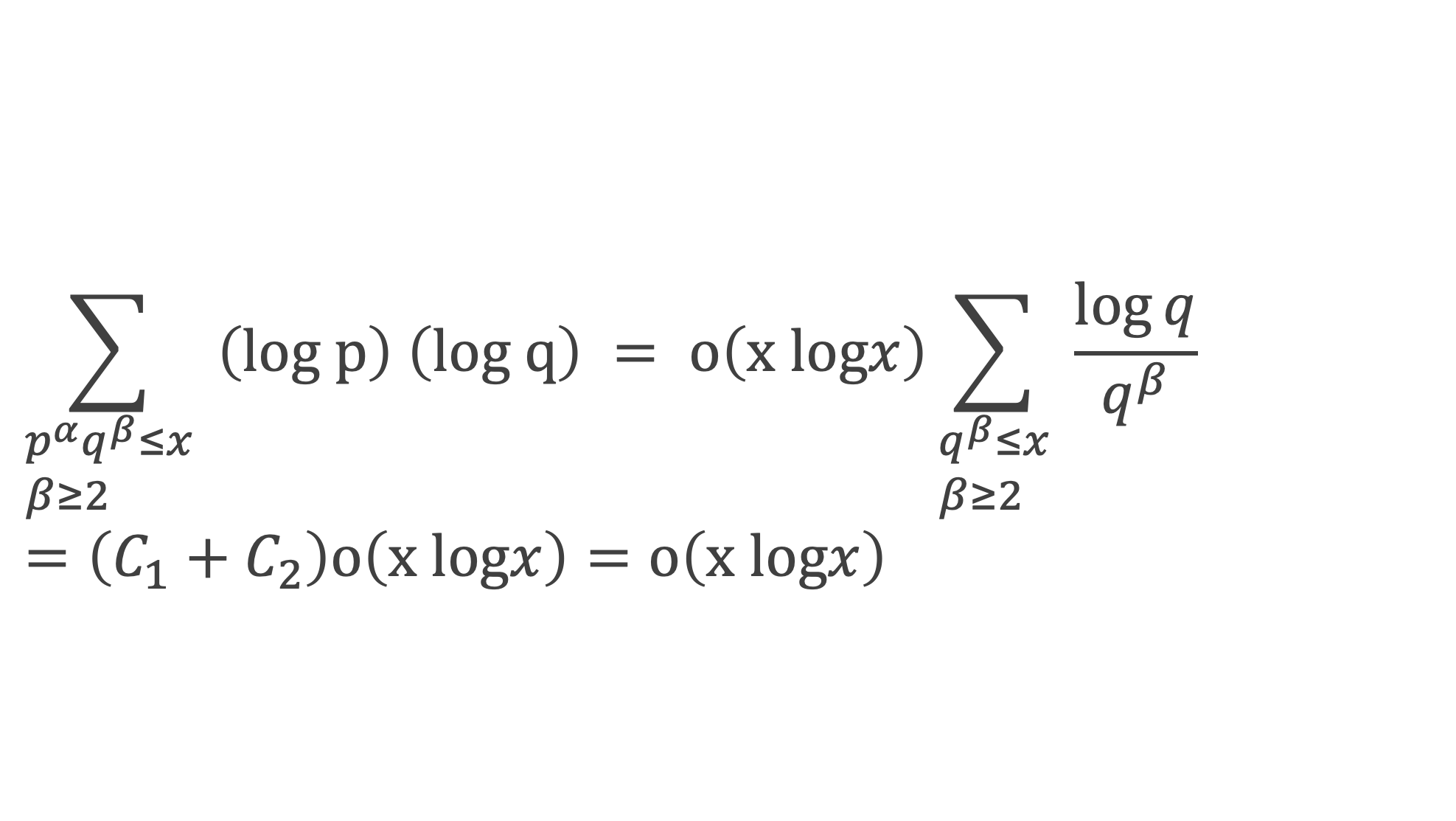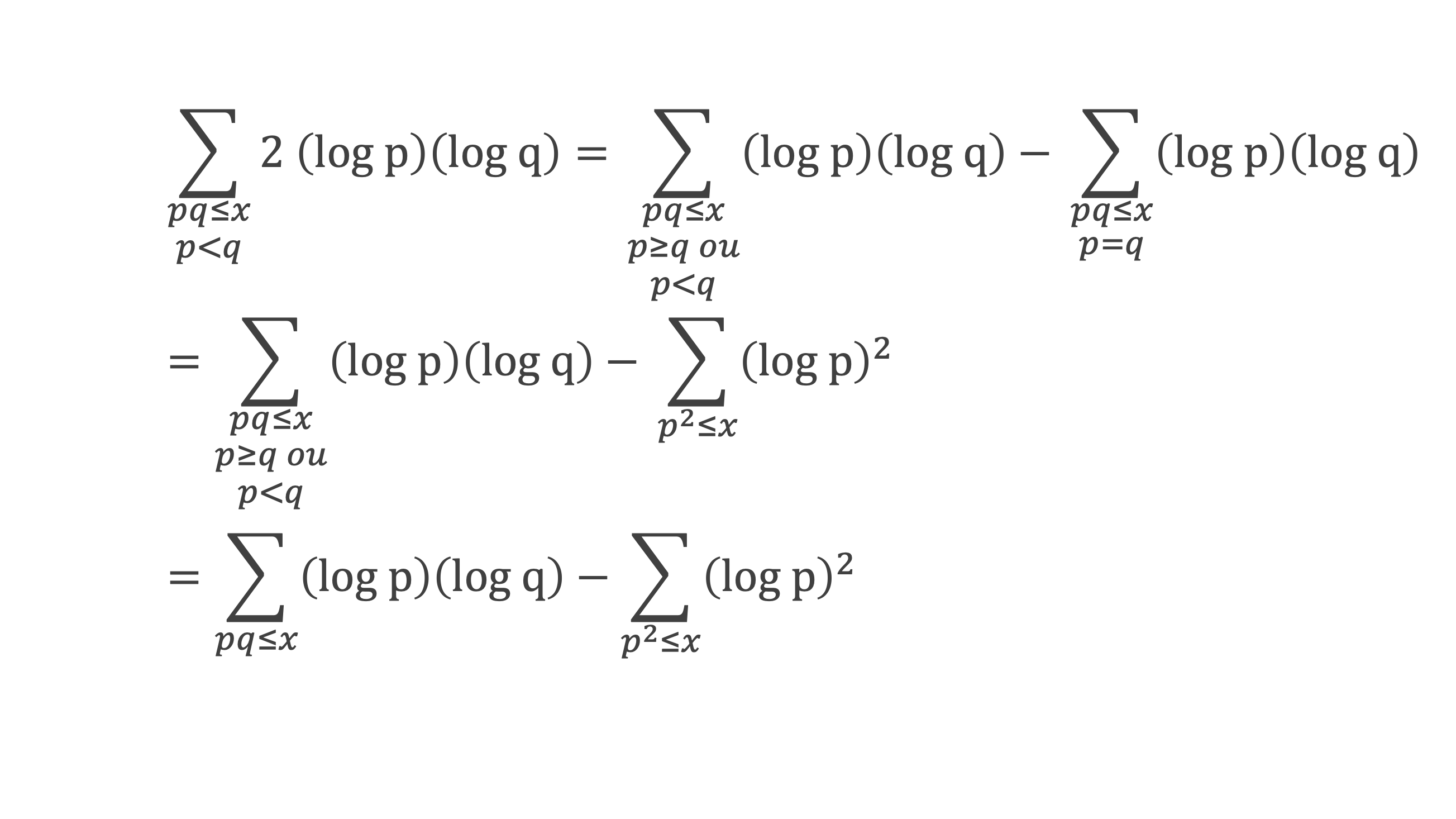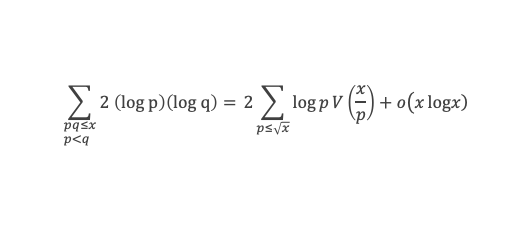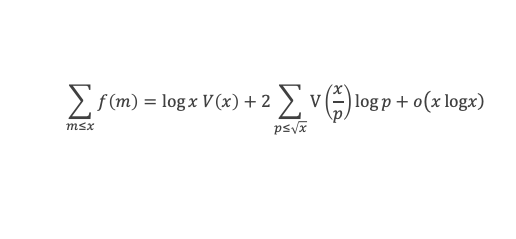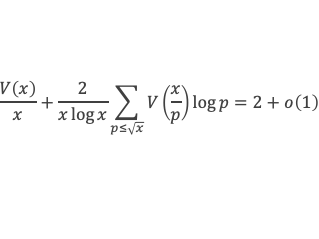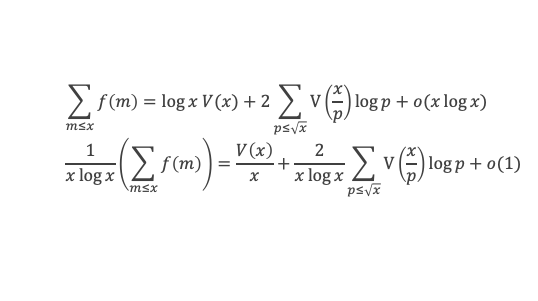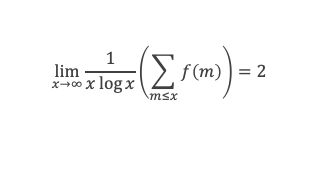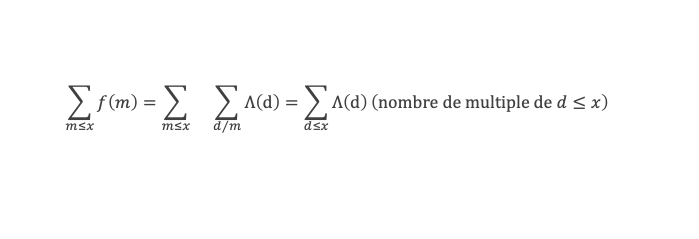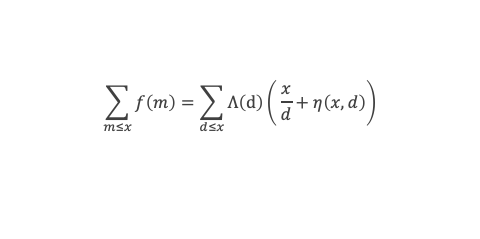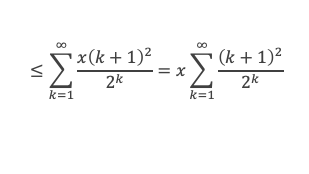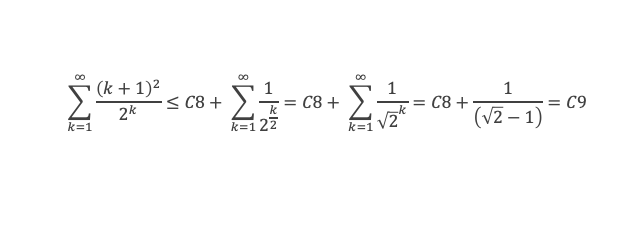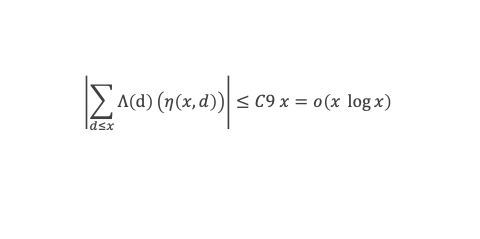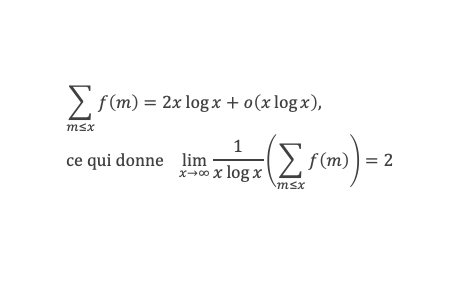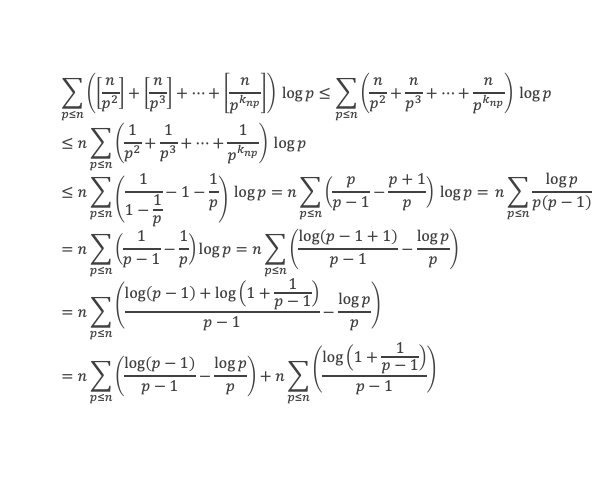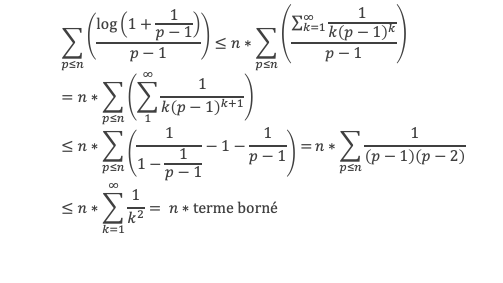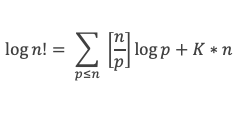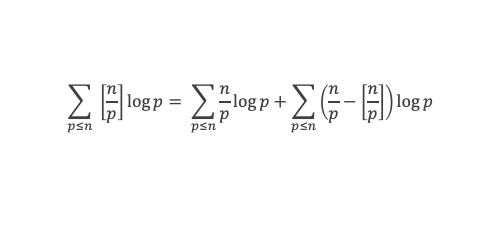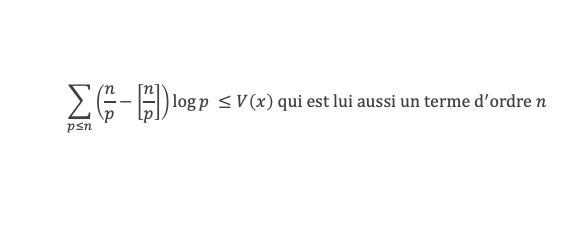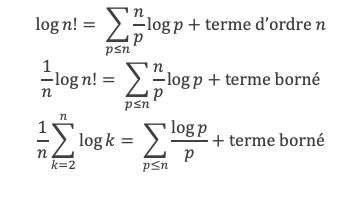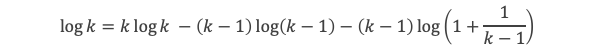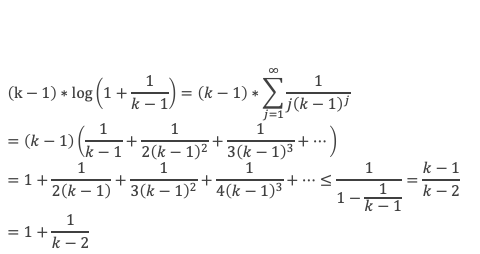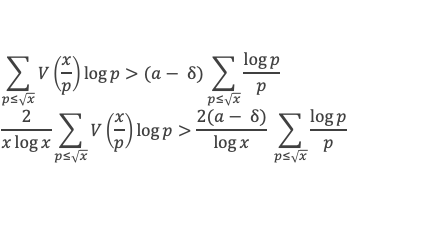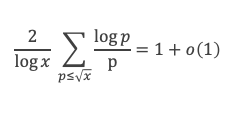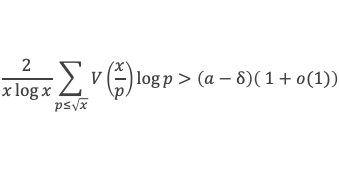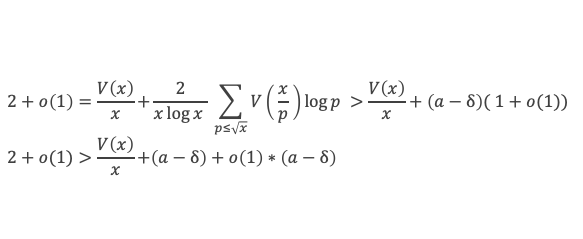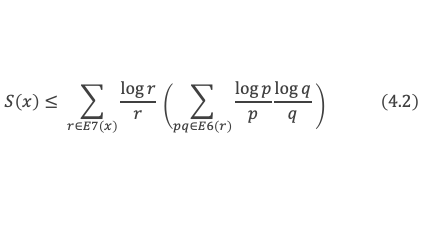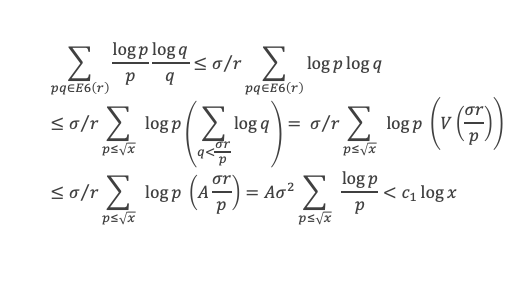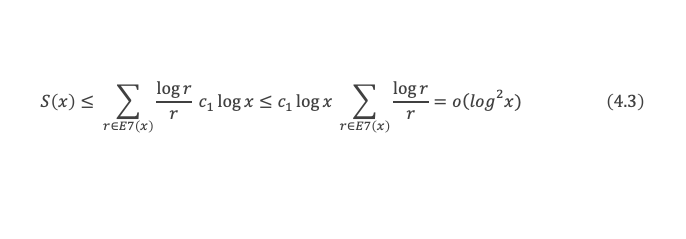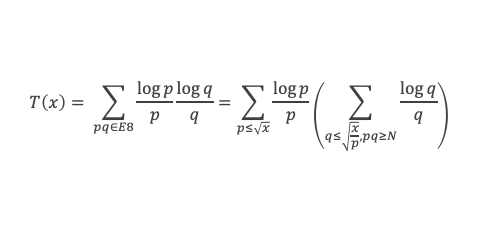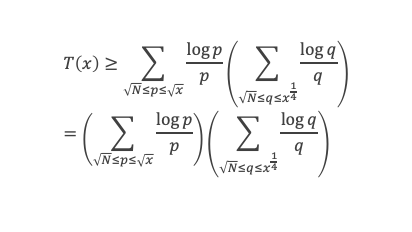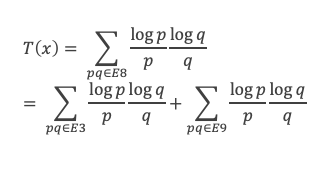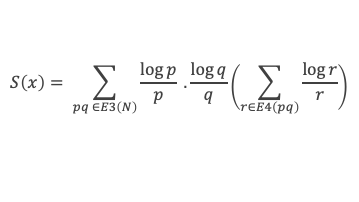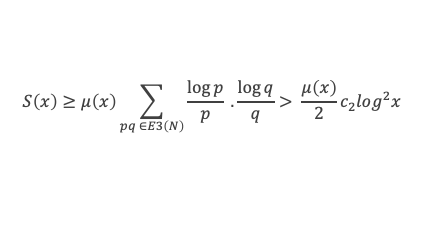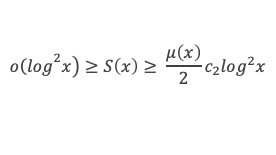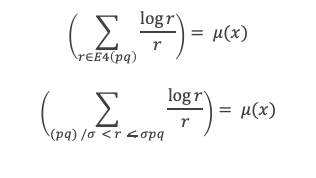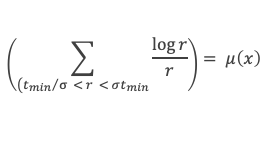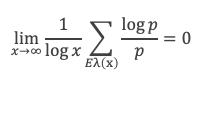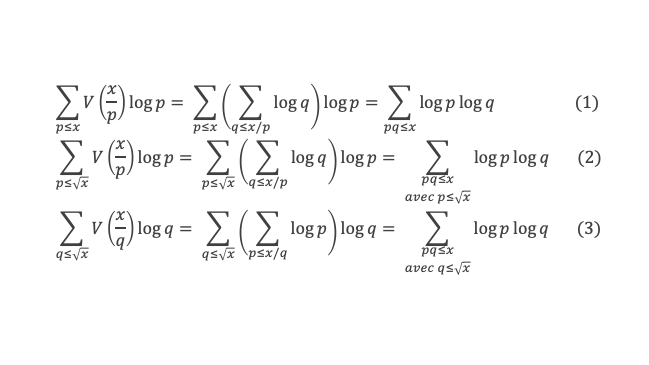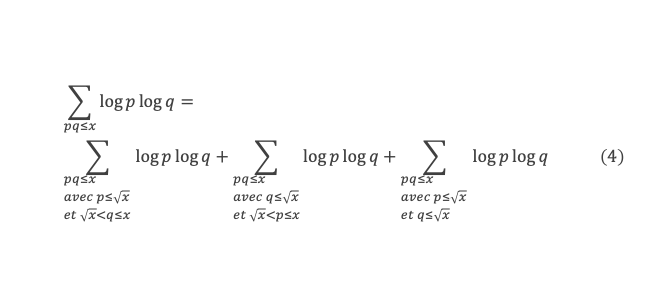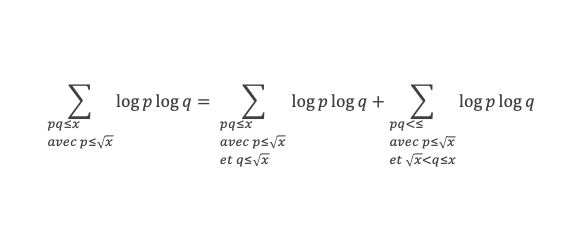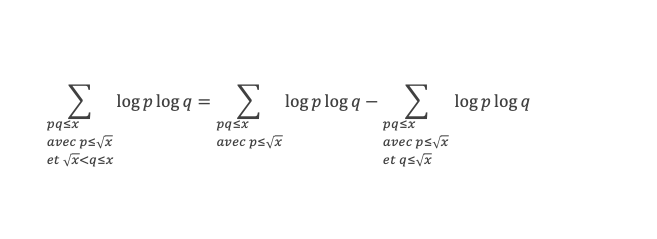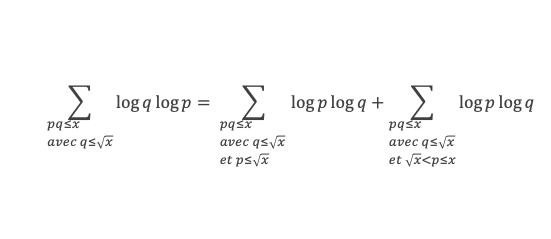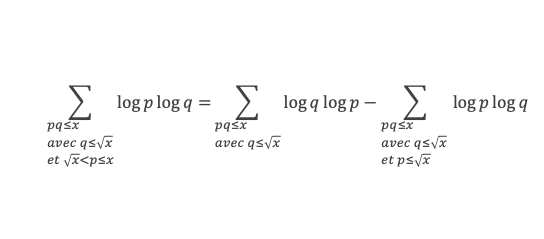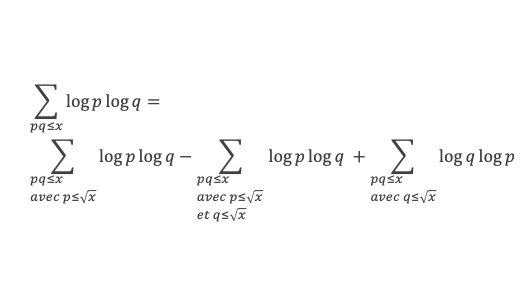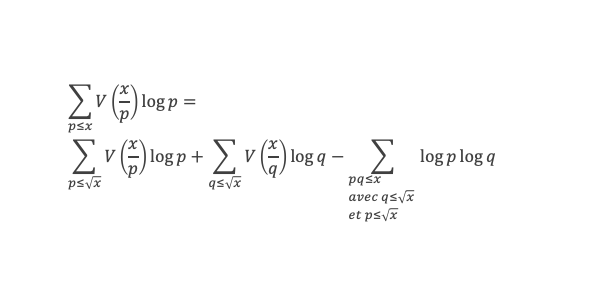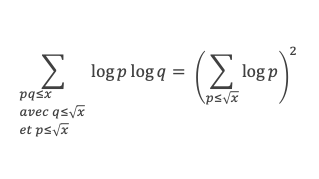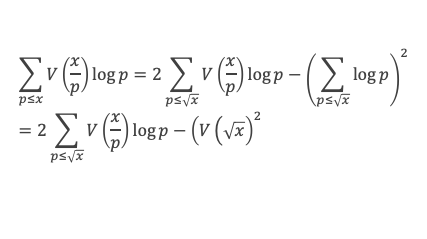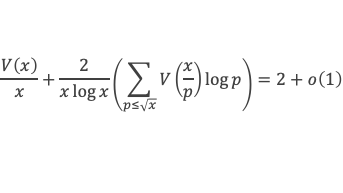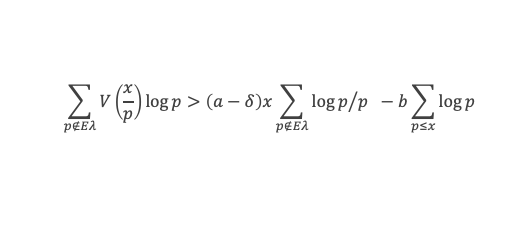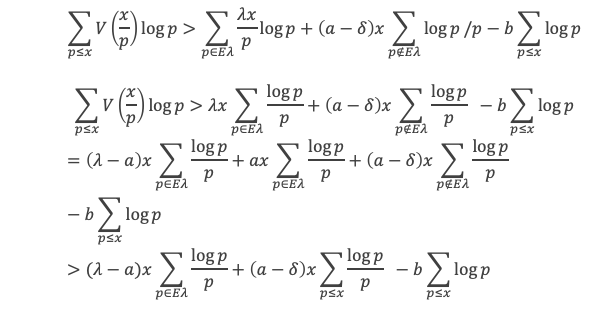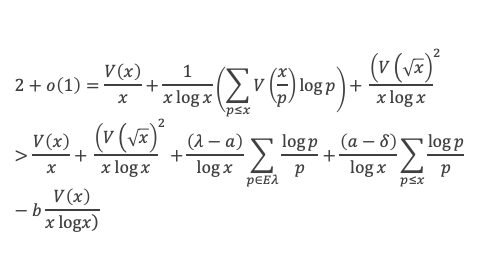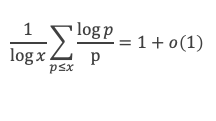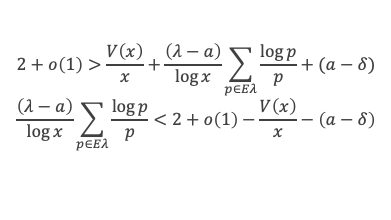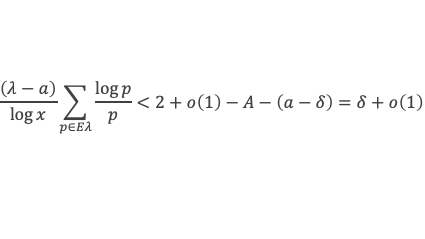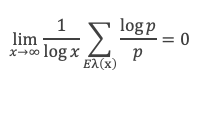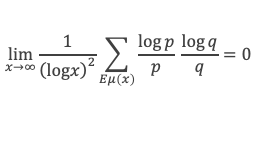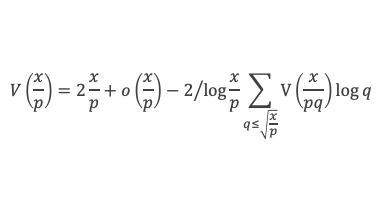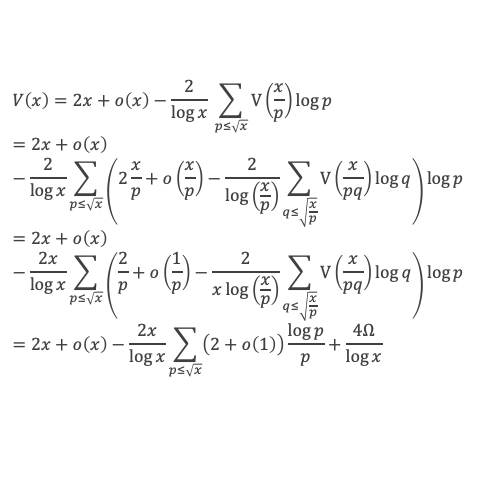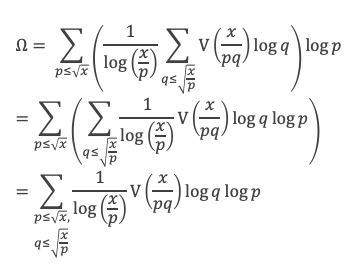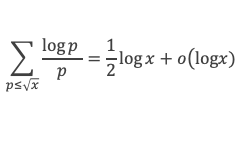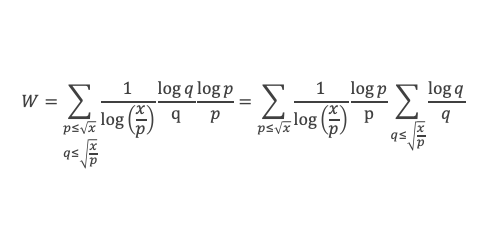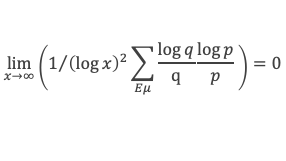Dans un triangle rectangle, le carré de la longueur du côté opposé à l’angle droit (l’hypoténuse) est égal à la somme des carrés des longueurs des deux autres côtés.
Histoire
Ce théorème doit son nom à Pythagore de Samos, philosophe de la Grèce antique au vie siècle avant J.-C., cependant le résultat était connu plus de mille ans auparavant et a vraisemblablement été découvert indépendamment dans plusieurs autres cultures. La plus ancienne démonstration qui nous soit parvenue est due à Euclide, vers 300 avant J.-C.
Démonstration du théorème de Pythagore
On considère un carré dont le côté a pour longueur (a + b). La surface de ce carré peut-être décomposée de 2 façons :
1ère Façon : la surface du carré de côté (a + b) vaut :
(a + b )2 = 4 x ab/2 + c2
2nde Façon : la surface du carré de côté (a + b) vaut :
(a + b )2 = a2 + b2 + 2 x ab
De l’égalité de la surface du carré qui vaut (a + b )2 dans les 2 cas on déduit :
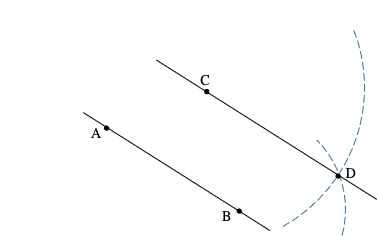
Une droite parallèle à un des côtés du triangle (voir figure ci-contre) coupe ce triangle en un triangle semblable. Cela signifie que le triangle ADE est une homothétie du triangle ABC, autrement dit ADE est juste un modèle réduit du triangle ABC. C’est le triangle ABC vu de plus loin. Comme il s’agit d’un modèle réduit toutes les longueurs sont réduites en proportion :
AD par rapport à AB
AE par rapport à AC
DE par rapport à BC
Enoncé rigoureux : Soit un triangle ABC, et deux points D et E, D sur la droite (AB) et E sur la droite (AC), de sorte que la droite (DE) soit parallèle à la droite (BC). Alors :
.
Réciproquement, le théorème permet d’établir une condition de parallélisme :
Dans un triangle ABC, supposons donnés des points D et E appartenant respectivement aux segments [AB] et [AC] , si les rapports AD / AB et AE / AC sont égaux, alors les droites (DE) et (BC) sont parallèles.
Histoire
Ce théorème est attribué au mathématicien et philosophe grec Thales de Milet au vie siècle av. J.-C. Selon la légende il aurait calculé la hauteur d’une pyramide en mesurant la longueur de son ombre au sol et la longueur de l’ombre d’un bâton de hauteur donnée. Cependant, aucun texte ancien n’attribue la découverte du théorème à Thalès. Dans son commentaire sur les éléments d’Euclide, Proclus affirme que Thales aurait rapporté ce résultat de son voyage en Egypte. Hérodote rapporte la même chose. C’est la raison pour laquelle ce théorème ne porte pas le nom de Thales dans les pays anglo saxons, on parle plutôt de théorème d’interception, ou de théorème des rayons en Allemagne.
L’intérêt de cette légende est de ramener le théorème a un cas pratique qui permet de le mémoriser, à savoir : la hauteur de la pyramide est à la hauteur du bâton ce que la longueur de l’ombre de la pyramide est à la longueur de l’ombre du bâton.
Démonstration du théorème de Thales
Dans un premier temps nous allons raisonner dans le cas d’un triangle rectangle. La généralisation sera ensuite quasi immédiate.
Considérons les 2 triangles (BDE) et (CDE).
Ces 2 triangles ont même base DE et même hauteur h1 = CE, donc leurs surfaces sont identiques.
On en déduit que les 2 triangles suivants (ABE) et (ACD) ont aussi la même surface puisque l’on a juste adjoint le triangle ADE aux 2 triangles précédents.
Le premier triangle à pour base AE et hauteur BC.
Le second triangle a pour base AC et hauteur DE.
d’où : AE x BC = AC x DE, et donc :
AE / AC = DE / BC (1)
De plus, le rapport de la surface du triangle (ADE) par rapport à la surface du triangle (ABE) est égale au rapport de la surface du triangle (ADE) par rapport à la surface du triangle (ACD) puisque comme on l’a vu (ABE) et (ACD) ont même surface (voir figure suivante).
Ce qui donne en notant h2 la hauteur du triangle (ADE) par rapport au côté AD et en remarquant que h2 est aussi la hauteur du triangle ABE par rapport au côté AB :
AD x h2 / AB x h2 = AE x DE / AC x DE
D’où AD / AB = AE / AC (2)
Les résultats (1) et (2) permettent donc d’écrire :
.
Abordons maintenant le cas général d’un triangle qui ne serait pas rectangle. La perpendiculaire à l’un des côtés qui passe par le somment opposé du triangle permet de le diviser en 2 triangles rectangle (cf figure suivante avec les triangles (ABG) et (ACG) ),
et l’on peut donc écrire en utilisant les résultats acquis dans le cas du triangle rectangle, en considérant le triangle (ABG) :
AD / AB = AF / AG = AE / AC, donc AD / AB = AE / AC. (3)
et par ailleurs DF / BG = AD / AB (4),
De même, avec le triangle (ACG), FE / GC = AE / AC, (5)
de (III), (IV) et (V) on tire DF / BG = FE / GC et FE / DF = GC / BG qui donne aussi (1 + FE/DF) = (1 + GC/BG)
De (4) et (6) on déduit DE / BC = DF / BG = AD / AB, et avec (3) on retrouvera :
.
Terminons par la démonstration de la réciproque du théorème : considérons un triangle ABC, et une droite qui coupe les segment AB et AC en respectivement D et E et telle que :
.
Nous allons voir que cette droite DE est alors forcément parallèle à BC.
Pour cela introduisons la droite parallèle au segment BC qui passe par D. Cette droite coupe le segment AC au point E’ et la droite DE’ est parallèle au côté BC.
On en déduit, en utilisant le théorème de Thales que l’on vient de démontrer :
AD / AB = AE′ / AC
AD / AB = AE′ / AC par le théorème et AD / AB = AE / AC par hypothèse de départ,
D’où AE‘ = AE, les points E’ et E sont confondus, la droite DE est donc parallèle à la droite BC.
Un théorème bien pratique :
Bien pratique pour mesurer la hauteur d’un objet dont on connait la distance à laquelle on l’observe, juste avec la longueur de son bras et un double décimètre. La hauteur lue sur le double décimètre tenu à bout de bras (hauteur DE) est à la hauteur de l’objet (BC) ce que la distance oeil – bout du bras (AD) est à la distance de l’objet (AB). Cela suppose quand même que l’on connaisse la distance entre son oeil et le bout de son bras, ce qui n’est pas trop difficile.
BC/DE = AB/AD d’où BC = DE*AB /AD autrement dit :
La hauteur de l’objet (ici la hauteur d’une montagne) = Hauteur lue sur la règle*Distance d’observation / Distance oeil-bras.
Bien pratique aussi pour déterminer la distance à laquelle se trouve l’objet que l’on regarde et dont on connait la hauteur :
AB = AD*BC/DE
Distance de l’objet = Distance oeil-bras*Hauteur de l’objet / Hauteur lue sur la règle.
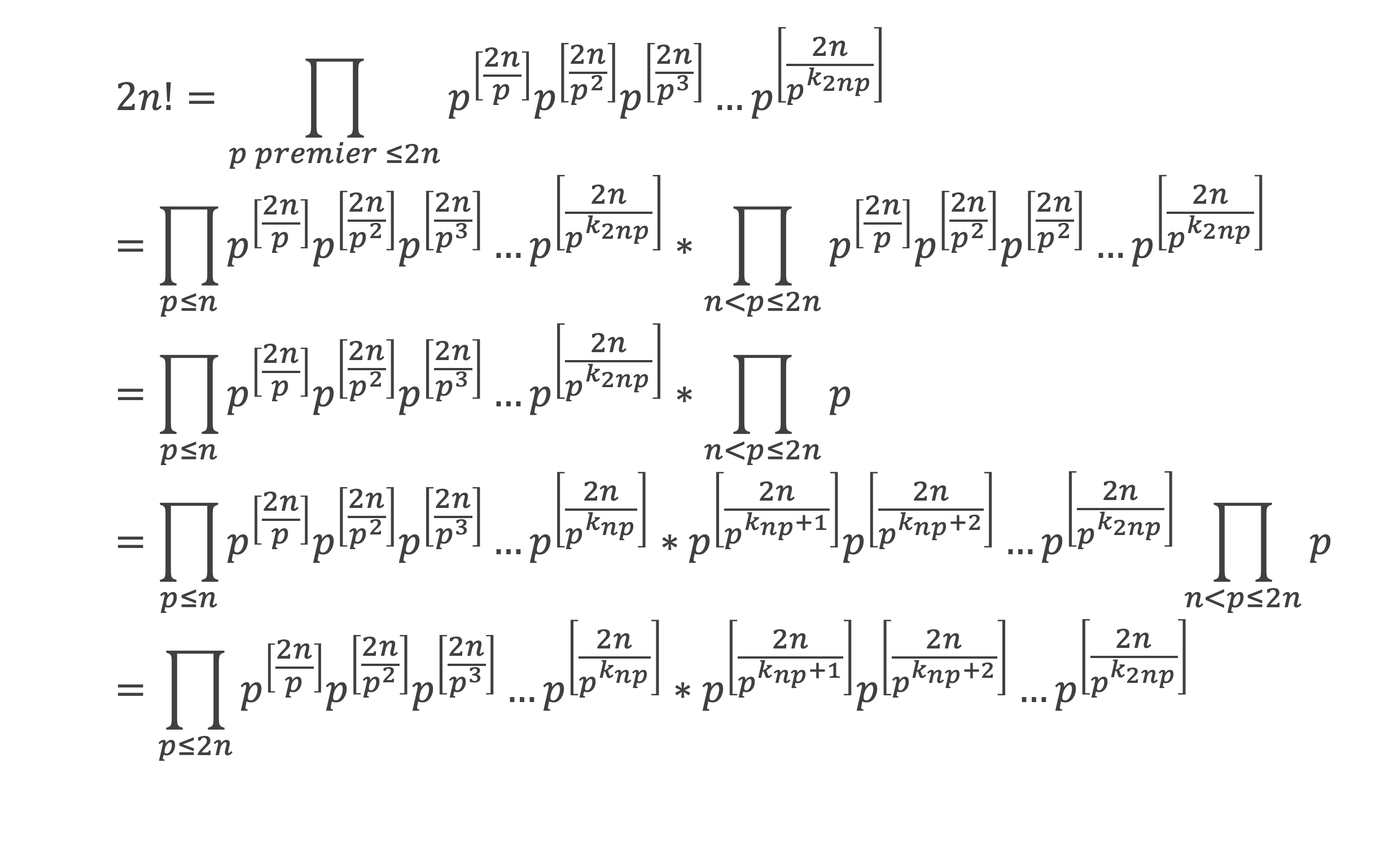
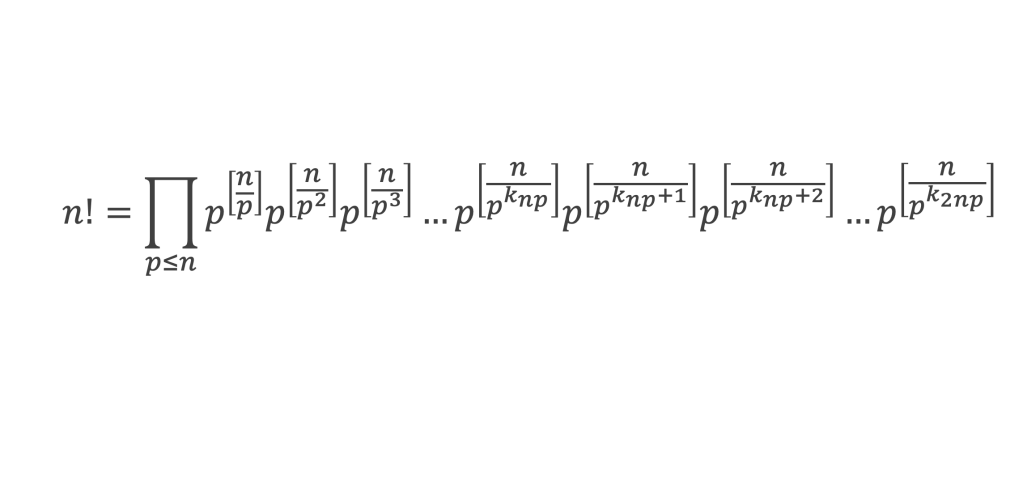
Un entier p strictement plus grand que 1 est un nombre premier si et seulement si il divise (p – 1)! + 1, c’est-à-dire si et seulement si :
(p – 1)! + 1 ≡ 0 (Mod p)
Histoire du théorème
Le premier texte actuellement connu à faire référence à ce résultat est dû au mathématicien arabe Alhazen (965-1039). Il circule en Europe à partir du XVIIe siècle, mais sans être démontré. Au XVIIIe siècle Wilson le redécouvre sous forme de conjecture et partage cette « découverte » avec son professeur Edward Waring qui la publie en 1770. Joseph-Louis Lagrange en présente les 2 premières démonstrations en 1771.
La boîte à outils
Au cours de la démonstration nous aurons besoin de calculer les sommes suivantes :
∑i=1p-1i k avec p premier > 2 et k entier compris entre 1 et (p – 1).
Calcul de cette somme lorsque k = (p – 1) :
∑i=1p-1i p-1 ≡ ∑i=1p-11≡ (p-1) ≡-1 (Mod p) en utilisant le petit théorème de Fermat.
Calcul de cette somme dans les autres cas, c’est-à-dire k entre 1 et (p – 2) :
Nous allons montrer que dans tous ces autres cas ∑i=1p-1ik ≡ 0(Mod p)
Pour cela, raisonnons par récurrence, à partir de k = 1.
Montrons que la propriété est vraie pour k = 1,
∑i=1p-1i ≡ p(p-1)/2(Mod p)
(p – 1) étant divisible par 2, puisque p est impair (premier > 2), la somme ∑i=1p-1i est multiple de p, et l’on a bien ∑i=1p-1i ≡ 0 (Mod p).
Montrons maintenant que lorsqu’elle est vraie pour k de 1 à n, elle l’est aussi pour k de 1 à n + 1 (pour autant que n + 2 reste ≤ (p-1), c’est-à-dire n + 1 ≤ (p-2).
Nous cherchons donc maintenant à vérifier que la somme ∑i=1p-1i n+1 ≡ 0 (Mod p) est multiple de p.
Calculons cette somme, en notant ai les coefficients binomiaux (ils sont forcément entiers puisque résultats du comptage des monômes de degré xi lorsque l’on développe (1 + x)n+2) :
Pour tous x entier non multiple de p, la suite des (p – 1) entiers qui va de (x – 1) à (x – (p – 1)) comprend forcément 1 multiple de p, ce qui implique que :
∀ x entier non multiple de p, P(x)≡ 0(Mod p)
P(x) est un polynôme de degré (p-1), que l’on peut développer sous la forme :
P(x)= x(p-1) + a2x(p-2) + a3x(p-3)+ … + ak x(p–k)+ … + ap-1 x + (p-1)!
∀i ∈ Z/pZ, nous aurons : P(i)≡ 0 (Mod p). Écrivons cela avec la formule développée du polynôme :
Et faisons maintenant la somme : P(1) + P(2) + P(3) +…+ P(i) +…+ P(p-2) + P(p-1)
∑i=1p-1 P(i)≡ 0 (Mod p)
Avec la boîte à outils nous savons que ∑i=1p-1i p-1≡ p – 1 ≡ -1 (Mod p)
Et que les ∑i=1p-1i p-kpour k de 2 à p-1 sont toutes ≡ 0 (Mod p)
La somme se résume donc à :
-1 + (p – 1) (p – 1)!≡ 0 (Mod p)
C’est à dire : (p – 1)! + 1 ≡ 0 (Mod p)
Seconde étape : Considérons un entier p non nul qui n’est pas premier.
p n’est pas premier, on peut donc écrire p = p1*p2 avec p1 et p2 2 entiers < p.
Cas où p = 4 : (p – 1) ! + 1 ≡ 7 ≡ 3 (Mod 4),
Cas où p > 4 : comme les nombres 2 et 3 sont premiers et que l’on s’intéresse aux nombres qui ne sont pas premiers et différents de 4, cela signifie que p est ≥ 5.
On a donc, en considérant p1 comme le plus petit des 2 facteurs :
2 ≤ p1 qui est lui-même ≤ p2 , avec au moins une des 2 inégalités strictes, d’où :
p = p1*p2 ≤ 2 p2 puisque p1 est forcément ≥ 2.
p ≥ 2 p2 = p2 + p2 qui est lui même ≥ p1+ p2 avec au moins une des 2 inégalités strictes,
donc finalement p > p1+ p2 , ce qui implique que (p – 1)! est divisible par (p1 + p2)! qui est lui-même divisible par p1*p2 et donc aussi divisible par p .
Cette hypothèse implique donc que(p – 1) ! ≡ 0 (Mod p).
En conclusion, si p > 4 et n’est pas premier alors (p – 1) ! ≡ 0 (Mod p).
Curiosités
Ce théorème donne théoriquement un test pour vérifier si un nombre est premier ou non. Dans la pratique il ne présente pas vraiment d’intérêt pour tester la primarité car il est plus laborieux qu’un crible d’Eratosthène. En revanche, il permet d’écrire différentes formules amusantes qui ne produisent que des nombres premiers (elles sont elles aussi simples qu’inopérantes).
Formules de calcul du nombre de nombres premiers de 1 à n :
On note π(n) la fonction qui donne le nombre de nombre premier inférieur ou égal à n
Une première formule :
Pour K compris entre 1 et n, en utilisant le théorème de Wilson, il vient, en notant [x] la fonction partie entière de x
[cos (2π ( (p-1)! + 1)/p)] = 1 si p est premier,
[cos (2π ( (p-1)! + 1)/p)] = 0 si p n’est pas premier.
On en déduit :
Expressions que l’on peut encore réduire, en utilisant la fonction Gamma (x), notée Γ(x), qui est un prolongement de la fonction factoriel et qui pour k entier donne Γ(k) = (k – 1)!
A défaut d’être pratique, l’intérêt de cette formule réside dans sa simplicité.
Une seconde formule :
Pour p compris entre 1 et n, en utilisant le théorème de Wilson, il vient :
Sin (π (p – 1)!/p) = 0 si p composé ≥ 5
Sin (π (p – 1)!/p) = Sin (π/p) si p est premier. En effet dans ce cas (p – 1)! + 1 = k*p avec k forcément impair puisque (p – 1)! est pair. On aura donc :
(p – 1) ! = k*p – 1
π (p – 1) ! = π k*p – p
π (p – 1)! /p = π k – π/p
Sin (π (p – 1)!/p) = sin (π – π/p) = sin(π/p)
La fonction π(n) qui donne le nombre de nombre premier inférieur ou égal à n, peut donc s’écrire, pour n ≥ 5 :
Ce qui s’écrit, en utilisant la fonction Γ(k) :
Outre sa relative simplicité, cette formule a le mérite de ne pas faire intervenir de partie entière.
Une Formule de calcul du nième nombre premier : noté pn
En partant de l’expression suivante de pn, qui exploite le fait que π(k) est < n de 1 à pn, puis compris entre 1 et < 2 lorsque n varie de pn à 2[nlogn] + 2 :
On déduit :
Un théorème sur les nombres premiers jumeaux :
Sont dits jumeaux, 2 nombres premiers successifs, c’est à dire tels que p et p + 2 soient tout les deux premiers. Le théorème de Wilson permet d’établir en corollaire le théorème suivant :
p et p + 2 sont premiers jumeaux si et seulement si 4(p – 1)! + 4 + p est divisible par p(p + 2).
Notons déjà que pour p = 3 les nombres p et p + 2 sont premiers jumeaux et la condition est effectivement remplie. De même, pour p = 4, p et p + 2 ne sont pas premiers jumeaux et la condition n’est effectivement pas remplie. Pour la suite, raisonnons avec p ≥ 5.
Montrons d’abord que si p et p + 2 sont premiers, alors 4(p -1) ! + 4 + p est divisible par p(p +2).
D’après le théorème de Wilson, p premier implique :
(p – 1)! + 1 = 0 (Mod p) (I)
D’après le théorème de Wilson, p + 2 premier implique :
(p + 1)! + 1 = 0 (Mod p+2) (II)
Développons (II).
Et comme p est premier :
D’où :
Et comme p! – (p – 1)! + 2 Np – Np+2 est un entier, cela implique que 4(p – 1)! + p + 4 est divisible par p(p + 2).
Donc :
p et p + 2 premiers jumeaux ⟹ 4(p – 1)! + 4 + p est divisible par p(p + 2).
Etudions maintenant la réciproque : supposons que p ou bien p + 2 ne soit pas premiers , ou qu’aucun des deux ne le soit.
Cas p non premier : pour p ≥ 5 on sait qu’alors (p-1) ! = kp,
4(p – 1)! + 4 + p = 4kp + 4 + p = 4(kp + 1) + p, qui n’est pas un nombre divisible par p, donc pas divisible par p(p + 2). La propriété de divisibilité n‘est pas remplie.
Cas p + 2 non premier : on sait qu’alors (p + 1) ! = k (p+2) (III)
Si en plus p n’est pas premier, alors on se retrouve au cas précédent et la propriété de divisibilité ne sera pas remplie.
= k (p+2) + p(p + 1)(p + 4) = k (p+2) + p(p + 1)(p + 2 + 2)
= ( k + p(p + 1) ) (p+2) + 2p(p + 1)
Donc :
Si 4(p – 1)! + 4 + p était divisible par p(p+2) alors ( 4(p – 1)! + 4 + p )*p(p + 1) devrait être divisible par p + 2, et donc 2p(p + 1) devrait aussi être divisible par (p + 2) or ce n’est pas le cas, donc la propriété de divisibilité n’est pas remplie.
Conclusion : si p et p + 2 ne sont pas premiers jumeaux alors la propriété n’est jamais remplie. C’est-à-dire :
Non [p et p + 2 premiers jumeaux] ⟹ 4(p – 1)! + 4 + p n’est pas divisible par p(p + 2).
Ce qui est équivalent à :
4(p – 1)! + 4 + p est divisible par p(p + 2) ⟹ p et p + 2 premiers jumeaux.
Conclusion :
p et p + 2 sont premiers jumeaux si et seulement si 4(p – 1)! + 4 + p est divisible par p(p + 2).
Soit (a1, a2, a3 …, ak, …, an-1, an) et (b1, b2, b3 …, bk, …, bn-1, bn) 2 n-uplets de nombres réels, l’inégalité de Cauchy-Schwarz s’écrit :
La valeur absolue du produit des n-uplets terme à terme est inférieure au produit des racines de la somme des carrés de chaque n-uplet.
Ou sous une autre forme :
Le carré du produit des n-uplets terme à terme est inférieure au produit de la somme des carrés de chaque n-uplet.
L’inégalité devient une égalité stricte si et seulement si les ai et les bi sont tous proportionnels avec la même proportion, c’est-à-dire que l’on a pour tous i, ai = λbi avec le même λ.
Histoire
Cette inégalité, simple à démontrer, n’a rien d’intuitif. C’est peut-être la raison pour laquelle elle n’apparaît qu’en 1821, dans la publication par Augustin Cauchy de son Cours d’analyse de l’École royale polytechnique.
L’inégalité est élargie au cas des dimensions infinies par Viktor Bouniakovski en 1859, puis par Hermann Schwarz dans un mémoire de 1885.
Démonstration de l’inégalité de Cauchy-Schwarz
Considérons la fonction réelle f(t) qui à t réel associe :
f(t) est une somme de carrés, f(t) est donc toujours positive ou nulle. Développons les carrés des termes, il vient :
On voit que f(t) s’exprime sous la forme d’un polynôme en t du second degré :
f(t) = A + t B + t2C
Avec
Le cas trivial où le terme C est nul correspond au cas où tous les bi seraient nuls. Dans ce cas l’inégalité est bien vérifiée et l’on a même l’égalité stricte. On se place donc maintenant dans le cas général où C n’est pas nul, c’est-à-dire que l’on est bien dans le cas d’un polynôme de degré 2. Ce polynôme est toujours positif ou nul, donc il ne peut avoir 2 racines distinctes, ce qui signifie que son déterminant est négatif ou nul, donc :
B2 – 4AC ≤ 0, soit B2 ≤ 4AC
Ce qui donne directement l’inégalité cherchée :
Cas de l’égalité stricte : Montrons maintenant que l’égalité stricte est obtenue si et seulement si les aiet les bisont tous proportionnels avec la même proportion.
Si pour tous i on a ai = λ bi avec le même λ
L’égalité est vérifiée.
Réciproquement, si l’égalité est vérifiée, c’est que le déterminant du polynôme f(t) est nul, c’est-à-dire que le polynôme a une racine double t0 et que cette racine vérifie :
La somme des carrés est nulle, ce qui implique que chaque carré est nul, et donc en notant λ = –t0, tous les ai = λ bi avec le même λ.
Un polynôme à coefficients complexes de degré n, que l’on écrit
P(x) = a0 xn + a1 xn-1+a2 xn-2 + …+ ak xn-k + …+an-1 x + an
Se décompose en un produit de n monômes sous la forme : P(x) = a0(x – β1) … (x – βn).
Ici, la famille des βk, pour k variant de 1 à n, est celle des racines. Certains nombres βk peuvent être égaux, on parle alors de racines multiples.
Histoire du théorème
Un premier énoncé correct du théorème est donné par Albert Girard qui en 1629 dans son traité intitulé Inventions nouvelles en l’algèbre, annonce que :
« Toutes les équations d’algèbre reçoivent autant de solutions que la dénomination de la plus haute quantité le démontre. »
Par solutions, il inclut celles en nombres ‘’imaginaires’’, mais à cette époque la notion de nombres complexes n’est pas claire. Cette idée est reprise par René Descartes qui utilise pour la première fois le terme imaginaire, pour qualifier des racines. Ce théorème, fondamental pour l’algèbre, a dès lors souvent été considéré comme acquis, sans pour autant être démontré.
En 1746 Jean le Rond D’Alembert exprime le besoin de démontrer le théorème fondamental de l’algèbre. Son but est de démontrer l’existence d’une décomposition en éléments simples de n’importe quelle fonction rationnelle, afin d’en obtenir des primitives. Si le monde mathématique admet immédiatement le bien-fondé de la nécessité d’une démonstration, l’approche de D’Alembert ne convainc pas. Elle est incomplète.
Leonard Euler puis Joseph-Louis Lagrange se penchent ensuite successivement sur la question, mais sans aboutir. Puis c’est le tour de Gauss qui présente une première preuve en 1799 mais elle est encore incomplète.
En 1814, un amateur suisse du nom de Jean-Robert Argand présente une preuve à la fois solide et simple fondée sur le canevas de d’Alembert. Un an plus tard, Gauss présente une deuxième preuve, qui fait appel à la démarche d’Euler et de Lagrange, et qui est cette fois rigoureuse, mais plus tardive que celle d’Argand. Les deux seules hypothèses que fait Gauss sont (i) toute équation algébrique de degré impair a une racine réelle ; (ii) toute équation quadratique à coefficients complexes a deux racines complexes.
Cauchy, dans son cours d’Analyse pour l’Ecole Polytechnique (1821) présente une preuve inspirée de celle d’Argand. La démonstration exposée dans cet article reprend l’essentiel de la formulation de Cauchy, avec une mise en forme plus moderne.
Boîte à outils
A et B étant 2 nombres complexes, on peut les écrire sous la forme A = u1 + i v1, B = u2 + i v2 , avec u1, u2, v1, v2nombres réels. On note ‖A‖ la norme de A, définie par ‖A‖ = (u12 + u22)1/2
D’où : ‖A + B‖2 ≤ ‖A‖2 + ‖B‖2 + 2 ‖A‖ * ‖B‖ = ( ‖A‖ + ‖B‖ )2, et comme tous les termes sont positifs : ‖A + B‖ ≤ ‖A‖ + ‖B‖
On a également : ‖A*B‖ = ‖A‖ * ‖B‖, en effet :
‖A*B‖ = ‖(u1+ i v1)*( u2+ i v2)‖ = ‖(u1 u2 – v1 v2) + i (u1 v2+ v1 u2)‖= ( (u1 u2 – v1 v2)2+ (u1 v2+ v1 u2)2)1/2=( (u1 u2)2+(v1 v2)2+(u1 v2)2+(v1 u2)2)1/2=( (u12+ v12)*(u22+ v22) )1/2 = ‖A‖ * ‖B‖
Les grandes lignes de la démonstration
Dans un premier temps nous montrons que tout polynôme P(x) de degré entier > 0 admet forcément au moins 1 racine x0.
Et ensuite que si x0 est racine de P(x) alors (x – x0) divise P(x), c’est-à-dire P(x) = (x – x0) *Rn-1(x) avec Rn-1(x) de degré n-1.
On en déduit donc que tout polynôme de degré n > 0 peut être décomposé sous la forme :
P(x) = (x – x0)* Rn-1(x) avec Rn-1(x) de degré n-1.
La preuve de la décomposition de P(x) en un produit de n monômes s’obtient par récurrence sur n :
La propriété est vraie pour n = 1, et si elle est vraie pour les polynômes de degré n-1 alors le polynôme P(x) peut s’écrire, comme on vient de le voir, P(x) = (x – x0)* Rn-1(x) avec Rn-1(x)de degré n-1.
La propriété étant vraie pour le degré n-1, Rn-1(x) se décompose en un produit de n-1 monômes, et donc P(x) se décompose en produit de n monômes.
Démonstration du théorème fondamental de l’algèbre
Soit P(x) polynôme de degré n entier > 0
P(x)= a0 xn + a1 xn-1+a2 xn-2 + …+ ak xn-k + …+an-1 x + an, avec ak coefficients complexes, et a0 non nul.
Première étape: Montrons que le polynôme P(x) admet forcément au moins 1 racine.
En posant x = u + i v, l’équation P(x) = 0 peut être réécrite sous la forme f(u,v) + i g(u,v)= 0 avec f et g polynômes à coefficients réels, de degré n des 2 variables réelles u et v.
On note pour la suite F(u,v) la fonction f2(u,v) + g2(u,v). Le problème revient donc à démontrer que la fonction F(u,v) qui est une fonction continue et dérivable de u et v, s’annule.
F(u,v) étant une fonction continue et dérivable dont la valeur inférieure est bornée (positive), elle possède un minimum A réel positif ou nul. Soient u0 et v0 les valeurs réelles qui donnent A, et x0 le nombre complexe associé = u0 + i v0.On a f2(u0,v0) + g2(u0,v0) = A, c’est à dire :
‖P(x0)‖2 = A (1).
Nous allons voir maintenant que si A n’est pas nul, alors l’espace entre 0 et A permet de construire à proximité du nombre complexe x0 un complexe (x0 + δx) tel que ‖P(x0 + δx)‖2 < A.
Commençons par calculer P(x0 + δx) pour δx quelconque
Ce qui donne, en développant chacun des termes (x0 +δx)i, un polynôme de degré n en δx que l’on peut écrire sous la forme :
P(x0 +δx) = b0 δxn + b1 δxn-1 + b2 δxn-2 + … + bk δxn-k + … + bn-1 δx + bn , avec bk nombres complexes qui sont des fonctions de x0 et des aj.
Pour δx = 0 on a P(x0 + 0) = bn , donc ‖P(x0)‖ = ‖bn‖, mais on a aussi ‖P(x0)‖2 = A d’après (1)
Donc ‖bn‖2 = A (2).
Pour bien faire apparaître le raisonnement on suppose pour la suite que bn-1est non nul (on considèrera ultérieurement le cas où bn-1est nul). Soit maintenant C, un nombre complexe défini par :
On a en multipliant de chaque côté par bn-1 qui n’est pas nul :
bn-1 C =– ‖bn-1‖2 bn (3).
Et choisissons pour δx la valeur δx = λ C avec λ réel quelconque non nul, il vient :
Si A non nul, comme ∑k ‖bkCn-k ‖, que l’on note D, ne peut pas être nul car C n’est pas nul et les bi ne peuvent être tous nuls avec un polynôme de degré > 1, on peut choisir 0 < λ < √A ‖bn-1‖2 / D , et on obtient alors :
Comme ‖P(x0 + λ C)‖ et √A sont positifs, ‖P(x0 + λC)‖ < √A ⟹ ‖P(x0 + λ C)‖2 < A
Or A était censée être la valeur Min de ‖P(x)‖2. Donc l’hypothèse A non nul ne peut être réalisée, il existe forcément x0 = u0 +i v0 tel que f2(u0,v0) + g2(u0,v0) = 0, et donc tel que P(x0) = 0.
Nous avons conduit la démonstration en supposant que bn-1était non nul. Nous allons maintenant traiter le cas général où cette condition n’est pas imposée.
P(x0 +δx) = b0 δxn + b1 δxn-1 + b2 δxn-2 + …+ bk δxn-k + …+ bn-m δxm + bn, où m est la plus petite puissance positive telle que bn-m soit non nul. Précédemment nous avions fait l’hypothèse m = 1
Nous définissons cette fois C par :
Nous aurons bn-m Cm = – ‖bn-m‖2bn (4), et de nouveau choisissons δx = λC avec λ réel quelconque non nul.
Ce résultat est de nouveau contraire à l’hypothèse selon laquelle A est la valeur min de ‖P(x)‖2. L’hypothèse A non nul conduit toujours à une contradiction. A est donc nul, ce qui veut dire que P(x) a au moins une racine.
Seconde étape :
Si x0 est racine de P(x) alors (x – x0) divise P(x), c’est-à-dire P(x)=(x – x0) * R(x) avec R(x) de degré n-1.
On a donc (xn – x0n) + a1 (xn-1– x0n-1) + a2(xn-2 – x0n-2)+ … + ak (xn-k – x0n-k)+ … + an-1 (x – x0) =(x – x0) * R(x) avec R(x) de degré n-1
Soit : P(x) = (x – x0) * R(x) avec R(x) de degré n-1.
Nous avons donc montré que tout polynôme P(x) de degré entier > 0 admet forcément au moins 1 racine x0 et que lorsque x0 est racine de P(x) alors (x – x0) divise P(x), c’est-à-dire P(x)=(x – x0)* Rn-1(x) avec Rn-1(x) de degré n-1. On en déduit donc que tout polynôme de degré n > 0 peut être décomposé sous la forme :
P(x) = (x – x0)* Rn-1(x) avec Rn-1(x) de degré n-1.
Il reste à démontrer que P(x) se décompose en un produit de n monômes. Pour cela on opère par récurrence :
La propriété est vraie pour n = 1,
Supposons qu’elle soit vraie pour les polynômes de degré n-1 :
Le polynôme P(x) de degré n peut s’écrire, P(x) = (x – x0) * Rn-1(x) avec Rn-1(x) polynôme de degré n-1.
La propriété étant vraie pour le degré n-1, Rn-1(x) se décompose en un produit de n-1 monômes, et donc P(x) se décompose en produit de n monômes. La propriété devient donc vraie pour le degré n.
Étant données une équation polynomiale de degré n, avec n entier ≥ 5
Xn + a1Xn-1 + a2Xn-2 + …+ an-2X2 + an-1X + an= 0
Il n’existe pas de fonction algébrique permettant d’exprimer les racines xi de l’équation à partir des coefficients ai.
Attention nuance : le théorème porte sur le cas général des équations de degré n ≥ 5. Il y a des cas particuliers d’équations résolubles par une fonction algébrique, par exemple :
X10 + a1X5 + a2 = 0
Qui se résout très bien en utilisant la formule des équations de degré 2.
Le théorème se limite à la recherche d’une solution qui s’exprimerait à l’aide d’une fonction algébrique, c’est-à-dire d’une fonction qui utilise comme opérations les additions, soustractions, multiplications, divisions, puissances nièmes, racines nièmes. L’utilisation de fonctions plus complexes, telles que les fonctions elliptiques, permettent de les résoudre.
Histoire du théorème
La résolution des équations du second degré, donc de la forme X2 + a1X + a2 = 0 où l’on cherche l’inconnu X, remonte à plus de trois mille ans. Elles sont au centre de l’algèbre babylonienne, dès avant le XVIIIe siècle av. J.-C.
Au IXe siècle Al-Khwarizmi en fait une étude systématique dans un ouvrage intitulé Abrégé du calcul par la restauration et la comparaison qui, via le mot « restauration » (en arabe : al-jabr) a donné son nom à l’algèbre.
Il faut attendre le XVIe siècle pour voir apparaître une solution générale aux équations de degré 3, donc de la forme : X3 + a1X2 + a2X + a3= 0
Elle est mise au point par l’Italien Tartaglia qui l’utilise lors d’un célèbre concours qui l’oppose à son compatriote Fiore, en 1535.
En 1545, Jérome Cardan publie Ars Magna (Le Grand Art). Il y expose la méthode de résolution de Tartaglia en lui en attribuant bien la paternité. Il complète son exposé par une justification de la méthode et l’étend à l’ensemble de tous les autres cas. Il publie, à cette occasion, la méthode de résolution de l’équation de degré 4 mise au point par son élève Ludovico Ferrari. L’importance de l’œuvre de Cardan fait que la postérité ne retiendra que son nom et que cette méthode de résolution des équations de degré 3 va porter le nom de méthode de Cardan.
Dans son mémoire de 1771, Lagrange réalise une synthèse de toutes les méthodes utilisées dans le passé pour résoudre l’équation algébrique de petit degré. À partir de cette synthèse, il développe une méthode, qui s’applique aux degrés 2, 3 et 4. Il montre de plus que cette méthode ne peut aboutir dans le cas général si le degré est plus élevé. La question de savoir s’il n’existe pas d’autres méthodes qui fonctionneraient reste néanmoins ouverte. A partir de l’idée de Vandermonde d’utiliser les fonctions symétriques ainsi que les relations entre les coefficients et les racines, il montre l’importance des n! permutations des racines pour la résolution du cas général. Il établit à ce propos deux théorèmes préfigurant la théorie des groupes. Le premier est que les n! permutations d’un n-uplets ont comme image par une fonction de n variables un ensemble dont le cardinal est un diviseur de n!. Ce résultat est un ancêtre de ce que l’on appelle maintenant le théorème de Lagrange sur les groupes. Le deuxième concerne les fonctions qu’il qualifie de semblables et qui sont invariantes par le même sous-groupe de permutation. Ce résultat anticipe les théorèmes sur les suites de sous-groupes que l’on trouve dans la théorie de Galois. La conclusion de Lagrange est pessimiste. Il émet l’idée que la résolution algébrique de l’équation soit impossible. Le chemin est tracé, soit pour trouver une méthode générale de résolution, soit pour montrer l’inexistence d’une telle méthode. La solution réside dans une analyse combinatoire des possibles permutations des racines.
L’éventuelle impossibilité de la résolution par radicaux du cas général fait son chemin. Paolo Ruffini publie quatre mémoires à ce sujet, en 1799, 1804, puis en 1808 et 1813. Pour la première fois, l’impossibilité est clairement déclarée. Sa tentative pour le prouver suit la démarche de Lagrange et consiste à montrer que l’usage d’une équation auxiliaire ne permet pas, pour le degré 5, d’abaisser systématiquement le degré de l’équation initiale. Il établit que, si une fonction symétrique de cinq variables prend strictement moins de cinq valeurs par permutations des variables, alors elle n’en prend pas plus de 2. Son approche est lacunaire. Rien n’indique qu’une approche radicalement différente de celles décrites par Lagrange ne pourrait aboutir.
Pour conclure de manière définitive, il fallait raisonner différemment que ne l’avaient fait Lagrange ou Ruffini. Niels Abel l’exprime ainsi : « […] on se proposait de résoudre les équations sans savoir si cela était possible. Dans ce cas, on pouvait bien parvenir à la résolution, quoique ce ne fût nullement certain […] Au lieu de demander une relation dont on ne sait pas si elle existe ou non, il faut se demander si une telle relation est en effet possible. » En 1826, Abel part du résultat et suppose qu’il existe une formule, fonction rationnelle de radicaux, qui donne la solution d’une équation de degré 5. Il sait qu’elle est à même d’exprimer 5 racines différentes et qu’en conséquence, elle possède un comportement précis vis-à-vis des permutations des variables, déjà étudiées par Vandermonde, Lagrange puis Cauchy. Il démontre que ce comportement introduit une absurdité.
Ce résultat reste à ce moment fort peu connu. Son article, pourtant envoyé à Gauss, Legendre et Cauchy n’intéressera personne.
Boîte à outils
La démonstration repose largement sur le concept de symétrie de la fonction par rapport aux variables. Ce que l’on entend par là nécessite quelques explications, à commencer par la notation des variables, et le sens des noms qu’on leur attribue.
Considérons une fonction F de 5 variables. Pour concrétiser la définition de cette fonction, nous avons besoin de donner des noms aux différentes variables, par exemple en les désignant par a, b, c, d, et e, et nous avons besoin d’associer à cette fonction une expression mathématique construite à partir de ces noms de variables. Par exemple :
F(a, b, c, d, e) = a + 3b + 5c + 2d + e. (0-1)
Ce que l’on appelle expression de la fonction est en quelque sorte l’algorithme de calcul de cette fonction, en l’occurrence : somme de la première variable avec 3 fois la deuxième, 5 fois la troisième, 2 fois la quatrième, et la cinquième.
Lorsque l’on dit que l’on note les variables a, b, c, d, et e, cela signifie que l’on affecte le nom a à la première variable, le nom b à la seconde variable, le nom c à la troisième, etc…
On aurait pu tout autant choisir d’autres noms pour les variables, par exemple les noms c, d, e, f, g, h et la même fonction s’écrirait :
F(c, d, e, f, g) = c + 3d + 5e + 2f + g. (0-2)
F(a, b, c, d, e) = a + 3b + 5c + 2d + e et F(c, d, e, f, g) = c + 3d + 5e + 2f + g désignent la même fonction, bien que les noms des variables soit différents.
L’égalité (0-1) qui associe la notation F(a, b, c, d, e) à l’expression a + 3b + 5c + 2d + e est définie et vraie pour toutes les valeurs que pourraient prendre les 5 variables et quel que soit leur nom. C’est le sens de cette égalité.
D’une façon générale si l’on note F(a, b, c, d, e) la fonction, et E(a, b, c, d, e) l’expression de son calcul (a + 3b + 5c + 2d + e en l’occurrence) alors :
F(a, b, c, d, e) = E(a, b, c, d, e)
Et si l’on change le nom de variable dans F, il faut faire le même changement de nom dans E. Si l’on permute des lettres dans F, il faut permuter les lettres de la même façon dans E pour conserver l’égalité et travailler avec la même fonction. Ainsi, si l’on décide d’appeler la première variable b, et la seconde variable a, sans changer le nom des autres variables, la fonction noté F(b, a, c, d, e) aura pour expression (ou algorithme de calcul) : b + 3a + 5c + 2d + e. Ainsi les fonctions F(a, b, c, d, e) avec l’expression a + 3b + 5c + 2d + e, et F(b, a, c, d, e) avec l’expression b + 3a + 5c + 2d + e sont bien identiques.
Mais attention lorsque l’on attribue une valeur numérique à chaque variable.
Exemple : supposons que l’on affecte au quintuplet (a, b, c, d, e) les valeurs (2, 7, 4, 1, 14)
F(b, a, c, d, e) = b + 3a + 5c + 2d + e avec l’expression (0-2) = 7 + 6 + 20 + 2 + 14 = 49
Dans les 2 cas on travaille bien avec la même fonction F, mais dans un cas on calcule F(2, 7, 4, 1, 14) et dans l’autre cas F(7, 2, 4, 1, 14) or la fonction F est telle que F(2, 7, 4, 1, 14) ≠ F(7, 2, 4, 1, 14).
En fait, si l’on permute les variables (en l’occurrence a et b), il faut aussi permuter les valeurs (en l’occurrence 2 et 7), pour retrouver les mêmes valeurs numériques :
b + 3a + 5c + 2d + e = 59 avec (7, 2, 4, 1, 14) et a + 3b + 5c + 2d + e = 59 avec (2, 7, 4, 1, 14)
La fonction F donne bien toujours les mêmes valeurs pour un quintuplet de 5 valeurs numériques données, indépendamment de la façon de nommer les variables, et heureusement.
Allons plus loin. Considérons 2 fonctions F1 et F2 quelconques telles que pout tous a, b, c, d, e, on ait l’égalité :
F1(a, b, c, d, e) = F2(a, b, c, d, e). (0-3)
Si l’on échange les 2 premières variables, désormais b est la première variable et a la seconde , on aura :
F1(b, a, c, d, e) = F2(b, a, c, d, e)
Et d’une façon générale, toute permutation entre les variables (2 des 5 ou 3 des 5 ou 4 des 5, ou les 5) conservera l’égalité si elle est appliquée identiquement aux 2 termes. C’est à dire par exemple :
F1(b, a, d, e, c) = F2(b, a, d, e, c), ou bien F1(c, e, d, a, b) = F2(c, e, d, a, b)
Ce que l’on peut écrire : F1(Permut(a, b, c, d, e)) = F2(Permut(a, b, c, d, e))
Une autre façon d’assimiler cette notion consiste à d’introduire la fonction K(b, a, c, d, e) = F1(b, a, c, d, e) – F2(b, a, c, d, e). D’après (0-3) la fonction K(a, b, c, d, e) = 0 quelles que soient les valeurs de ses variables. On aura donc K(b, a, c, d, e) = 0, ce qui donne à nouveau F1(b, a, d, e, c) = F2(b, a, d, e, c), ou K(c, e, d, a, b) = 0, ce qui donne à nouveau F1(c, e, d, a, b) = F2(c, e, d, a, b), et d’une façon générale : K(Permut(a, b, c, d, e)) = 0, soit F1(Permut(a, b, c, d, e)) = F2(Permut(a, b, c, d, e)).
Ce résultat trivial sera très utile au paragraphe 3 de la démonstration, où l’on rencontre le cas de l’égalité
F1(a, b, c, d, e) = F2(a, b, c, d, e) avec F2 vérifiant aussi F2(a, b, c, d, e) = α F1(b, a, c, d, e) (0-4)
Il permet d’écrire
F1(b, a, c, d, e) = F2(b, a, c, d, e) = α F1(a, b, c, d, e) (0-5)
Et comme d’après (0-4) F1(a, b, c, d, e) = α F1(b, a, c, d, e), cela donne en remplaçant dans (0-5)
Une fonction présente une symétrie si son expression reste inchangée lors d’une permutation de variable.
Dans le cas de la fonction F(a, b, c, d, e) = a + 3b + 5c + 2d + e, la fonction n’est pas symétrique pour les échanges entres a et b. En effet si l’on permute a et b alors F(b, a, c, d, e) = b + 3a + 5c + 2d + e qui est une expression différente de a + 3b + 5c + 2d + e. Comme on l’a vu au paragraphe précédent, si l’on permute les variables, il faudra aussi permuter les valeurs des variables pour retrouver le même résultat.
D’où, en général, F(b, a, c, d, e) ≠ F(a, b, c, d, e) pour un même jeu de valeurs de (a, b, c, d, e). C’est ce que l’on a vu lors du calcul de F(2, 7, 4, 1, 14) et de F(7, 2, 4, 1, 14).
Cela n’est pas choquant ce comportement est normal lorsqu’il n’y a pas de symétrie, particulière ce qui est le cas généralement des fonctions. En revanche, si l’on considère la même fonction F et que l’on permute les variables a et e, on a alors :
F(e, b, c, d, a) = e + 3b + 5c + 2d + a = a + 3b + 5c + 2d + e = F(a, b, c, d, e)
a et e sont symétriques, nous pouvons permuter seulement les noms, ou seulement les valeurs, cela ne change pas le résultat.
F(e, b, c, d, a) = F(a, b, c, d, e)
Les expressions des 2 fonctions sont identiques, insensibles à la permutation des variables.
F(2, 7, 4, 1, 14) = F(14, 2, 4, 1, 2)
Par symétrique nous entendons que la valeur du terme reste inchangée lorsque l’on permute la valeur d’un xi avec celle d’un xj quelque soit les valeurs en jeu.
Une fonction peut avoir plus ou moins de symétrie, par exemple :
Soit G(a, b, c, d, e) = a*b*e + d*c
G possède 2 types de symétrie :
une symétrie d’ordre 2 entre d et c : G(a, b, d, c, e) = G(a, b, c, d, e)
une symétrie d’ordre 3 entre a, b et e : G(a, b, c, d, e) = G(b, a, c, d, e) = G(e, b, c, d, a) = G(a, e, c, d, b) = G(e, a, c, d, b) = G(b, e, c, d, a)
Notons au passage que la symétrie d’ordre 3 permet de faire une permutation circulaire sur les 3 variables a, b, e, (e prend la place de a qui prend la place de b qui prend la place de e) de sorte que : G(a, b, c, d, e) = G(e, a, c, d, b) = G(b, e, c, d, a)
Pour le corps de la démonstration nous utiliserons non plus les lettres a, b, c, d, e, mais les termes x1, x2, x3,x4, x5 comme noms de variable.
Les grandes lignes de la démonstration
Si le problème n’a pas de solution pour les équations de degré 5, il ne peut pas en avoir pour les équations de degré supérieur. En effet, s’il existait une fonction algébrique donnant les racines pour des degré supérieur, par exemple 7, il suffirait de multiplier l’équation de départ par le polynôme (X + 1)2de degré 2 pour se retrouver avec une équation de degré 7. On appliquerait alors la fonction résolvante qui donnerait les 7 racines, à savoir x1, x2, x3,x4, x5 et -1, -1 .
La démonstration se concentre donc sur les équations de degré 5.
Partie 1 : les propriétés de la fonction que l’on recherche :
S’il existe une fonction algébrique qui exprime dans le cas général les racines d’une équation de degré 5 en fonction des coefficients ai de l’équation, alors on verra que cette fonction doit forcément pouvoir s’exprimer aussi comme une fonction h de ces 5 racines, et donc aussi comme une fonction H de polynômes symétriques de ces 5 racines.
L’expression de H(x1, x2, x3,x4, x5) doit forcément donner des valeurs différentes lorsque l’on fait certaines permutations des variables entre elles. En particulier on doit obtenir les 5 racines de l’équation en appliquant successivement des permutations circulaires de 5 variables.
Par exemple si on dispose de l’expression x1 = H(x1, x2, x3,x4, x5), c’est à dire : x1 – H(x1, x2, x3,x4, x5) = 0, alors en remplaçant x1 par x2 , x2 par x3, x3 par x4, x4 par x5, x5 par x1, on obtient successivement :
x2 = H(x2, x3, x4, x5, x1)
x3 = H(x3, x4, x5, x1, x2)
x4 = H(x4, x5, x1, x2, x3)
x5 = H(x5, x1, x2, x3, x4)
La fonction H ne peut donc pas être invariante pour les permutations circulaires de ses 5 variables.
Partie 2 : Les propriétés d’une fonction algébrique construite à partir des coefficients de l’équation
Toute fonction algébrique h(a1, a2, a3, a4, a5) construite à partir des additions, soustractions, multiplications, divisions, puissances nièmes, et radicaux nièmes appliqués aux coefficients ai sera telle que H(x1, x2, x3,x4, x5) possédera un niveau de symétrie trop élevé, qui laissera H invariante pour les permutations circulaires de ses 5 variables.
La preuve est apportée en examinant successivement l’effet des racines carrées, puis des racines impaires sur les permutations circulaires de degré 3 et 5. Le résultat de l’examen est que ces racines conservent les propriétés de symétrie circulaire.
Conclusion : Les exigences des parties 1 et 2 sont contradictoires. Le problème est insoluble.
La démonstration
1- Formulation du problème :
Étant donné l’équation générale de cinquième degré à coefficients rationnels de la forme :
f(X) = X5 + a1X4 + a2X3 + a3X2 + a4X + a5 = 0 (1)
Nous voulons, dans le cas général, cinq solutions distinctes, notées x1, x2, x3, x4, x5, qui s’exprimeraient sous la forme :
x1 = h1(a1, a2, a3, a4, a5)
x2 = h2(a1, a2, a3, a4, a5)
x3 = h3(a1, a2, a3, a4, a5) (2)
x4 = h4(a1, a2, a3, a4, a5)
x5 = h5(a1, a2, a3, a4, a5)
C’est-à-dire que nous recherchons 5 expressions qui à partir des coefficients ai permettent de calculer algébriquement les valeurs des xi.
Calculer algébriquement signifie que les opérations de calcul ne font intervenir que des additions, soustractions, multiplications, divisions, puissances nièmes, et radicaux nièmes.
Les coefficients ai de (1) peuvent être exprimés sous forme de fonction des racines xi, grâce au fait que la même équation (1) peut être ré-écrite sous la forme (3) suivante :
(X – x1)(X – x2)(X – x3)(X – x4)(X – x5) = 0 (3)
En effectuant le produit des termes de (3), nous obtenons :
Ainsi, chaque coefficient ai peut être exprimé sous la forme d’un polynôme en (x1, x2, x3,x4, x5) dont il faut noter la remarquable propriété de symétrie. Chacun de ces 5 polynômes est symétrique par rapport aux variables xi, c’est-à-dire invariant pour toute permutation entre les xi, jusqu’aux permutations circulaires d’ordre 5. Ces 5 polynômes sont nommés polynômes symétriques de base pour la suite.
Considérons l’une quelconque des expressions hi(i = 1 ou 2 ou 3 …) de (2)
hi (a1, a2, a3, a4, a5) = xi = fonction hide ( 5 termes symétriques par rapport aux xi)
Ce que l’on ré-écrit : hi (a1, a2, a3, a4, a5) = xi = Hi(x1, x2, x3,x4, x5) avec Hi une expression algébrique qui est entièrement construite (par addition, multiplication, division, puissances n-ièmes, racines n-ièmes) à partir de termes symétriques par rapport aux xi.
Mais Hi, bien que composée uniquement de termes symétriques en xi doit par exécution successive des opérations de calcul algébrique se simplifier et se réduire finalement à une seule variable xi.
Par symétrique nous entendons que la valeur du terme reste inchangée lorsque l’on permute la valeur d’un xi avec celle d’un xj. Voir chapitre Boîte à outils.
Chacun des termes en xi a le même comportement qu’un autre xj. Mais alors se pose la question : comment fait H1 pour produire à la fin la valeur x1 alors que le calcul n’est fait qu’à partir de termes symétriques, qui ne permettent pas de faire de distinctions entre les xi ?
Pour le comprendre, examinons ce qu’il se passe avec l’équation du second degré.
f(X) = X2 + a1X + a2 = 0
a1 = – (x1 + x2)
a2 = (x1x2)
On sait que pour les équations de degré 2, h1 et h2 ont pour expression :
(-a1 + √(a12 – 4a2) )/2 = ( x1 + x2 + √((x1 + x2)2 – 4x1x2) )/2 = ( x1 + x2 + √((x1 – x2)2 )/2 , expression qui à ce stade est encore symétrique, c’est à dire qu’elle reste inchangée si l’on remplace x1 par x2 et x2 par x1. En effet la permutation de x2 avec x1 donne alors : ( x2 + x1 + √((x2 – x1)2 )/2 .
√((x2 – x1)2= [ (x1 – x2) ou (x2 – x1) ] expression qui sous cette forme reste encore symétrique, mais la symétrie disparaît dès que l’on choisit une seule des 2 branches de l’alternative :
H1(x1, x2) = ((x1 + x2) + (x1 – x2))/2 si l’on choisit (x1 – x2) pour racine. Dans ce cas H1(x1, x2) = x1
H1(x1, x2) = ((x1 + x2) + (x2 – x1))/2 si l’on choisit (x2 – x1) pour racine. Dans ce cas H1(x1, x2) = x2
Dans les 2 cas H1(x1, x2) ne fait ressortir qu’une seule valeur, soit x1 soit x2 selon le choix de l’alternative ouverte par le traitement de √((x2 – x1)2. L’expression par H1 est bien élaborée au départ à partir de termes symétriques qui sont (x1 + x2) et ((x1 + x2)2 – 4 x1x2), mais pourtant après calcul littéral elle ne donne qu’une seule des 2 variables (soit x1 soit x2), la symétrie a disparu grâce à l’action du radical qui force un choix entre 2 expressions non symétriques. Un radical peut détruire la symétrie de la formule littérale.
Notons qu’une fois le choix fait, l’expression H1 (x1, x2) étant dissymétrique = ((x1 + x2) + (x1 – x2))/2, si l’on échange maintenant x1 et x2 dans la formule de H1 on obtient
H1(x2, x1) = x2
Ainsi on a élaboré une expression H(x1, x2) qui permet de calculer une première racine, et telle que H(x2, x1) donne la deuxième qui est différente en générale de la première.
Le mécanisme de destruction de la symétrie grâce à des radicaux est la clé pour disposer d’une formule qui donne une variable x1 à partir de termes symétriques en x1, x2, x3, x4, x5.
Les cas des équations de degré 3 et 4 montrent le même comportement de destruction de la symétrie pour aboutir finalement à une réduction de l’expression à une seul variable xi, cf annexes.
Revenons au cas des équations de degré 5 :
L’existence d’une expression permettant de calculer les racines à partir des coefficients ai de l’équation (1) implique donc l’existence d’expressions Hi(x1, x2, x3, x4, x5) qui sont entièrement construites à partir de termes symétriques par rapport aux xi au départ, mais qui par exécution successive des opérations de calcul (ou calcul littéral) se simplifient et se réduisent finalement à une seule des 5 variables xi.
Prenons par exemple le cas de H3, H3(x1, x2, x3, x4, x5) = x3, c’est-à-dire que H3 est une expression qui à partir des 5 variables d’entrée se simplifie et donne finalement en résultat la 3ième variable.
Permutons x1 et x3 dans l’expression H3 : partout où il y avait un x3 on aura un x1 et partout où il y avait un x1on aura un x3. On dispose ainsi d’une nouvelle expression, et qui est telle que lorsqu’on l’on exécute successivement les mêmes opérations de calcul (= même calcul littéral, ou même algorithme de calcul) qui avaient abouti avec l’expression H3 à la sortie de la 3ième variable, on obtiendra cette fois H3(x3, x2, x1, x4, x5) = troisième variable = x1. Une autre façon de voir le problème est de considérer que H3(x1, x2, x3,x4, x5) donne l’expression de la troisième racine de l’équation :
(X – x1)(X – x2)(X – x3)(X – x4)(X – x5) = 0
Si l’on considère maintenant l’équation : (X – x3)(X – x2)(X – x1)(X – x4)(X – x5) = 0, dans laquelle x1 est la troisième racine, et x3 la première, l’application de la même formule H3 à (x3, x2,x1,x4,x5) doit donner x1.
De même on obtiendra :
H3(x1, x3, x2, x4, x5) = x2, avec la permutation de x3 et x2 dans l’égalité de départ H3(x1, x2, x3,x4, x5) = x3
H3(x1, x3, x2, x4, x5) = x2, avec la permutation de x3 et x2 dans l’égalité de départ H3(x1, x2, x3,x4, x5) = x3
H3(x1, x2, x4, x3, x5) = x4, avec la permutation de x3 et x4 dans l’égalité de départ H3(x1, x2, x3,x4, x5) = x3
H3(x1, x2, x5, x4, x3) = x5, avec la permutation de x3 et x5 dans l’égalité de départ H3(x1, x2, x3,x4, x5) = x3
H3 est donc une expression de 5 variables qui se simplifie par calcul littéral pour en donner une seule des 5, et elle permet aussi de produire les 5 racines différentes simplement à partir des permutations entre les 5 variables.
La question de la résolution des équations de degré 5 par une fonction algébrique devient :
Existe-t-il une expression de 5 variables, élaborée à partir d’une combinaison algébrique des 5 polynômes symétriques de ces 5 variables (ceux de (5) ), telles que son expression puisse se simplifier par calcul littéral (c’est-à-dire enchaînement des opérations de calcul formel) pour se réduire finalement à une seule des 5 variables ?
Si une telle expression existe alors elle permet de calculer les 5 racines du polynôme (1) par simple permutation entre les variables.
On se doute que la simplification du calcul permettant de passer d’une expression symétrique à une expression où il ne reste plus qu’une variable s’appuiera sur l’existence de radicaux. En effet les sommes et produits de termes symétriques donnent des résultats symétriques, et ne permettent pas à eux seuls de casser la symétrie qui est pourtant nécessaire pour faire émerger une seule des 5 variables.
En outre, cette expression, si elle existe en donnant successivement les 5 variables qui la composent, ne peut pas être invariante pour une permutation circulaire de ses 5 variables. Démonstration :
Les permutations circulaires de base, de 5 variables sont les suivantes :
(x1, x2, x3, x4, x5),
(x5, x1, x2, x3, x4), où x5 est passé en tête et les autres variables se sont décalées de 1 position
(x4, x5, x1, x2, x3), où x4 est passé en tête et les autres variables se sont décalées de 1 position
(x3, x4, x5, x1, x2), où x3 est passé en tête et les autres variables se sont décalées de 1 position
(x2, x3, x4, x5, x1), où x2 est passé en tête et les autres variables se sont décalées de 1 position
On reste dans le cas où Hi(x1, x2, x3, x4, x5, x5) donne toujours comme résultat la troisième variable (le raisonnement s’applique tout autant pour les autres Hi), on aura donc, selon les permutations circulaires des 5 variables :
Hi(x1, x2, x3, x4, x5) = x3
Hi(x5, x1, x2, x3, x4) = x2
Hi(x4, x5, x1, x2, x3) = x1
Hi(x3, x4, x5, x1, x2) = x5
Hi(x2, x3, x4, x5, x1) = x4
Si l’expression est invariante par permutation circulaire des 5 variables alors cela signifie que les 5 résultats donnés par Hidevront être identiques, et donc que les 5 racines x1, x2, x3, x4, x5, x5 sont identiques, ce qui n’est évidemment pas le cas en général.
La fonction que l’on cherche ne peut pas être invariante pour une permutation circulaire de ses 5 variables.
De même la fonction ne peut pas être systématiquement invariante pour toutes les permutations circulaires de 3 variables : en effet, si l’on reprend l’exemple de Hi(x1, x2, x3, x4, x5, x5) = troisième variable = x3, et que l’on permute circulairement x1, x2, x3 pour donner x3, x1, x2 alors Hi(x3, x1, x2, x4, x5) = x2, puisque x2 est devenu la troisième variable.
Existe-t-il une expression de 5 variables, élaborée à partir d’une combinaison algébrique des 5 polynômes symétriques de ces 5 variables, telles que son expression puisse se simplifier par calcul littéral (c’est-à-dire enchaînement des opérations de calcul formel) pour se réduire finalement à une seule des 5 variables, sachant que cette fonction ne pourra pas être invariante pour une permutation circulaire de ses 5 variables et qu’elle ne sera pas non plus systématiquement invariante pour les permutations circulaires de 3 variables?
Cette question est une reformulation du problème de départ, et sa réponse est non, comme le montre la suite.
2- Forme générale de l’expression recherchée
La combinaison des opérateurs +, -, /, * pour construire l’expression recherchée va faire appel à des sommes de polynômes rationnels Cki avec des radicaux de différents ordres de la forme Σ Dij*nij√Ψ, avec Ψ lui-même aussi de cette forme c’est-à-dire somme de polynômes rationnels Cxyavec des radicaux de différents ordres de la forme Σ Dxy*nxy√Z. Cela aboutira à la forme suivante (6) :
x1 = H1(x1, x2, x3, x4, x5, x5) =
avec : nki entiers, Bi, Cki et Dij des polynômes rationnels des coefficients ai de l’équation (1). Ces polynômes peuvent donc s’exprimer à partir de combinaisons des 5 polynômes symétriques vus au début de la démonstration.
3- Analyse des radicaux les plus internes :
Considérons les radicaux les plus interne de la formule (termes entourés en rouge dans la formule du paragraphe précédent). Les plus internes signifie qu’ils ne contiennent plus d’autre radicaux dans leur expression, la fonction mise sous le radical s’expriment donc seulement sous forme de polynômes rationnel des coefficients ai de l’équation (1).
Désignons par Y le radical n√P de l’un d’eux :
Tout d’abord un tel radical existe forcément dans la formule que l’on cherche, car sinon cela signifierait que Hi est une fonction purement rationnelle des coefficients aide l’équation 1, et donc son expression serait purement symétrique des racines xi ce qui ne pourrait alors produire qu’une seule valeur, indépendante des permutations d’indices. Il n’y aurait qu’une seule valeur de racine possible, or la formule doit en donner 5.
Le terme P de ce radical est quant à lui forcément une expression construite à partir des coefficients ai de l’équation (1), sans radicaux internes, par définition de Y. Donc à ce stade P est purement symétrique par rapport aux racines (puisque les ai le sont). P s’exprimera donc par une fonction symétrique de ces racines, que l’on note sous la forme F(x1, x2, x3, x4, x5).
Et on notera 𝜑 (x1, x2, x3, x4, x5) la racine nième de F :
F est symétrique, c’est à dire qu’elle conserve la même expression, quel que soit la permutation de variable que l’on applique. Mais la fonction 𝜑 , elle, ne peut pas être totalement symétrique par rapport aux xi car sinon cela impliquerait qu’elle soit une fonction des polynômes symétriques de base présentés en (5) et donc qu’elle s’exprime directement sous la forme d’une fonction rationnelle des coefficients ai (on démontre en effet que toute fonction symétrique d’ordre 5 est forcément une combinaison des 5 polynômes symétriques d’ordre 5 de base). Cela impliquerait que n√P s’exprime directement comme une fonction des polynômes symétriques de base et donc qu’elle s’exprime directement en fonction rationnelle des coefficients ai. Autrement dit le terme Y pourrait être exprimé à l’aide des coefficients ai sans avoir besoin d’utiliser de radical, et donc Y ne serait pas le radical le plus interne de la formule.
Les valeurs de F et de 𝜑n ne sont pas modifiées par une permutation quelconque des xi, F et 𝜑n sont des expressions dans lesquelles tous les xi se comportent de la même façon et ne peuvent pas être discriminés dans l’algorithme de calcul littéral (l’application du même algorithme de calcul sur F donne toujours le même résultat formel même quand on échange n’importe quel xi avec n’importe quel xj). Mais dans le même temps 𝜑(x1, x2, x3, x4, x5) ne peut pas être totalement symétrique et son expression littérale change sous l’effet d’au moins une permutation, par exemple entre x1 et x2.
Pourquoi y a-t-il forcément un changement de valeur (et d’expression littérale) pour une permutation entre seulement 2 termes xi ? On pourrait penser que la dissymétrie n’apparait qu’avec une permutation circulaire d’ordre 3 ou 4 ou 5, et qu’il n’y en a pas pour 2, mais non car toute permutation circulaire d’ordre 3 ou 4 ou 5 se décompose en une succession de permutations entre 2 couples de xi, ce qui impose de faire déjà apparaitre la dissymétrie à la suite d’une permutation entre 2 racines.
Plus fort, si à partir de F qui est symétrique, on a trouvé un procédé de calcul tel qu’à partir de la permutation par exemple de x1 et x2, on produit une dissymétrie sur 𝜑, c’est-à-dire tel que les expressions suivantes (et les valeurs qui en découlent lorsque l’on remplace les variables xi par leur valeur) vérifient :
alors le même procédé appliqué à n’importe quel autre couple produira le même effet puisque toutes les variables ont le même comportement et sont indistinctes dans P et que donc tous les couples de variables ont aussi le même comportement, les mêmes propriétés et sont indistincts dans P. Cela signifie que toute permutation de 2 variables xi, xj donnera 2 valeurs différentes associées à 2 expressions différentes.
Ce que nous reformulons de la façon suivante :
Pour toute permutation ‘’permut’’ entre 2 des 5 variables (x1, x2, x3, x4, x5)
Raisonnons maintenant sur une permutation entre x1 et x2, sachant que le raisonnement sera applicable à toutes les autres permutations :
Ce résultat signifie que l’algorithme de calcul de 𝜑 est tel que lorsque l’on échange les 2 premières variables du quintuplet de départ, l’expression résultante par 𝜑 = α fois l’expression par 𝜑 du quintuplet de départ, en l’occurrence (x1, x2, x3, x4, x5). Cela signifie donc aussi qu’en partant cette fois du quintuplet (x2, x1, x3, x4, x5) l’algorithme de calcul de 𝜑 appliqué à (x1, x2, x3, x4, x5) donnera comme expression résultante α fois l’expression par 𝜑 de (x2, x1, x3, x4, x5). C’est-à-dire :
𝜑 (x1, x2, x3, x4, x5) = α 𝜑(x2, x1, x3, x4, x5) avec le même α
Si l’explication à partir de l’algorithme de calcul ne vous suffit pas pour accepter ce résultat, nous pouvons voir la question sous un autre angle : reprenons la formule 𝜑(x2, x1, x3, x4, x5) et changeons partout dans cette formule x2 par y1, x1 par y2, x3 par y3, x4 par y4, x5 par y5 . On a donc :
𝜑(x2, x1, x3, x4, x5) = 𝜑(y1, y2, y3, y4, y5)
Et en appliquant maintenant sur F(y1, y2, y3, y4, y5) et 𝜑(y1, y2, y3, y4, y5) les mêmes procédés de calcul que ceux décrits précédemment pour F(x2, x1, x3, x4, x5) et 𝜑(x2, x1, x3, x4, x5) on aura bien.
En conclusion α2 = 1, c’est à dire α = +/-1. D’où un premier résultat remarquable : le radical le plus interne qui se trouve dans la solution générale d’une équation polynomiale résoluble par voie algébrique est forcément une racine carrée. Et c’est bien ce que l’on constate non seulement dans le cas évident de l’équation du second degré, mais aussi dans ceux des équations du troisième et du quatrième degré.
Notre premier Y en général peut donc prendre deux valeurs opposées +𝜑1 et – 𝜑1. La première valeur, que l’on choisit arbitrairement de noter +𝜑1, correspond à l’expression de Y sous la forme 𝜑(x1, x2, x3, x4, x5) dans laquelle on remplacerait chaque xi par sa valeur, et la seconde valeur – 𝜑1 correspond à l’expression de Y sous la forme 𝜑(x2, x1, x3, x4, x5) dans laquelle on remplacerait chaque xi par sa valeur. Et cela s’applique à toute paire de racines.
De façon plus précise, nous avons démontré que Y = √P où P est exprimé à partir des coefficients ai de l’équation (pour rappel P(a1, a2, a3, a4, a5) = F(x1, x2, x3, x4, x5). Nous savons que P est invariant pour toute permutation des racines xi. Y ne peut donc prendre que 2 valeurs, notées +𝜑1 et – 𝜑1 quelle que soit la permutation considérée. Ces 2 seules valeurs sont aussi le résultat de 2 expressions différentes qui découlent l’une de l’autre en permutant seulement deux racines données :
𝜑(x1, x2, x3, x4, x5) = +𝜑1 = √P
𝜑(x1, x2, x3, x4, x5) = -𝜑1 = -√P
Et cela s’applique à toute paire de racines.
Pour une autre paire de racine, par exemple x3 et x1, les permutations entre xi et xj dans l’expression 𝜑(x1, x2, x3, x4, x5) ne donneront pas d’autre valeur que : soit +𝜑1 soit -𝜑1. En effet, 𝜑(x3, x2, x1, x4, x5) = +/- F(x1, x2, x3, x4, x5) = +/- √P = +/- 𝜑1.
Pour toute permut de 2 racines, 𝜑 (permut (x1, x2, x3, x4, x5)) = -𝜑1 = 𝜑(x1, x2, x3, x4, x5)
Conséquence :
𝜑 (x1, x2, x3, x4, x5) ne changera pas de valeur (ni d’expression) lorsque l’on effectuera une permutation circulaire de trois racines (une permutation où, par exemple, x1, x2, x3 devient x2, x3, x1 ou x3, x1, x2), car une telle permutation équivaut à la succession de deux échanges de deux racines, et donc à un double changement de signe.
x1, x2, x3 devient x2, x1, x3 après le premier échange, puis x2, x1, x3 devient x2, x3, x1 après le deuxième échange.
𝜑(x2, x3, x1, x4, x5) = 𝜑(x3, x1, x2, x4, x5) = 𝜑(x1, x2, x3, x4, x5), égalités valables en valeur et en expression.
De même, les permutations circulaires d’ordre 5 sont la combinaison de 4 échanges de 2 racines, et l’on a : 𝜑(x5, x1, x2, x3, x4) = 𝜑(x4, x5, x1, x2, x3) = 𝜑(x3, x4, x5, x1, x2) = 𝜑(x2, x3, x4, x5, x1) = 𝜑(x1, x2, x3, x4, x5), égalités valables en valeur et en expression. Cela vaut pour toutes les permutations circulaires d’un nombre impair de racines.
Conclusion de l’analyse des radicaux les plus internes de la formule qui donne les racines de l’équation (1) : Tous les différents termes les plus internes de la formule sont des radicaux second (autrement dit des racines carrées) de la forme √Pi. Ces termes ne peuvent prendre que 2 valeurs différentes et ont des expressions 𝜑(x1, x2, x3, x4, x5) qui seront insensibles à des nombres pairs de permutations entre des couples de xi, c’est-à-dire qu’elles donneront toujours la même valeur lorsque l’on applique un nombre pair de permutation entre 2 variables. Par conséquent les termes les plus internes s’expriment sous la forme √Pidont l’expression à l’aide des racines est 𝜑(x1, x2, x3, x4, x5) et cette expression est telle que les permutations circulaires de trois ou cinq racines, ne changent pas la valeur de ce terme.
4- Analyse des radicaux qui contiennent les radicaux les plus internes :
4-1) Analyse générale :
On s’intéresse maintenant aux radicaux de niveau supérieur aux radicaux les plus internes (cf expressions entourées en rouge).
Posons Q = Cij + Σ Dij*nki√Pki et Z = nkx√Q
Z est donc un radical qui contient un radical le plus interne. Dans le paragraphe précédent nous avons vu que nki√Pki est en fait : √Pki = 𝜑 (x1, x2, x3, x4, x5) avec 𝜑 fonction rationnelle des racines invariante pour toute permutation circulaire de 3 ou 5 racines.
Tous les éventuels autres radicaux nkj√Pkj qui interviennent dans la somme Σ Dij*nki√Pki sont aussi forcément des racines secondes car sinon cela signifierait qu’ils contenaient un radical dans l’expression de P, et que donc le terme le plus interne n’était pas celui que l’on a défini au paragraphe 3. Comme ils n’en contiennent pas, le raisonnement du paragraphe 3 s’applique, nkj√Pkjest donc aussi une racine seconde, son expression ne peut donner que 2 valeurs, et la valeur produite par cette expression sera invariante pour toute permutation de 3 ou 5 racines.
Les différents termes √Pkjsont combinés avec des termes Dij entièrement symétriques (puisque combinaisons de ai), sommés entre eux et finalement ajouté à Cij qui est aussi entièrement symétrique car combinaison de ai. Cela permet d’affirmer que Q aura une expression qui donnera la même valeur pour toute permutation de 3 ou 5 racines.
A ce stade nous avons donc Z = nkx√Q où Q est une fonction rationnelle des racines, invariante pour toute permutation de 3 ou 5 racines.
4-2) Cas ni= 2 :
Si ni = 2 alors la fonction Z sera encore du même genre, c’est-à-dire fonction rationnelle des racines, invariante pour toute permutation circulaire de 3 ou 5 racines, et cela continuera ainsi tant que la remontée d’un niveau à l’autre de l’expression rencontre des racines secondes (donc y compris des racines quatrièmes). Démonstration :
où √P est définit par l’expression 𝜑(x1, x2, x3, x4, x5).
On note G(x1, x2, x3, x4, x5) l’expression de Z en fonction des racines xi :
G2(x1, x2, x3, x4, x5) = C + D 𝜑(x1, x2, x3, x4, x5)
Et en notant Q(x1, x2, x3, x4, x5) = C + D 𝜑(x1, x2, x3, x4, x5),
G(x1, x2, x3, x4, x5) = +√Q(x1, x2, x3, x4, x5) ou bien -√Q(x1, x2, x3, x4, x5)
On remarque que toute permutation de 2 variables dans Q fait changer la valeur de Q, mais Q est invariante pour toute permutation circulaire de 3 ou 5 variables => Q ne prend que 2 valeurs et oscille entre ces 2 valeurs à chaque permutation.
La fonction G peut prendre 2 expressions différentes : soit avec + devant la racine, soit avec -. Nous allons montrer que quelle que soit le choix que l’on fera nous aurons toujours : G(x1, x2, x3, x4, x5) ≠ G(x2, x1, x3, x4, x5), et cela sera aussi vrai pour toute permutation de 2 variables dans G, mais G restera toujours invariante pour les permutations circulaires de 3 variables, ou 5 variables.
Montrons maintenant l’invariance pour les permutations circulaires de 3 variables.
Pour les permutations circulaires de 3 variables, considérons les permutations circulaires sur x1, x2, et x3, sachant que le raisonnement qui suit s’applique pour toute autre permutation circulaire de 3 des 5 variables. Il y a 3 permutations circulaires possible pour ces 3 variables : (x1, x2, x3, x4, x5), (x3, x1, x2, x4, x5), (x2, x3, x1, x4, x5) et le passage de l’une à l’autre se construit à partir de 2 des 3 couples de permutations suivant : échange (1,2), échange (1,3), et échange (2,3).
Construction des permutations circulaires de 3 variables à partir du couple (1,2) et (1,3)
La permutation (1,2) : fait passer de G(x1, x2, x3, x4, x5) à G(x2, x1, x3, x4, x5)
La permutation (1,3) : fait passer de G(x2, x1, x3, x4, x5) à G(x2, x3, x1, x4, x5)
On obtient ainsi la troisième permutation circulaire : G(x2, x3, x1, x4, x5).
Partons maintenant de G(x2, x3, x1, x4, x5) :
La permutation (1,2) : fait passer de G (x2, x3, x1, x4, x5) à G(x1, x3, x2, x4, x5)
La permutation (1,3) : fait passer de G (x1, x3, x2, x4, x5) à G(x3, x1, x2, x4, x5)
On obtient ainsi la deuxième permutation circulaire G(x3, x1, x2, x4, x5).
Construction des permutations circulaires de 3 variables à partir du couple (1,2) et (2,3)
La permutation (1,2) : fait passer de G(x1, x2, x3, x4, x5) à G(x2, x1, x3, x4, x5)
La permutation (2,3) : fait passer de G(x2, x1, x3, x4, x5) à G (x3, x1, x2, x4, x5)
On obtient ainsi la deuxième permutation circulaire G(x3, x1, x2, x4, x5).
Partons maintenant de G(x3, x1, x2, x4, x5) :
La permutation (1,2) : fait passer de G(x3, x1, x2, x4, x5) à G(x3, x2, x1, x4, x5)
La permutation (2,3) : fait passer de G(x3, x2, x1, x4, x5) à G(x2, x3, x1, x4, x5)
On obtient ainsi la troisième permutation circulaire : G(x2, x3, x1, x4, x5).
Construction des permutations circulaires de 3 variables à partir du couple (1,3) et (2,3)
La permutation (1,3) : fait passer de G(x1, x2, x3, x4, x5) à G(x3, x2, x1, x4, x5)
La permutation (2,3) : fait passer de G(x3, x2, x1, x4, x5) à G(x2, x3, x1, x4, x5)
On obtient ainsi la troisième permutation circulaire G(x2, x3, x1, x4, x5).
Partons maintenant de G(x2, x3, x1, x4, x5) :
La permutation (1,3) : fait passer de G(x2, x3, x1, x4, x5). à G(x2, x1, x3, x4, x5)
La permutation (2,3) : fait passer de G(x2, x1, x3, x4, x5) à G(x3, x1, x2, x4, x5)
On obtient ainsi la deuxième permutation circulaire G(x3, x1, x2, x4, x5).
Sous l’effet de la permutation (1,2), G(x2, x1, x3, x4, x5) prendra l’une des 2 expressions suivantes : +√Q(x2, x1, x3, x4, x5) ou bien -√Q(x2, x1, x3, x4, x5). De même sous l’effet de la permutation (1,3) G(x3, x2, x1, x4, x5) prendra l’une des 2 expression suivantes : +√Q(x3, x2, x1, x4, x5) ou bien -√Q(x3, x2, x1, x4, x5). Et enfin idem pour la permutation (2,3).
Il y n’a donc que 2 types de comportements possible (soit +, soit -) pour chacune des 3 permutations. Cela implique qu’au moins 2 des 3 permutations (1,2), (1,3), (2,3) auront le même comportement qui sera soit + et + , soit – et -.
Supposons que (1,2) et (1,3) aient le même comportement (- et -) :
Comme Q(x2, x1, x3, x4, x5) = Q(x3, x2, x1, x4, x5) puisque Q est invariante par permutation circulaire de 3 variables, nous obtenons : G(x2, x1, x3, x4, x5) = G(x3, x2, x1, x4, x5), ce qui donne, en permutant 1 et 3 dans les 2 expressions de l’égalité précédente :
G(x2, x3, x1, x4, x5) = G(x1, x2, x3, x4, x5) (7)
Et aussi en permutant 1 et 2 puis ensuite 1 et 3 dans cette dernière égalité :
G(x3, x1, x2, x4, x5) = G(x2, x3, x1, x4, x5) (8)
De (7) et (8) on déduit que les 3 termes G(x1, x2, x3, x4, x5), G(x2, x3, x1, x4, x5), G(x3, x1, x2, x4, x5) sont égaux. Il en serait de même si nous avions choisi (+ et +) comme comportement de (1,2) et (1,3).
Supposons maintenant que cela soit (1,2) et (2,3) qui ont le même comportement (- et -) :
G(x2, x1, x3, x4, x5) = –√Q(x2, x1, x3, x4, x5)
G(x1, x3, x2, x4, x5) = –√Q(x1, x3, x2, x4, x5)
Nous obtenons : G(x2, x1, x3, x4, x5) = G(x1, x3, x2, x4, x5) car Q invariante pout toute permutation circulaire de 3 variables, ce qui donne, en permutant 1 et 2 dans les 2 expressions de l’égalité précédente :
G(x1, x2, x3, x4, x5) = G(x2, x3, x1, x4, x5)
Et aussi en permutant 1 et 3 puis ensuite 2 et 3 dans cette dernière égalité :
G(x2, x3, x1, x4, x5) = G(x3, x1, x2, x4, x5)
On obtient de nouveau que les 3 termes G(x1, x2, x3, x4, x5), G(x2, x3, x1, x4, x5), G(x3, x1, x2, x4, x5) sont égaux. Cela serait de nouveau idem si l’on supposait que c’est (1,3) et (2,3) qui ont le même comportement.
L’invariance pour les permutations circulaires de 3 variables est démontrée.
Passons maintenant à la démonstration de l’invariance pour les permutations circulaires d’ordre 5 :
Considérons les permutations circulaires de 5 variables : (x1, x2, x3, x4, x5), (x2, x3, x4, x5,x1,), (x3, x4, x5,x1, x2,), (x4, x5 , x1, x2, x3,), et (x5, x1, x2, x3, x4). Nous allons montrer que la valeur par G de chacune d’elle est la même. La démonstration se fait en appliquant successivement 2 permutations circulaires de 3 variables sur G, en exploitant le fait que chaque permutation circulaire de 3 variables conserve la valeur de G.
Partons de G(x1, x2, x3, x4, x5), et appliquons une permutation circulaire sur (x1, x2, x3). Le résultat est G(x2, x3, x1, x4, x5) qui est = G(x1, x2, x3, x4, x5) compte tenu de l’invariance aux permutations circulaires de 3 variables.
Appliquons maintenant une permutation circulaire sur les 3 dernières variables (x1, x4, x5) pour les faire passer à (x4, x5,x1)
Le résultat devient G(x2, x3, x4, x5, x1) = G(x2, x3, x1, x4, x5) = G(x1, x2, x3, x4, x5)
De même en partant de G(x2, x3, x4, x5, x1) et en appliquant une permutation circulaire sur les 3 premières variables, puis une permutation circulaire sur les 3 dernières, on montrera G(x2, x3, x4, x5, x1) = G(x3, x4, x5, x1, x2), puis de la même façon G(x3, x4, x5, x1, x2) = G(x4, x5, x1, x2, x3), et enfin G(x4, x5, x1, x2, x3) = G(x5, x1, x2, x3, x4).
Conclusion : si le radical juste au-dessus du radical le plus interne est une racine seconde, la fonction G(x1, x2, x3, x4, x5), issue de ce radical prend 2 valeurs différentes lorsque l’on permute 2 variables, et G(x1, x2, x3, x4, x5) est invariante pour les permutations circulaires de 3 variables ou de 5 variables. Cela veut dire que G a de nouveau exactement les mêmes propriétés que la fonction Q au début de ce paragraphe. Au fur et à mesure que l’on remonte l’expression en rencontrant des racines carrées, ces propriétés sont conservées. Cela implique que dans cette remontée on doit finir par rencontrer d’autres radicaux que des radicaux seconds puisse que l’on sait que l’expression des racines que l’on cherche ne peut pas être invariante aux permutations circulaires de 5 variables.
4-2) Cas ni > 2 :
Supposons donc que la remontée des radicaux finisse par aboutir à un radical ni > 2. On peut supposer que ni est impair car le cas pair a été traité au paragraphe précédent et l’on a vu qu’il donne des expressions invariantes aux permutations circulaires de 3 ou 5 variables.
Nous notons Z ce radical, et avons Z = ni√Q où Q est une fonction rationnelle des racines, invariante pour toute permutation de 3 ou 5 racines.
On note de nouveau G(x1, x2, x3, x4, x5) l’expression de Z en fonction des racines xi.
Nous avons donc un Z qui, en soumettant les racines de l’équation à une permutation circulaire de trois, ou cinq variables, devra pouvoir prendre différentes valeurs, mais telle que l’on ait toujours Zn= Q, avec Q inchangé, puisqu’il est inchangé pour une permutation circulaire de trois, ou cinq variables.
Considérons une permutation circulaire quelconque de 3 variables, par exemple les 3 premières avec (x2, x3, x1, x4, x5) :
Gn(x2, x3, x1, x4, x5) = Q = Gn(x1, x2, x3, x4, x5) puisque Q est invariant pour une permutation circulaire de trois variables.
d’où G(x2, x3, x1, x4, x5) = αG(x1, x2, x3, x4, x5) avec α racine n-ième de l’unité. (9)
Appliquons maintenant une permutation (1,2) puis (1,3) sur chacun des termes de l’égalité précédente, et nous obtenons successivement :
De même considérons une permutation circulaire sur les trois dernières variables, par exemple x1, x2, x4, x5, x3 :
Gn(x1, x2, x4, x5, x3) = Q = Gn(x1, x2, x3, x4, x5) puisque Q est invariant pour une permutation circulaire de trois variables.
d’où G(x1, x2, x4, x5, x3) = βG(x1, x2x3, x4, x5) (14) avec β aussi racine n-ième de l’unité. Nous ne préjugeons pas à ce stade que α et β soit la même racine n-ième de l’unité.
Appliquons une permutation (3,4) puis (3,5) sur chacun des termes de l’égalité, et nous obtenons successivement :
G(x1, x2x3, x5, x4) = βG(x1, x2, x4, x3, x5)
G(x1, x2x5, x3, x4) = βG(x1, x2, x4, x5, x3) ,
et comme d’après 14 G(x1, x2, x4, x5, x3) = β G(x1, x2, x3, x4, x5) nous aurons cette fois:
Donc cette fois β3 = 1, avec β une racine n-ième de l’unité.
Dans le même temps nous savons que Gn(x1, x2, x3, x4, x5) = Q (x1, x2, x3, x4, x5) avec Q invariant par permutation circulaire de 5 variables.
Considérons maintenant une permutation circulaire quelconque de 5 variables, par exemple : (x2, x3, x4, x5, x1).
Appliquons une permutation circulaire de 3 variables sur x4, x5, x1, c’est-à-dire les 3 dernières variables.
G(x2, x3x1, x4, x5) = β2 G(x2, x3, x4, x5, x1 ) d’après (15) dans laquelle on a remplacé x1 par x2, x2 par x3, x3 par x4, x4 par x5, et x5 par x1. On a donc :
D’où β5α5 = 1, et comme β3 = 1 = α3, on en déduit β2α2 = 1, et donc βα = 1 puisque β3α3 = 1.
L’égalité βα = 1 reportée dans les égalités (17) à (21) implique que G est invariant à toute permutation circulaire d’ordre 5.
Nous allons maintenant montrer que α = 1 = β, ce qui impliquera cette fois que G est aussi invariant à toute permutation circulaire d’ordre 3.
Partons de G(x1, x2, x3, x4, x5) = G(x4, x5, x1, x2, x3) (22) par égalité des permutations circulaires d’ordre 5.
Appliquons l’égalité (14), c’est à dire G(x1, x2, x4, x5, x3) = βG(x1, x2, x3, x4, x5), en remplaçant dans cette égalité : x1 par x4, x2 par x5, x4 par x1, et x5 par x2, on obtient alors l’égalité suivante :
Comme on a, par double permutation circulaire d’ordre 5, G(x4, x5, x3, x1, x2) = G(x3, x1, x2, x4, x5), on obtient en remplaçant G(x4, x5, x3, x1, x2) par G(x3, x1, x2, x4, x5) dans (23) :
Donc βα2 = 1, et comme βα = 1, on en déduit α = 1 et β = 1.
Nous voilà donc rendu au même point qu’au début des paragraphe 4-2 ou 4-3, avec un terme Z = ni√Q où Q est une fonction invariante pour toute permutation de 3 ou 5 racines, et Z est de nouveau invariant par permutations circulaires d’ordre 3 ou 5. La remontée des radicaux ne fait jamais apparaître de terme qui ne serait pas invariant aux permutations d’ordre 5.
4-4) Conclusion :
Pour l’équation de degré 5, les radicaux rencontrés au fur et à mesure que l’on remonte dans l’expression des racines ne permettent jamais de construire une expression qui ne serait pas invariante pour une permutation circulaire d’ordre 5. La forme de la fonction que l’on cherche, c’est à dire une fonction algébrique, ne permet pas d’exprimer les racines des équations de degré 5, ni par conséquent les équations de degré supérieur.
Annexe
Réduction de l’expression de la racine d’une équation de degré 3 jusqu’à obtenir x1.
On s’intéressera aux équations de la forme X3 + pX + q = 0 (A1), sachant que toute équation de degré 3 peut se ramener à cette forme.
En notant x1x2x3 les trois racines distinctes nous avons :
p = x1x2 + x1x3 + x2x3
q = – x1x2x3
x1 + x2 + x3 = 0
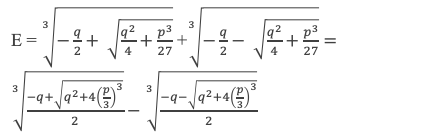
Une des racines, notons la x1, est donnée par le calcul de l’expression E suivante :
Exprimons q et q2 + 4(p/3)3 en fonction des racines :
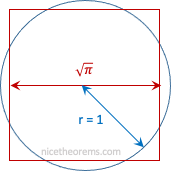
Le problème de la quadrature du cercle consiste à construire, à l’aide seulement d’une règle et d’un compas, un carré qui aurait la même aire que celle d’un disque donné (cf figure 1).
Figure 1 : le cercle de rayon 1 et le carré de côté √ π ont la même aire.
La démonstration repose sur le fait que la quadrature du cercle nécessiterait la construction à la règle et au compas de √π. Or les nombres qui sont construits à l’aide de la règle et du compas sont tous forcément solutions d’une équation polynomiale particulière (on dit de ces nombres qu’ils sont algébriques). La racine carrée du nombre π ne peut pas , elle, être la solution d’une telle équation, elle ne fait pas partie des nombres algébriques.
Histoire du théorème
La quadrature du cercle était l’un des trois grands problèmes de l’Antiquité, avec la trisection de l’angle et la duplication du cube, et a été celui qui a résisté le plus longtemps. Il a fallu plus de 3 millénaires pour finalement établir définitivement qu’il était insoluble, preuve apportée en 1882 par Ferdinand Lindemann.
Vers 1650 av. J.C. le scribe Ahmes rédige le papyrus de Rhind, En introduction du texte il indique qu’il s’agit de la copie d’une version précédente datant d’un pharaon qui vivait près de trois siècles auparavant. Dans les problèmes 48 et 50 de ce papyrus, le scribe étudie le rapport liant l’aire d’un disque à son diamètre en cherchant à ramener l’aire de la circonférence à celle d’un carré équivalent. Le papyrus Rhind précise ainsi une première approche de la quadrature du cercle : le carré de côté 8 unités a la même surface qu’un cercle de diamètre 9. Cette approximation se traduirait dans nos notations actuelles pour la surface d’un disque et d’un carré par : π×(9/2)2≃82. Ce qui correspond à une valeur de π = 3,16 .
Vers 430 av. J.C Le philosophe Anaxagore aurait énoncé (ou dessiné) la quadrature du cercle. C’est l’écrivain grec Plutarque qui le rapporte, mais il ne dit rien de plus sur la construction d’Anaxagore.
Archimède (Syracuse, 287 – ca 212 av. J.C.), dans son traité intitulé De la mesure du cercle démontre que le rapport du périmètre au diamètre du cercle est compris entre 3 + 10⁄71 et 3 + 10⁄70. A partir de ce résultat Archimède fournit une valeur (22/7) à la fois simple et suffisamment précise (≈ 3,143) pour les applications courantes.
Au moyen age l’approximation de π par 22/7 proposée par Archimède était considéré comme exacte, et la question de la quadrature du cercle ne se posait donc plus.
Ce n’est qu’avec la diffusion des traductions en latin des traités d’Archimède, au Moyen Âge tardif, que l’on réalisa que 22/7 n’était qu’une valeur approchée et que des penseurs, comme Nicolas de Cues, se remirent à la quadrature du cercle.
Au 16e siècle, Oronce Fine et Joseph Juste Scaliger croient avoir démontré la quadrature, mais Adrien Romain et le chevalier Errard de Bar le duc le contestent. Dans cette polémique, François Viète la décrète impossible. Le problème dépasse la sphère des mathématiques et l’on voit surgir des allusions à la quadrature dans des ouvrages ésotériques. Au 17e siècle, Grégoire de Saint-Vincent crut avoir résolu l’énigme de la quadrature et exposa ses solutions dans un ouvrage de 1 000 pages.
A partir du 18e siècle les recherches d’amateurs se multiplient. S’appuyant tantôt sur une construction mécanique, numérique ou une formule d’encadrement, les chercheurs prétendent qu’ils résolvent « exactement » le problème. Les communications sur ce sujet parvenaient en si grand nombre aux sociétés savantes que l’Académie des sciences de Paris décida dès 1775 de ne plus expertiser désormais ce genre de travaux : « L’Académie a pris, cette année, la résolution de ne plus examiner aucune solution des problèmes de la duplication du cube, de la trisection de l’angle ou de la quadrature du cercle, ni aucune machine annoncée comme un mouvement perpétuel. »
Même la démonstration d’impossibilité de Lindemann ne mit pas un terme à la profusion de prétendues solutions au problème.
Pour résoudre la quadrature du cercle, il fallait d’une part traduire la notion de « constructibilité géométrique » en une propriété algébrique, et d’autre part approfondir la compréhension que l’on avait des propriétés du nombre π.
Toute construction à la règle et au compas s’appuie sur un nombre fini de points donnés et consiste à construire en un nombre fini d’étapes de nouveaux points par intersection de deux droites, de deux cercles, ou d’une droite et d’un cercle. La traduction de ce procédé en langage algébrique s’opère par l’emploi d’un système de coordonnées, qui est l’idée fondamentale de la géométrie analytique imaginée au 17e siècle par Pierre de Fermat et René Descartes. Avec un tel système, il est possible de raisonner sur les droites et cercles par leurs équations : les points d’intersection à construire deviennent les solutions d’équations algébriques à calculer. On trouve ainsi que les segments exactement constructibles à la règle et au compas ne sont autres que les nombres obtenus à partir de l’unité par un nombre fini d’opérations arithmétiques (addition, soustraction, multiplication et division) et d’extractions de racines carrées. En particulier, un tel nombre est algébrique, c’est-à-dire solution d’une équation algébrique de degré arbitraire à coefficients rationnels. Les nombres non algébriques sont dits transcendants et ne sont pas constructibles.
C’est en 1837 que Pierre-Laurent Wantzel démontre un théorème qui permet d’exhiber la forme des équations dont sont solutions les nombres constructibles à la règle et au compas : les nombres constructibles sont les nombres rationnels et les racines de certains polynômes de degré 2n à coefficients entiers (plus précisément les éléments d’une tour d’extensions quadratiques) ; les nombres constructibles font donc partie de l’ensemble des nombres algébriques (qui sont les racines de polynômes de degré fini quelconque à coefficients entiers).
Ferdinand von Lindemann parvint finalement à démontrer en 1882 que π n’est pas algébrique, autrement dit qu’il est transcendant ; qu’en conséquence, on ne peut construire à la règle et au compas un segment de longueur π et donc, que la quadrature du cercle est impossible.
Lindemann s’appuya pour cela sur un résultat du mathématicien français Charles Hermite. Ce dernier avait démontré en 1873 que le nombre e est transcendant
Boîte à outils
1. Points constructibles :
Qu’entend-on par construire un point, une droite, un cercle, un carré, un nombre ? Le concept mathématique de « construction » peut être fondé sur une définition par récurrence :
– le point O et le point I situé à une distance unité de 0, sont des points constructibles. Ils constituent les 2 points de départ de la construction.
– une droite est constructible si et seulement si elle passe par deux points constructibles.
– un cercle est constructible si et seulement si son centre est un point constructible et son rayon est la distance entre deux points constructibles.
– tout point du plan est un point constructible si il est intersection de deux ensembles de points constructibles (droite ou cercle)
Autrement dit, si E désigne un ensemble fini de points du plan, on considère l’ensemble P des droites joignant deux de ces points, ainsi que des cercles centrés en l’un de ces points et de rayon la distance entre deux de ces points. On appelle « points construits à partir de E à la règle et au compas » l’ensemble des intersections des éléments de P.
Un point M du plan est alors dit « constructible » s’il existe une suite de points M1, M2, … , Mn avec Mn = M telle que pour tout i < n, Mi soit un point construit à partir de l’ensemble {O, I,M1, . . . ,Mi−1}.
Un réel x est dit « constructible » s’il est l’abscisse ou l’ordonnée d’un point constructible. De manière équivalente, x est constructible s’il est l’abscisse d’un point constructible de l’axe (OI). En effet, si M est constructible, alors le cercle de centre O passant par l’ordonnée de M coupe l’axe des abscisses en un point qui devient constructible. L’axe OI contient l’ensemble des coordonnées des points constructibles (abscisses et ordonnées).
2. Exemples de constructions :
– Construction d’un repère orthonormé O, I, J à partir des points de départ O et I: pour cela on construit le point K symétrique de I par rapport à O (intersection de la droite (OI) et du cercle C de centre O et de rayon OI).
Ensuite, à partir des intersections A et B des 2 cercles de même rayon, l’un centré sur O l’autre sur I, l’axe (OJ) comme médiatrice du segment [IK].
Le point J est alors intersection de cet axe avec le premier cercle de rayon OI déjà construit.
– Construction d’une droite parallèle à une droite (AB) et passant par un point C : On construit le quatrième point D du parallélogramme ABCD en traçant un arc de cercle de centre C et de rayon AB, et un arc de cercle de centre B et de rayon AC.
– Si a et b sont deux nombres constructibles, il en est de même pour leur somme, ou de leur différence :
– Si a et b sont 2 nombres constructibles, il en est de même pour leur produit ou leur rapport (or cas du point 0 évidemment).
Nous avons vu précédemment comment construire une parallèle à une droite donnée passant par un point donné. Pour l’obtention du produit ab, on construit le quatrième sommet C du parallélogramme de sommets A(0, a), J (0, 1) et B(b, 0). Grâce au théorème de Thales, ab est donné par l’intersection de la droite AC avec l’axe OI. Pour l’obtention du rapport a/b, on construit le quatrième sommet C du parallélogramme de sommets A(0, a), B (0, b) et I(1, 0). Grâce au théorème de Thales, a/b est donné par l’intersection de la droite AC avec l’axe OI.
– Construction de la racine carrée d’un nombre a. La figure suivante montre comment le point M construit à partir du cercle C de diamètre a + 1 et de centre (a-1)/2 a pour ordonnée √a. En effet comme M est sur le cercle C, le triangle qu’il forme avec les points K d’abscisse −1 et A d’abscisse a est rectangle en M. Les triangles AOM et KOM sont donc semblable, et l’on obtient :
OK / OM = OM / OA, soit OM2 = a
On voit qu’avec les procédés présentés on peut contruire, à partir de nombres rationnels, des nombres assez élaborés, par exemple de la forme :
3. La croissance de (p-1)! est supérieure à celle de xp :
Pour tout x on a, à partir d’un certain rang, c’est-à-dire pour tout entier supérieur à p0 : (p-1)! > xp
Démonstration :
Le résultat est trivial pour x ≤ 1, on s’intéresse donc à x > 1 et on note h = arrondi de x à sa valeur supérieure + 1 ce qui garantit h > x. Prenons p0 = 2*h2+ 1.
Dans ce produit tous les termes (p-1) jusqu’à (p–i) sont ≥ p0 et p0 lui-même est > x , donc :
(p-1)! > xi*xp0 = xp
4. Les polynomes symétriques :
4-1 Définition : Un polynôme Q(a1, …, an) en n indéterminées est dit symétrique si pour toute permutation s de l’ensemble d’indices {1, …, n}, l’égalité suivante est vérifiée :
Q(a1, …, an) = Q(as(1), …, as(n))
Par exemple :
Pour n = 2 : le polynôme a1 + a2 est symétrique alors que le polynôme a1 + a22 ne l’est pas.
Pour n = 3 : les polynômes a1a2a3 ou (a1 – a2)2(a1 – a3)2(a2 – a3)2 sont symétriques.
Polynômes symétriques élémentaires : On appelle polynôme symétrique élémentaire en n variables les polynômes qui sont la somme de tous les produits de k d’entre ces n variables. Nous notons PSk(a1, …, an) ces polynômes. Exemples de ce type de polynômes :
PS2(a1, …, an) = Σaiaj avec i et j compris entre 1 et n, et i < j.
Pour n = 3 : PS2(a1, a2, a3) = a1a2 + a1a3 + a2a3
Pour n = 2 : PS2(a1, a2) = a1a2
PS3(a1, …, an) = Σ ai aj ak avec i, j, k compris entre 1 et n, et i < j < k.
Pour n = 3 : PS3(a1, a2, a3) = a1a2a3
Pour n = 4 : PS3(a1, a2, a3, a4) = a1a2a3 + a1a2a4 + a1a3a4 +a2a3a4
Pour n = 4 : PS1(a1, a2, a3, a4) = a1 + a2 + a3 + a4
4-2 Propriété des polynomes symétriques :
Tout polynôme symétrique peut être exprimé comme une combinaison algébrique de polynômes symétriques élémentaires, et plus précisément sous la forme d’un polynôme dont les variables sont des polynômes symétriques élémentaires. Ce résultat joue un rôle clé pour faire aboutir les calculs détaillés en annexe.
Par exemple, considérons le polynôme symétrique Q suivant qui n’est pas élémentaire :
Nous avons tout d’abord besoin d’introduire la notion de monômes d’un polynôme. Le développement d’un polynôme Q(a1, a2, a3 … an), c’est-à-dire la suppression de toutes les factorisations, conduit à l’exprimer sous la forme d’une somme de termes de la forme A*a1m1a2m2a3m3 … anmn. où A est un coefficient. Ces termes sont appelés monômes. Par exemple :
Les termes : a13, a12a2, -5a12, -10a1a3, et -20a32 sont les monômes de Q.
L’ensemble des exposants (m1, m2, m3 …, mn) des monômes A*a1m1a2m2a3m3 … anmn peut être ordonné suivant un ordre appelé l’ordre lexicographique. On écrira :
a1m1a2m2a3m3 … anmn > a1p1a2p2a3p3 … anpn si pour le premier i tel que mi ≠ pi, on a mi > pi. Par exemple, avec le polynôme Q précédent les exposants des monômes sont (3,0,0) pour a13, (2,1,0) pour a12a2 , (2,0,0) pour a12, (1,0,1) pour a1a3, et (0,0,2) pour a32. On écrira donc :
a13 > a12a2 > a12 > a1a3 > a32
Nous pouvons maintenant passer à la démonstration de la décomposition d’un polynôme symétrique en polynômes symétriques élémentaires.
Soit P(a1, a2, a3 … an) un polynôme symétrique non nul, et A*a1m1a2m2a3m3 … anmn son monôme le plus grand (au sens de l’ordre lexico graphique défini auparavant. Procédons par récurrence sur les ordres des monômes de P. Pour cela supposons que la propriété de décomposition d’un polynôme symétrique en polynômes symétriques élémentaires soit vraie pour tout polynôme symétrique dont le monôme le plus grand est strictement inférieur à a1m1a2m2a3m3 … anmn. Alors nous allons voir qu’elle devient aussi vraie pour A*a1m1a2m2a3m3 … anmn.
Puisque P est symétrique, il contient, affectés d’un même coefficient non nul, tous les monômes obtenus en permutant les exposants dans le monôme le plus grand A*a1m1a2m2a3m3 … anmn.
Par exemple, pour n = 4, si P est symétrique et contient le monômes 5a1a22a33 a44 alors il contient alors forcément 5a2a12a33 a44 , ou 5a2a32a13 a44 ou … 5a14a23a32 a31 et son ordre le plus grand est au moins (4,3,2,1).
D’une façon générale si le polynôme est symétrique et contient un monôme de la forme A*a1p1a2p2a3p3 … anpn alors il contiendra un monôme de la forme A*a1m1a2m2a3m3 … anmn construit à partir de a1p1a2p2a3p3 … anpn en permutant les variables de ce monôme pour mettre le plus grand exposant sur a1 puis le suivant sur a2, puis etc. Cela permet d’affirmer que le monôme le plus grand A*a1m1a2m2a3m3 … anmn vérifie :
m1 > m2 >m3 … > mn
Posons ri = mi – mi+1 pour 1 ≤ i < n, et rn = mn. Les ri sont tous positifs ou nuls.
Notons bien que le monôme maximal de PS1 est a1, le monôme maximal de PS2 est a1a2, le monôme maximal de PS3 est a1a2a3, …etc, et le monôme maximal de PSn est a1a2a3, … an. Etudions les exposants de a1, a2, a3 … an dans le monôme d’ordre maximal de R :
L’exposant de a1 est donné par : a1r1a1r2a1r3 … a1rm = a1m1–m2a1m2–m3a1m3–m4… a1mn-1–mna1mm = a1m1
L’exposant de a2 est donné par : a2r2a2r3 … a2rm = a2m2–m3a2m3–m4 … a2rm = a2m2
L’exposant de a3 est donné par : a3r3 … a3rm = a3m3–m4 … a3rm = a3m3
…
L’exposant de anest donné par : anrm
P et R ont donc le même monôme maximal et donc le polynôme symétrique P – R est nul ou a un monôme maximal strictement inférieur à celui de P.
Si P – R est nul, alors cela signifie que P = R : il est donc bien construit à partir des polynômes symétriques élémentaires.
Si P – R n’est pas nul, alors le polynôme W = P – R est un polynôme symétrique d’ordre maximal strictement inférieur à a1m1a2m2a3m3 … anmn , il est donc par hypothèse de la récurrence construit à partir des polynômes symétriques élémentaires, et donc P = W + R l’est aussi.
Ce raisonnement, appliqué de proche en proche à la succession ordonnée des monômes maximaux des polynômes symétriques permet de conclure qu’un polynôme symétrique peut toujours être décomposé en polynômes symétriques élémentaires.
Les éléments clés de la démonstration
1ère étape :
Nous montrerons que les nombres qui sont construits à l’aide de la règle et du compas sont forcément solutions d’une équation polynomiale à coefficients rationnels. C’est à dire une équation de la forme :
a0 + a1x + a2x2 + … akxk + … + am xm = 0, avec m entier et qi nombres rationnels.
2ème étape :
Dans un premier temps nous montrerons que π ne peut pas être solution d’une équation polynomiale à coefficients rationnels. C’est dans cette partie que réside l’essentiel de la difficulté. La démarche qui va permettre de le démontrer se décompose en 3 phases :
1- Nous faisons l’hypothèse que π est solution d’une équation polynomiale à coefficients rationnels. Cela signifie qu’il existe un polynôme noté T(x) tel que T(π) = 0 . En travaillant un peu ce polynôme nous le ramènerons à un polynôme P(x) n’ayant que des coefficients en nombre entiers, et tel que P(i π) = 0 , avec i imaginaire racine de -1.
2- A partir des racines de ce polynôme à coefficients entiers nous allons construire un autre polynôme, plus complexe, de degré plus élevé, qui sera noté F(x). Ce polynôme permet de créer un nombre J qui aurait d’étranges propriétés.
3- Les propriétés sont si étranges qu’elles donnent des résultats contradictoires. J est forcément supérieur à nombre J1 et en même temps J est forcément inférieur à un nombre J2 tout cela avec J2 supérieur à J1. Ces résultats contradictoires prouvent que ce polynôme ne peut pas exister, et que donc l’hypothèse de départ qui dit que π est constructible (donc algébrique) est fausse. En fait π est transcendant.
Il est alors très simple de montrer que π étant non constructible et même transcendant, √π l’est aussi forcément. Un carré d’aire identique à un cercle de rayon 1, c’est à dire un carré d’aire π et donc de côté √π n’est pas constructible à la règle et au compas.
Démonstration de l’impossibilité de la quadrature du cercle
Etape 1: il s’agit de montrer que si un nombre est constructible alors il est solution d’une équation polynomiale à coefficients rationnels.
Soit M un point constructible. Il existe une suite de points du plan M1, M2, … , Mn avec Mn = M telle que pour tout i ≤ n, Mi soit un point construit à partir de l’ensemble des points {O, I, M1, . . , Mi−1}.
A chaque point Mi on va associer l’ensemble Ki de tous les nombres réels que l’on peut former par addition, soustraction, multiplication, division, à partir des coordonnées des points Mi, Mi-1, … M2, M1, I, O. Par exemple, à partir des points de départ O et I on peut générer de cette façon l’ensemble K0 = Q ensemble des nombres rationnels. A la succession des points Mi est ainsi associé une succession d’ensembles Ki telle que Ki ⊆ Ki+1.
Les coordonnées de M = Mn sont par définition dans Kn.
Tout point Mi est construit à partir des points précédents M1,M2, … , Mi-1, c’est-à-dire qu’il est l’intersection soit :
de 2 droites passant chacune par 2 de ces Mi-1 points,
d’une droite passant par 2 de ces Mi-1 points et d’un cercle centré en l’un de ces Mi-1 points et de rayon la distance entre deux de ces Mi-1 points.
de 2 cercles centrés chacun en l’un de ces Mi-1 points et ayant pour rayon la distance entre deux de ces Mi-1 points.
Lemme 1: Les coordonnées de Mi (xi, yi) étant dans Ki, ces coordonnées sont soit déjà dans Ki-1, soit solutions d’une équation polynomiale de degré 2 à coefficients dans Ki-1. En effet :
1) Cas de l’intersection de 2 droites : on pose P1(a1, b1) et R1(c1, d1) les points définissant la première droite, et P2(a2, b2) et R2(c2, d2) les points définissant la seconde. Les coordonnées a, b, c, d sont dans Ki-1.
L’équation de la première droite est : Y = (d1 – b1) / (c1 – a1) (X – a1) + b1
L’équation de la seconde droite est : Y = (d2 – b2) / (c2 – a2) (X – a2) + b2
Le point d’intersection entre les 2 droites est solution d’un système de 2 équations à 2 inconnues, dont les coefficients sont dans Ki-1. Le résultat est issu d’additions, soustractions, multiplications sur ces coefficients, il sera forcément dans Ki-1.
On est dans le cas où les coordonnées de Mi (l’abscisse comme l’ordonnée) sont déjà dans Ki-1, c’est-à-dire que Ki = Ki-1.
2) Cas de l’intersection d’une droite et d’un cercle : On pose P1(a1, b1) et R1(c1, d1) les 2 points définissant la droite, P2(a2, b2) le centre du cercle, et r son rayon. a1, b1, c1, d1, a2, b2, et r sont donc dans Ki-1.
L’équation de la droite est. : Y = (d1 – b1) / (c1 – a1) (X – a1) + b1. (1)
L’équation du cercle est : (X – a2)2 + (Y – b2)2 = r. (2)
En remplaçant Y par (d1 – b1) / (c1 – a1) (X – a1) + b1 dans l’équation (2) du cercle, on en déduit que X est solution de (X – a2)2 + [(X – a1)(d1 – b1) / (c1 – a1) + b1 – b2]2 = r. Donc X est solution d’une équation de degré 2 dont les coefficients sont dans Ki-1. X s’écrira sous la forme X = Ax + Bx√D avec Ax, Bx, et D appartenant à Ki-1. De même Y est solution d’une équation de degré 2, et en vertu de (1) Y s’écrit sous une forme identique à X à savoir Y = Ay + By√D avec Ay, By, et D appartenant à Ki-1. On notera que l’extension en √D est la même pour X et Y.
3) Cas de l’intersection de 2 cercles : On pose P1(a1, b1), P2(a2, b2) les centres des 2 cercles, et r1respectivement r2 les rayons. a1, b1, a2, b2, r1, r2, sont dans Ki-1.
L’équation du premier cercle est. : (X – a1)2 + (Y – b1)2 = r1 (1)
L’équation du second cercle est : (X – a2)2 + (Y – b2)2 = r2. (2)
En soustrayant (2) à (1), le système d’équation équivalent s’écrit :
On retrouve un système d’équation du même type que lors de l’intersection d’une droite et d’un cercle. La conclusion sera la même : X et Y sont chacun solution d’une équation de degré 2 dont les coefficients sont dans Ki-1 et X et Y s’écrivent sous la même forme Ax + Bx√D pour X et Ay + By√D pour Y avec Ax, Bx, D, Ayet By appartenant à Ki-1.
Le lemme 1 est démontré.
La conséquence du lemme 1 est que pour tout x de Ki, soit x appartient à Ki-1 (si Ki = Ki-1 c’est-à-dire que Mi est construit par l’intersection de 2 droites), soit x s’exprime sous la forme x = x1 +x2√∆i avec x1, x2 et ∆i appartenant à Ki-1. En effet si Mi est construit comme l’intersection d’une droite et d’un cercle, ou de 2 cercles, alors les coordonnées de Mi (l’abscisse, comme l’ordonnée) auront tous les deux la même forme avec une extension en √∆i. Donc tous les nombres générés à partir des coordonnées de Mi soit par addition, soustraction, multiplication, division auront aussi cette forme car :
Lemme 2: soit Ki l’ensemble associé à Mi et Ki-1 associé à Mi-1. Si x est solution d’une équation polynomiale de degré p à coefficients dans Ki, alors x est solution d’une équation polynomiale de degré p ou 2p à coefficients dans Ki-1.
Démonstration : nous supposons donc que x est solution de l’équation :
P(X) = a1 + a2X + a3X2 +… + ap-1Xp-1 + apXp = 0, avec a1, a2, … , ap-1 , ap coefficients dans Ki. et ap non nul.
Si Ki = Ki-1 nous sommes dans le cas trivial où le lemme est vrai et l’équation a pour degré p.
Si Ki ≠ Ki-1 tous les ai s’écrivent sous la forme : ai = ai1 + bi2 √∆i avec ai1, bi2, et ∆i ϵ Ki-1. En remplaçant les ai par ai1 + bi2 √∆idans l’équation P(X) = 0 on obtient : P1(X) + P2(X) *√∆i = 0 avec P1(X) et P2(X) deux polynômes de degré p (au moins pour l’un d’entre eux) et à coefficients dans Ki-1. D’où :
P1(X)2 – P2(X)2∆i = 0
x est solution de ce polynôme dont tous les coefficients appartiennent à Ki-1 et qui est de degré 2p (le terme de degré 2p s’écrit ap12 – bp12∆i qui ne peut s’annuler que si ap1 = bp1√∆i puisque ap est non nul, et ap1 = bp1√∆i signifierait que √∆i appartient à Ki-1 et que donc Ki = Ki-1 ce qui ne correspond pas à l’hypothèse).
Revenons maintenant au point M = Mn, et à la suite des points M1, M2, … , Mn-1 qui ont permis de le construire. A cette succession de points est associée la succession des ensembles K0, K1, K2, … , Kn-1.
D’après le lemme 1, comme le point M est constructible, ses coordonnées sont soit dans Mn-1, soit solutions d’une équation de degré 2 à coefficients dans Mn-1.
Par le lemme 2 on en déduit que ses coordonnées sont soit dans Mn-2 soit solutions d’une équation de degré 2 ou 2*2 à coefficients dans Mn-2, puis de nouveau par le lemme 2 ses coordonnées sont soit dans Mn-3 soit solutions d’une équation de degré 2 ou 2*2 ou 23 à coefficients dans Mn-3 et ainsi de suite juste qu’à descendre par le lemme 2 au point M1 puis au point I qui correspond à K0 = Q = ensemble des rationnels. Cela qui permet de conclure que les coordonnées de M = Mn sont solutions d’une équation polynomiale de degré < 2n à coefficients dans Q.
Etape 2: il s’agit maintenant de démontrer que π (ou sa racine) n’est pas solution d’une équation polynomiale à coefficients rationnels
La démarche pour ce faire se décompose en 3 phases :
1- Nous faisons l’hypothèse que π est solution d’une équation polynomiale à coefficients rationnels. Cela signifie qu’il existe un polynôme noté T(x) tel que T(π) = 0 . En travaillant un peu ce polynôme nous le ramènerons à un polynôme P(x) n’ayant que des coefficients en nombre entiers, et tel que P(i π) = 0 , avec i imaginaire racine de -1.
2- A partir des racines de ce polynôme à coefficients entiers nous allons construire un autre polynôme, plus complexe, de degré plus élevé, qui sera noté F(x). Ce polynôme permet de créer un nombre J qui aurait d’étranges propriétés.
3- Les propriétés sont si étranges qu’elles donnent des résultats contradictoires. J est forcément supérieur à nombre J1 et en même temps J est forcément inférieur à un nombre J2 tout cela avec J2 supérieur à J1. Ces résultats contradictoires prouvent que ce polynôme ne peut pas exister, et que donc l’hypothèse de la phase 1 est fausse.
Commençons par la première phase de la démarche :
Hypothèse : π est solution d’une équation polynomiale à coefficients rationnels. On note T(x) ce polynôme, supposé de degré m.
T(x) = t0 + t1x + t2x2 + … tkxk + … + tmxm, et on a T(π) = 0
Les tk sont des coefficients rationnels, donc de la forme pk/bk avec pk et bk des entiers relatifs.
π sera alors aussi solution d’une équation polynomiale à coefficients entiers ; il suffit pour l’obtenir de multiplier l’équation de départ par le produit des dénominateurs des coefficients, c’est-à-dire le produit des bk. On note T1(X) ce polynôme à coefficients entier, et ck les coefficients entiers de ce polynôme.
T1(x) = c0 + c1x + c2x2 + … ckxk + … + cmxm, et on a T1(π) = 0
Le nombre (i π) pourra lui aussi être solution d’une équation polynomiale à coefficients entier. Pour la construire on part du polynôme T1(x) dans lequel on réarrange chaque monome ckxksous la forme ck/(i)k * (i x)k.
Le nouveau polynôme T2(x) avec ses coefficients de la forme ck/(i)k vérifie T2(i π) = 0
Comme 1/(i) k = 1 ou -1 ou i ou –i, les coefficients de T2(x) sont de la forme ck ou – ck ou i ck ou –i ckavec cknombre entier. Réarrangeons maintenant T2(x) en séparant d’un côté les termes à coefficient purement entier (les +/- ck), et de l’autre ceux qui sont le produit de i par un entier (les +/- i ck) :
T2(x) = T2r(x) + i T2im(x) où cette fois les coefficients de T2r et T2im sont tous des entiers purs.
On considère le polynôme P(X) défini par :
Le premier terme de ce produit est le polynôme T2(x), donc P(i π) = 0
Et l’on a par ailleurs, en développant le produit : P(x) = [T2r(x)]2 + [T2im(x)]2 qui est un polynôme à coefficients purement entiers.
On dispose donc maintenant, comme annoncé pour l’étape 1, d’un polynôme P(x) à coefficients purement entiers et tel que P(i π) = 0
Nous notons pour la suite d le degré de ce polynôme, et son développement :
P(x) = s0 + s1x + s2x2 + … skxk + … + sd xd avec les sk entiers
Ce polynôme possède d racines, dont une au moins vaut (i π). Nous noterons q1, q2, q3, … qd ces d racines, et considérerons que q1 = i π
Passons à la deuxième phase de la démarche :
Construction à partir de P(x) d’un polynôme étrange.
Nous partons du polynôme P(x) = s0 + s1x + s2x2 + … skxk + … + sdxdavec les sk entiers. Nous savons que l’on a P(i π) = 0, et les racines de ce polynôme sont notées qi.
On sait qu’avec la fonction exponentielle e, e i π = -1 donc 1 + eq1 = 0 et donc (1 + eq1) (1 + eq2) ( 1 + eq3) …(1 + eqd) = 0
Développons ce produit, et pour faciliter la compréhension faisons le pour le cas particulier où d = 5
1 + eq1 + eq2 + eq3 + eq4 + eq5 (c’est-à-dire le produit des cinq 1 plus les produits de un terme eqk avec quatre 1, il y en a 5 au total)
+ toutes les combinaisons eqk+qj (c’est-à-dire les produits de 2 termes eqk avec trois 1, il y en a 10 au total)
+ toutes les combinaisons eqk+qi+qj (c’est-à-dire les produits de 3 termes eqkavec deux 1, il y en a 10 au total)
+ toutes les combinaisons eqk+qi+qj+qp (c’est-à-dire les produits de 4 termes eqk avec un 1, il y en a 5 au total)
+ eq1+q2+q3+q4+q5
En final le produit développé est la somme de tous les termes possibles de la forme eε1.q1+ε2.q2+ε3.q3+ε4.q4+ε5.q5 avec ε1, ε2, ε3, ε4, ε5 prenant les valeurs 0 ou 1 indépendamment les uns des autres, ce qui donne 25 possibilités et au total la somme est bien composée de 25 termes, soit 32 termes.
Parmi ces 32 termes il y ceux pour lesquels ε1.q1 + ε2.q2 + ε3.q3 + ε4.q4 + ε5.q5 = 0 et qui donnent donc des 1 avec l’exponentiel (il y en a au moins un c’est le terme q1), et ceux pour lesquels l’exposant est non nul et qui peuvent s’écrire, avec l’exponentiel : eakavec ak non nul.
Revenons maintenant à notre produit de départ :
(1 + eq1) (1 + eq2) (1 + eq3) (1 + eq4) (1 + eq5) = 0, et d’après ce qui précède cette équation peut être ré-écrite en :
N + ea1 + ea2 + ea3 + ea4 + …. + + ean-1+ ean = 0, avec n = nombre de termes à exposant non nul et N = nombre total de termes à exposant nul = nombre total de termes moins ceux à exposant non nul = 25 – n ≥ 1 car nous savons que le terme eq1 a un exposant nul.
D’où l’équation dans sa forme finale : 25 – n + ea1+ ea2+ ea3+ ea4+ …. + ean-1+ ean= 0
Par le même raisonnement, quel que soit le degré d de P(X) on construira l’équation
avec ai non nul = ε1.q1 + ε2.q2 + ε3.q3 + … + εk. qk + … + εd-1.qd-1 + εd.qd , les εk valant 0 ou 1, et avec (2d – n) ≥1. Notons au passage que parmi les ai il y a q1, q2, … qd, c’est à dire les d racine du polynôme P(X). Sans que cela restreigne la généralité de la démonstration nous pouvons convenir de nommer ai = q1, a2 = q2, a3 = q3, … ad = qd, puis ad+1 = q1 + q2, ad+2 = q1 + q3, … , ad+j = une première somme de j parmi les d racines, … , an = q1 + q2 + q3 + … + qd
Nous voilà maintenant enfin en mesure de définir le polynôme étrange f(x). Ce polynôme s’écrit, par définition :
f(x) = sdnpxp-1 (x – a1)p (x – a2)p … (x – an)pavec p nombre premier qui sera judicieusement choisi plus tard.
Le degré m de f(x) est donné par: m = p – 1 + np = p(n + 1) – 1
Troisième et dernière phase: le polynôme f(x) ne peut pas exister
f(x) a été spécialement construit pour que ses dérivées successives en 0, notées f(j)(0), soient toujours nulles, jusqu’à la dérivée (p-2)ième, la (p-1)ième et les suivantes ne le sont pas. De même ses dérivées successives en ai sont toujours nulles, jusqu’à la dérivée (p-1)ième, la pième et les suivantes ne le sont pas.
Plus précisément, nous avons (le détail des laborieuses démonstrations qui le prouvent est donné en annexe) :
(3-1) Pour k < p-1, f(k)(0) = 0
(3-2) Pour k = p-1, f(p-1)(0) est entier, multiple de (p-1)!
(3-3) Pour k > p-1, f(k)(0) est entier, multiple de p!
Et aussi, pour tout ai :
(3-4) Pour k < p, f(k)(ai) = 0
(3-5) Pour k ≥ p, Σ i=1i=n f(k)(ai) est entier, multiple de p!
Ayant ces résultats en tête, calculons J défini par l’équation (3-0) suivante :
Et pour cela commençons par examiner le terme générique = intégrale de 0 à ai de eai–xf(x) dx, en effectuant une première intégration par partie :
Appliquons le même calcul d’intégration par partie, cette fois à f(1)(x), on obtiendra :
Et ainsi de suite pour f(2)(x), f(3)(x), etc … Au rang k on aura :
Et au rang m, sachant que f(m+1)(x) = 0 puisque f(x) est un polynôme de degré m :
Et au rang m+1
En faisant maintenant la somme de toutes les intégrations par partie que l’on vient de calculer, on obtient :
Ce qui permet de ré-écrire J sous la forme :
Souvenons nous de l’équation (2-1) vue à la phase 2 : 2d – n + ea1+ ea2+ ea3+ ea4+ …. + ean-1+ ean= 0. Nous avons donc
Et rappelons nous des résultats (3-1), (3-2), (3-3) qui donnent la valeur de f(k)(0) selon que k est inférieur ou supérieur à (p-1), ainsi que de (3-4), (3-5) qui donnent la valeur de f(k)(ai) en fonction de k. Il vient alors :
Avec Kientiers relatifs.
Cette dernière égalité peur être mise sous la forme : J = N1(p -1)! + N2p! , avec N1 et N2 nombres entiers relatifs, c’est à dire :
J = (p -1)! (N1+ N2p)
Les calculs menés en annexe montrent que f(p-1)(0) = (-sd )np (p-1)! ( a1a2 … an )p qui est non nul, et comme (n – 2d) est aussi non nul, l’entier relatif N1 qui est le produit de ces 2 termes sera non nul.
Comme p peut être choisi arbitrairement, on prendra p premier > | sdna1a2 … an |, | x | signifiant valeur absolue de x. Comme p est un nombre premier l’application du petit théorème de Fermat nous dit que le reste de la division de (| sdna1a2 … an |)p par p = | sdna1a2 … an | qui est un entier non nul, strictement inférieur à p. Ce choix de p permet donc de garantir que (sdna1a2 … an)p n’est pas divisible par p. Si de plus on choisit aussi p > (2d – n) alors p ne divisera pas non plus (2d – n) et donc p ne pourra pas diviser N1. Avec ce choix de p on aura toujours N1 + pN2 ≠ 0 puisque sinon cela impliquerait que p divise N1. Donc N1 + pN2 sera un entier non nul et donc | N1 + pN2 | ≥ 1.
Avec ce choix de p on aura aussi toujours: | J | = | (p-1)! ( N1 + pN2) | ≥ (p-1)! | N1 + pN2 | ≥ (p-1)! (3-6)
Conclusion : pour tout p premier > (2d – n) | sdna1a2 … an | on aura | J | ≥ (p-1)! . Cela veut dire qu’à partir d’un certain rang, pour tout nombre premier p on aura | J | ≥ (p-1)!, avec J construit conformément à l’équation (3-0) à partir du polynôme f(x) de degré p. Mais par ailleurs, avec cette même valeur de p on pourra écrire :
Et en repartant de la définition de f(x), à savoir f(x) = sdnpxp-1 (x – a1)p (x – a2)p … (x – an)p, nous aurons pour tout x de l’intervalle [0 – ai] :
Si ai ≥ 0 : |x – ai| = (ai – x) ≤ ai =|ai|
Si ai < 0 : |x – ai| = (-ai – (-x)) ≤ –ai = |ai|
Dans les 2 cas |x – ai| ≤ |ai|, ce qui permet d’écrire pour tout x de l’intervalle [0 – ai] : |f(x)| ≤ |sdnp| |aip-1| |a1p| |a2p| … |aip| … |anp|
Par ailleurs, eai – x ≤ e|ai – x| ≤ e|ai| et donc pour tout x de cet intervalle :
Avec c0 = |sdn| |a1| |a2| … |ai| … |an| qui est une constante qui ne dépend pas de p. De ce résultat on tire :
Avec d = Σ e|ai| ≥ n.
et en prenant h entier > c1d, on pourra écrire | J | ≤ c1pd ≤ c1pddp-1 ≤ hp (3-7) avec h entier qui ne dépend pas de p.
Or, comme on l’a vu au §3 de la boîte à outils, la fonction (p-1)! croît plus vite que xp quelque soit x, et à partir d’un certain rang p0, tous les p vérifient (p-1)! > xp (3-8)
Cela signifie qu’en prenant p suffisamment grand on aura :
| J | ≤ hp. (3-7)
(p-1)! > hp. (3-8)
| J |≥ (p-1)! (3-6)
Soit | J | < | J |
L’existence de f(x) aboutit à une contradiction. f(x) ne peut pas exister, et donc le polynôme P(X) dont π est racine qui sert à le construire n’existe pas non plus. π ne peut pas être la racine d’un polynôme à coefficients entiers, on dit π est un nombre transcendant. Comme il n’est pas racine d’un tel polynôme il ne peut pas être constructible.
Sachant que π n’est pas constructible, il reste à démontrer que √π ne l’est pas non plus Démonstration : Faisons l’hypothèse que √π soit constructible, alors le produit : √π √π = π le serait (cf Boîte à outils §2 qui montre comment construire le produit de 2 nombres constructibles). La contradiction prouve que √π n’est pas constructible. CQFD.
√π est d’ailleurs aussi transcendant, il ne peut pas être la racine d’un polynôme à coefficient entier. Cela se démontre aisément par l’absurde : si √π est la racine d’un tel polynôme alors à partir du polynôme R(X) dont √π est la racine on peut facilement construire un polynôme dont π sera la racine, en séparant dans R(X) les monômes d’exposants paires et celui à valeur constante (qui formeront R1(X)) et les monômes d’exposants impaires (qui formeront XR2(X) avec R2(X) ne contenant que des exposants paires).
R(√π) = 0 = R1(√π) + √πR2(√π) = S1(π) + √πS2(π), et donc π racine du polynôme S12(X) – XS22(X)
Annexe
Démonstration des relations (3-1) à (3-5)
A-1) Calcul des dérivées d’ordre j, f(j)(x) :
On note Z le produit (x – a1)p(x – a2)p … (x – an)p
f (1)(x) = sdnp [(p – 1)xp-2 Z + xp-1 Z(1)]
f (2)(x) = sdnp [(p – 1)(p – 2)xp-3 Z + 2(p – 1)xp-2 Z(1) + xp-1 Z(2) ]
f (p+r)(x) = sdnp [somme à partir de k = r+1 jusqu’à k = r+p des Cjk (p-1)!/ (p–j+k-1)! xp-j+k-1 Z(k)] avec j ≥ k, formule que l’on utilisera suivant les cas sous la forme :
f (p+r)(x) = sdnpp![somme à partir de k = r+1 jusqu’à k = r+p des (Cjk/p)/ (p–j+k-1)! xp-j+k-1 Z(k)]
ou sous la forme :
f (p+r)(x) = sdnp [somme à partir de k = r+1 jusqu’à k = r+p des Djk xp-j+k-1 Z(k)] avec j ≥ k et Djkentier.
en effet, Ckj (p-1) !/(p–j+k-1)! = j!/[k!(j–k)!]*(p-1)!/(p–j+k-1)! = j!/[k!(j–k)!] Cp-1j–k(j–k)!= j!/k! Cp-1j–k = entier Djk, car Cp-1j–k = (p-1)!/[(p–j+k-1)!(j–k)!]
A-2) Calcul des dérivées d’ordre j : f (j)(0) pour j ≤ p
En appliquant les formules du § précédent pour j < p – 1, on trouve f(j)(0) = 0
En appliquant la formule pour j = p-1, on trouve :
Z(j) = pS(j)Sp-1 +… + somme de termes de la forme Kk[(S(i1).)k1*…* (S(iu).)ku]Sp–k +… + p(p-1)(p-2)(p-3)…(p–j+1)(S(1))jSp–j
…
Z(p) = pS(p)Sp-1 + somme de termes de la forme Kk[(S(i1).)k1*…* (S(iu).)ku]Sp–k + p(p-1)(p-2)(p-3)…(1)(S(1))pS0
Tant que l’exposant k de S dans ces formules est > 0, on a Sk(ai) = 0 pour chaque ai. On en déduit que toutes les dérivées k-ième de Z pour k = 1 à p-1 vérifient Z(k)(ai) = 0 quel que soit ai, et donc que f(k)(ai) = 0 pour tout ai avec k de 1 à p-1.
A ce stade nous avons donc la collection de résultats suivants :
Que (-sd)np(a1a2 … an)p est entier, pour finaliser (3-2)
Que sdnp Z(1)(0) est entier, pour le cas k = p de (3-3)
Que f (k)(0) = p! * (nombre entier ) pour k > p pour finaliser (3-3)
Que Σ1nf(j)(ai) est multiple entier de p! lorsque j ≥ p pour finaliser (3-5)
A-4) Démonstration des 2 premiers points : (-sd)np(a1a2 … an)p et sdnp Z(1)(0) sont entiers.
Pour cela rappelons-nous d’abord de la définition des ai :
ai = e1.q1 + e2.q2 + e3.q3 + … + ek. qk + … + ed-1.qd-1 + ed.qd , les ek valant 0 ou 1 avec q1, q2, q3, … qd les racines du polynôme à coefficients entiers P(X)= s0 + s1x + s2x2 + … skxk + … + sdxd. Les d premiers ai sont les q1, q2, … , qd, les suivants sont les aide la forme (qi + qj) avec i et j différents, puis les suivants sont les ai de la forme (qi + qj + qk) avec i, j, k différents, puis etc… jusqu’à an = q1 + q2 + q3 + … + qk + … + qd-1 + qd.
Comme les qi sont les racine de P(x), P(x) s’écrit aussi, de façon équivalente :
P(x) = sd (x – q1)(x – q2) … (x – qk) … (x – qd-1)(x – qd) ce qui après développement donne :
P(x) = sdxd + sd (q1 + q2 + … + qk … + qd-1 + qd) xd-1 + sd (Σqiqj) xd-2 + sd (Σqiqjqk) xd-3 + … + sd (somme de tous les produits de k termes qi différents) xd–k + … + sd (somme de toutes les produits de d-2 termes qi différents) x2 + sd (somme de tous les produits de d-1 termes qi différents ) x +(-1)dsdq1q2 … qk … qd-1 qd
Par identification avec P(x) on tire :
sd (q1 + q2 + … + qk … + qd-1 + qd) = sd-1
sd (Σqiqj) = sd-2
sd (Σqiqjqk)= sd-3
…
sd (somme de tous les produits de k termes qi différents) = sd–k
…
(-1)dsdq1q2 … qk … qd-1 qd = s0
Avec chacun des termes si qui est un entier.
On en déduit que tous les polynômes symétriques élémentaires construits à partir des d racines qi sont de la forme : si / sd avec si et sd entiers. C’est-à-dire, en reprenant la notation vue au §4 de la boîte à outils :
Considérons maintenant le produit de tous les ai :
a1a2 … an = Π ai = Π qi* Π(qi+qj) * Π(qi+qj+qk) * … * Π(somme de k des d racines) * (q1 + q2 + … + qk … + qd-1 + qd). Ce produit est une fonction symétrique sur les d indices des racines, il s’exprime donc comme une combinaison des polynômes symétriques élémentaires PS1, PS2, PSk, … PSd. On constate également que Π ai est le produit de n termes de degré 1 car les ai sont de degré 1 lorsqu’ils sont exprimés en qi. Sachant que chaque polynôme symétrique élémentaire PSi est de degré i, cela implique que Π ai s’écrit sous la forme :
Π ai = Somme de termes (PS1)a1*(PS2)a2*…*(PSk)ak* … (PSd-1)ad-1*(PSd)ad dont chacun des vérifie la condition :
a1 + 2a2 + 3a3 + … + kak + … + (d-1)ad-1 + dad = n, où les ai sont les exposants des PSi
Conclusion : a1a2 … an = Kd / sdn avec Kd entier relatif.
Cela permet de conclure aussi : (-sd)np(a1a2 … an)p = (-sd)np(K0 / sdn)p est un entier, donc f(p-1)(0) = (-sd)np (p-1)! (a1a2… an)p est un entier multiple de (p-1)!
S(x) = xn + (Σai) xn-1 + (Σaiaj) xn-2 + ((Σaiajal) xn-3 + …+ (Σ produit de k termes ai) xn-k + (Σ produit de n-1 termes ai) x + (a1a2 … an-1an)
On a vu précédemment que a1a2 … an-1an = nombre entier / ( sd )n , de même a1 + a2 + a3 + a4 + … + an est la somme de : Σ qi + Σ (qi+qj) + Σ (qi+qj+qj) + … + (Σ k des dqi) + … + (q1+q2 +…+qk …+qd-1+qd). C’est un polynôme symétrique sur les qi, il s’exprime donc en fonction des polynômes symétriques élémentaires PSi et comme il est de degré 1 en q, il s’écrit forcément sous la forme d’un entier multiplié par PS1 puisque chaque qi est présent un nombre entier de fois dans cette somme. Donc :
a1 + a2 + a3 + a4 + … + an = entier*PS1 = K1/sd avec K1 entier.
De même Σaiaj est la somme de toutes les sommes possibles de 1 ou 2 ou 3 ou k ou…dqi (qui sont les ai) par des sommes de qi du même type mais qui donnent un résultat différent (ai doit être différent de aj), le produit résultant s’exprime forcément comme une somme de termes en Σqiqj, chacun de ses monômes est de degré 2 en q, et c’est un polynôme symétrique sur les qi. Le produit résultant est donc construit comme une somme de PS12 et de PS2. Il s’écrit forcément sous la forme : entier * (sd-1/sd)2 + entier * sd-2 / sd = K2/( sd)2 avec K2 entier.
De même Σaiajalest la somme des produits de :
– toutes les sommes possibles de qi (qui donnent les ai)
– par des sommes de qi du même type mais qui donnent un résultat différent (aj doit être différent de ai)
– par des sommes de qi du même type mais qui donnent encore un résultat différent des sommes précédentes (ak différent de aj ou ai)
Le résultat s’exprime forcément comme une somme symétrique sur les d indices des qi, et avec des termes de degré 3 en q, donc forcément à partir de PS13, PS1*PS2, et PS3.
Le produit résultant s’écrit forcément sous la forme : entier * (sd-1/sd)3 + entier * sd-2 sd-1 /(sd)2 + entier + sd-3/sd = K3/(sd)3 avec K3 entier.
Le même raisonnement tient pour tous les termes de la forme (Σproduit de k termes ai) qui constituent les coefficients du polynôme S(x) = (x – a1)(x – a2) … (x – an-1)(x – an), ce qui permet de conclure que les coefficients de ce polynôme sont tous de la forme : Ki/( sd)i avec i de 0 à n, et avec Ki entier (K0 = 1).
Ce résultat permet d’affirmer que les coefficients du polynôme Z = S(x)p sont de la forme : entier /( sd)j avec j de 0 à np. Donc tous les coefficients de sdnp Z(x) sont entiers et ce sera encore le cas pour les dérivées de sdnp Z(x) puisque la dérivée des monômes d’un polynôme ne fait que multiplier par des entiers les coefficients du monôme de départ, donc sdnp Z(1)(x) est à coefficients entier, or sdnp Z(1)(0) est l’un de ces coefficients, il est donc entier.
Les 2 premiers points ont été démontrés.
A-5) A ce stade, il ne reste à démontrer que :
f (k)(0) = p! * (nombre entier ) pour k > p pour finaliser (3-3)
Σi=1nf(j)(ai) est multiple entier de p! pour finaliser (3-5)
Considérons de nouveau S(x). Il ressort du paragraphe précédent que S(x) s’écrit :
S(x) = xn + (Σai) xn-1 + (Σaiaj) xn-2 + ((Σaiajal) xn-3 + …+ (Σproduit de k termes ai) xn–k + (Σproduit de n-1 termes ai) x + (a1a2 … an-1an)
= xn + K1/sd xn-1 + K2/(sd)2xn-2 + K3/(sd)3xn-3 + …+ Kk/(sd)kxn–k + … + Kn-1/(sd)n-1x + Kn / sdn avec Ki entier pour i de 1 à n.
Z(x) = S(x)p sera la somme des termes suivant, classés par degré décroissant :
xnp , produit des p monômes de plus haut degré xn,
K1/sdxn(p-1)+n-1 , produit de p-1 monômes de plus haut degré (xn) et du monôme de degré n-1 (K1/sd xn-1),
[K2/(sd)2+ (K1/sd)2] xn(p-1)+n-2 , produit de p-1 monômes de plus haut degré (xn) et d’un monôme de degré n-2 (K2/(sd)2 xn-2) ou de p-2 monômes de degré n (xn) avec 2 monômes de degré n-1 (K1/sd xn-1),
…
Monôme de degré k, produit de p monômes de degré respectifs δ1, δ 2, … δ ptels que δ1 + δ2 + … + δj = k, chacun de ces monômes ayant pour coefficient Kn–δi/(sd)n–δi de sorte que le monôme de degré k aura pour coefficient Dk/(sd)np-Σδi = Dk/(sd)np-k
Le terme général du polynôme Z(x) s’écrit donc pour k de 0 à np : Dk/(sd)np–k xk avec Dk entier, et la dérivée jième de ce terme sera de la forme: (k)(k-1)…(k–j+1)Dk /(sd)np–kxk–j pour j de 1 à k, et = 0 pour j > k.
Revenons à f(k)(x) pour calculer f(k)(0) avec k > p.
f (p+r)(x) = sdnpp! * [somme à partir de k = r+1 jusqu’à k = r+p des Ckp+r /p*1/(k–r-1)! xk–r-1 Z(k)]. Pour x = 0, le seul terme non nul correspond à k = r+1 ce qui donne :
f (p+r)(0) = sdnpp! * [Cr+1p+r /p Z(r+1)(0)]. Or comme on vient de le voir :
Z(r+1)(x) = (k)(k-1)…(k-(r+1)+1)Dk /(sd)np–kxk-(r+1), là encore pour x = 0 seul le terme non nul est obtenu avec k = r+1.
f (p+r)(0) = sdnpp! * [Cr+1p+r /p (r+1)! Dk /(sd)np-(r+1)] = sdnpp ! (p+r)(p+r-1) …(p+1) Dk /(sd)np-(r+1) = sd(r+1) p ! (p+r)(p+r-1) …(p+1) Dk avec Dk et sd entier.
Ce résultat finalise (3-3).
Il reste à montrer que Σi=1nf(j)(ai) est entier, multiple de p! lorsque j ≥ p pour finaliser (3-5).
f(x) = sdnpxp-1 Z(x) et comme Z(x) est une somme de monômes de la forme Dk/(sd)np–kxk avec Dkentier, on en déduit que f(x) est une somme de monômes de la forme : sdk Dk xk+p-1
La dérivée j-ième de chacun de ces monômes donnera sdk(k+p-1)(k+p-2) …(k+p-j) Dkxk+p-1-j
Pour j = p on trouvera des monômes de la forme : sdk(k+p-1)(k+p-2) …(k) * Dkxk-1 et en remarquant que (k+p-1)(k+p-2) …(k) = (k+p-1)!/(k-1) ! et que Ck+p-1k-1 = (k+p-1)!/(k-1)!p! on obtient (k+p-1)(k+p-2) …(k) = p! * Ck+p-1k-1 ce qui permet d’écrire les monômes de f(x)(p) sous la forme : sdk p! * Ck+p-1k-1* Dkxk-1 = sdk p! * Ek0 * xk-1 avec Ek0 entier.
Pour j > p on trouvera des monômes de la forme : sdk(k+p-1)(k+p-2) …(k+p–j) Dkxk-1+p–jet en remarquant que (k+p-1)(k+p-2) …(k+p–j) = (k+p-1)!/(k+p–j-1)! et que Ck+p-1k+p–j-1 = (k+p-1)!/(k+p–j-1)!j! on obtient (k+p-1)(k+p-2) …(k+p–j) = j! * Ck+p-1k+p–j-1 ce qui permet d’écrire les monômes de f(x)(j) sous la forme : sdk j! * Ck+p-1k+p–j-1* Dkjxk+p-j-1. Comme j > p, le monôme peut être écrit sdk p! * Ekp–j * xk+p–j-1avec Ekj entier.
D’une façon générale, pour j ≥ p, f(x)(j) = somme de monômes de la forme sdk p! * Ekp-j * xk+p–j-1, que l’on peut reformuler en Σ sdk p! * Eku * xk–u-1 avec u= p–j indice allant de 0 à k-1.
Appliquons ce résultat à ai :
f(ai)(j) = Σu=0k-1 sdk p! * Eku * aik–u-1 et donc :
La somme Σ1naik–u-1 est symétrique sur les aik–u-1 et l’exposant k–u-1 vaut au plus k-1. Cette somme s’exprime par une combinaison de polynômes symétriques élémentaires en ai qui sera au plus de degré k-1 en termes qi, on en déduit Σ1naik–u-1 = entier/sdk.
Cela permet de conclure : Σ1n f(ai)(j) = p! * entier lorsque j ≥ p. Ce résultat finalise (3-5).
La fonction π qui à un réel x associe π (x) le nombre de nombres premiers inférieurs ou égaux à x, est équivalente lorsque x tend vers +∞, au quotient de x par son logarithme népérien:
Histoire du théorème
Le théorème des nombres premiers a été conjecturé dans la marge d’une table de logarithmes par Gauss en 1792 ou 1793 alors qu’il avait seulement 15 ou 16 ans (selon ses propres affirmations), puis par Adrien-Marie Legendre qui conjectura en 1808 que π (x) est approximé par la fonction :
x / ( A log x + B ) , où A et B sont des constantes.
Le Russe Pafnouti Tchebychev a établi en 1851 que si x est assez grand, π (x) est compris entre 0,92129 x/log(x) et 1,10556 x/log(x).
Le théorème a finalement été démontré indépendamment par Jacques Hadamard et Charles Jean de La Vallée Poussin en 1896 à l’aide de méthodes d’analyse complexe, utilisant en particulier la fonction ζ de Riemann. Au cours du 20e siècle, il a aussi fini par prendre le nom de théorème des nombres premiers (TNP).
Plusieurs démonstrations en ont été trouvées, dont les preuves ’’élémentaires’’ d’ Atle Selberg et Paul Erdős (1949). Ces preuves ont introduit diverses simplifications qui évitent l’analyse complexe, mais elles restent très lourdes. En 1980, le mathématicien américain Donald J. Newman apporte une nouvelle preuve qui est à ce jour sans doute la plus courte des preuves connues. Courte mais pas vraiment élémentaire dans le sens où elle utilise le théorème intégral de Cauchy issu d’une analyse complexe.
La version présentée dans cette article est celle d’ Atle Selberg et Paul Erdős présentée le 30 octobre 1948 à Amsterdam, mise en forme par J.G. Van der Corput sur la base des notes qu’il a prises lors de cette conférence. Elle est élémentaire, donc ne nécessite que des connaissances de base en mathématiques, la contrepartie est qu’elle est très longue et nécessite du temps pour la digérer.
Ref : Démonstration élémentaire du théorème sur la distribution des nombres premiers, Mathematisch centrum, ‘49’, Amsterdam.
Les grandes lignes de la démonstration
On note p, nombre premier
On note π (x) la fonction donnant le nombre de nombre premiers inférieurs à x.
On note V(x) la fonction définie par : V(x) =∑p<x log p, la somme des logarithmes des nombres premiers inférieurs à x.
La fonction V(x) est une fonction croissante, c’est-à-dire que si x2 > x1 alors V(x2) > V(x1).
On sera amené à utiliser les coefficients du binôme de Pascal, que l’on notera dans le fil du texte (k¦n), ou bien dans les formules sous leur expression habituelle :
1ère Etape : Dans un premier temps on montre que:
L’enjeu de la suite de la démonstration devient alors de montrer que :
2ième Etape : Mise en place d’un étau sur V(x)/x :
Pour cela on montre que que V(x)/x est encadré par 2 bornes, 2 constantes réelles positives a et A telles que :
3ième étape : L’étau se resserre :
En s’appuyant sur la formule de A. Selberg, on montre que : a + A = 2.
Le principal effort durant cette étape consiste à démontrer la formule de Selberg, ce qui est assez laborieux. La démonstration nécessite 12 lemmes préparatoires, dont 8 sont démontrés dans la partie boîte à outils. Une fois la formule de Selberg acquise, la démonstration de l’égalité a + A = 2 est rapide.
4ième étape : L’étau est complétement refermé
La preuve se termine par la démonstration que a = A, ce qui compte tenu de (a + A) = 2, implique que a = A = 1
Boîte à outils
1- Dans toute la suite de l’article, les lettres p et q désigneront toujours un entier premier.
2- Toute puissance réelle de x (c’est-à-dire xα avec α positif) est inférieure à la fonction exponentielle exp(x) à partir d’un certain rang ; c’est-à-dire : lim (xα/exp(x)) = 0 quand x tend vers l’infini. Cela se déduit immédiatement du fait que la fonction log(x) / x tend vers 0 lorsque x tend vers l’infini. En effet, on aura pour tout réel α positif : log(xα/exp(x)) = α log(x) – x = x (α log(x)/ x – 1) qui tend vers – x, c’est-à-dire –∞ lorsque x tend vers +∞, et si log(xα/exp(x)) tend vers –∞ cela signifie que exp( log(xα/exp(x)) ) = xα/exp(x) tend vers exp(–∞) c’est-à-dire 0.
3- On note o(f(x)) une fonction telle qui devient négligeable par rapport à f(x) lorsque x tend vers l’infini, c’est-à-dire telle que le rapport o(f(x)) / f(x) tende vers 0 quand x tend vers l’infini.
4- Fonction de Möbius : On note μ(m) la fonction de Möbius, définie sur N, par:
μ(1) =1,
μ(m) = 0 si m est divisible par un carré > 1, et dans les autres cas μ(m) = +1 ou -1 selon que le nombre de facteurs premiers de n est pair ou impair.
La fonction de Möbius est une fonction multiplicative, c’est-à-dire que l’on a μ(ab) = μ(a) μ(b), si a et b sont premiers entre eux.
5- La démonstration de la formule de Selberg s’appuie sur 12 lemmes. Les lemmes 1, 2, 7, 8, 9, 10, 11 et 12 forment une suite cohérente et nous avons fait le choix de les traiter dans ce paragraphe de boîte à outils de façon à ce que l’exposé de la démonstration de la formule de Selberg puis du théorème s’en trouve allégée. Voici les 8 lemmes en question et leur démonstration.
6- Lemme 1 : Notons Cn(m) la fonction définie par:
Où la somme est étendue à tous les diviseurs d de m, 1 et m compris.
Le lemme 1 affirme que si m contient plus de n facteurs premiers différents alors pour tout k entier positif < n la fonction Ck(m) vérifie, pour m > 1:
Démonstration du lemme 1 : la démonstration va être faite par récurrence, en commençant par le cas n= 0, puis en démontrant que lorsque la propriété est vraie pour n-1, elle l’est aussi pour n.
Cas n = 0 : il faut démontrer que ∑d/mμ(d) = 0 pour tout m > 1
Soit m entier qui se décompose en r facteurs premiers (r> 0),
m = p1α1p2α2 p3α3… pr-1αr-1 prαr
Tous les diviseurs de d dont la décomposition comprend un exposant > 2 donneront un μ(d) = 0, donc les seuls diviseurs d de m à considérer pour le calcul de ∑d/mμ(d) sont ceux de la forme :
d = p1β1p2β2 p3β3… pr-1βr-1 prβr, avec βi = 0 ou 1
Il y a un seul diviseur avec tous les βi = 0, d = 1 et μ(d) = 1
Il y en a (1¦r) avec un seul bi = 1 et les autres = 0. Pour chacun de ces diviseurs μ(d) = -1, leur contribution à la somme est -(1¦r)
Il y en a (2¦r) avec exactement 2 βi = 1 et les autres = 0. Pour chacun de ces diviseurs μ(d) = 1, leur contribution à la somme est (2¦r)
…
Il y en a (r-1¦r) avec exactement (r-1) βi = 1 et 1 βi = 0. Pour chacun de ces diviseurs μ(d) = (-1)r-1, leur contribution à la somme est (-1)r-1(r-1¦r)
Il y en a (r¦r) avec exactement tous les βi = 1. Pour ce diviseur μ(d) = (-1)r, sa contribution à la somme est (-1)r(r¦r)
On aura donc au total
Le cas n = 0 est donc démontré.
Supposons maintenant que le cas n-1 soit vrai, démontrons qu’alors∑d/mμ(d)(log d)n = 0 pour tout m comprenant au moins n facteurs premiers.
La propriété est vraie au rang n-1 signifie que pour tout m contenant au moins n-1 facteurs premiers∑d/mμ(d)(log d)k = 0 pour k de 0 à n-1.
Considérons m entier qui se décomposerait en au moins n facteurs premiers. m s’écrit : m = pαb, avec p premier, α > 1, b non divisible par p, et b comprenant au moins n-1 facteurs premiers.
Tout diviseur d de pαb s’écrit d1d2 avec d1 diviseur de pα et d2 diviseur de b.
Les Cn-k(b) = 0 de k = 1 à n, il ne reste donc plus dans la somme que le terme C0 (pα)Cn(b) et l’on sait que C0 (pα) = 0.
Le cas n est donc aussi démontré lorsque n-1 est vrai. Le lemme 1 est démontré.
7- Lemme 2 : Soit x > 0, posons Λx(d) = μ(d) (log x/d)2 et fx(m) = ∑d/mΛ(d), alors :
fx (1) = log2x (1)
fx (pα) = -log2p + 2 (log x) (log p) avec p premier et a > 1 (2)
fx (pαqβ ) = 2 (log p) (log q) avec p et q premiers et α et β > 1 (3)
fx (m) = 0 si m contient plus de 2 facteurs premiers différents. (4)
8- Lemme 7 : On a pour chaque entier n :
En effet : ∑d/mμ(d) = 1 pour m = 1, et = 0 pour m > 1 Donc :
Chaque diviseur d de cette double somme va donner le terme μ(d) pour chaque multiple < n de d. On obtient :
Par conséquent,
car la somme est constituée de n-1 termes inférieurs à 1 (et le dernier terme est nul).
9- Lemme 8 : Le lemme 8 comprend 2 assertions :
Assertion 1 : Il existe une constante C1 telle que la fonction ε(y) = ∑n≤y 1/n – log y + C1 tende vers 0 lorsque y -> +∞, de manière assez rapide pour que ε(y) (log y) tende aussi vers 0 (ce qui est une autre façon de dire que ε(y) tend plus vite vers 0 que log y ne tend vers l’infini, de sorte que le produit tend vers 0, c’est-à-dire finalement que ε(y) (log y) est un o(1) et que ε(y) est un o(1/log y)).
Assertion 2 : ∑n≤y (log n)/n – 1/2 (log y)2 tend vers une limite finie.
Démonstration de la première assertion :
Soit n la partie entière de y :
Pour chaque k > 2, il existe h tel que 2h< k – 1 < 2h+1, c’est-à-dire 1/2h+1 < 1/(k – 1) < 1/2h. Chaque tranche de 2h à 2h+1contient 2h nombres, de sorte que :
On en déduit :
∑1n-1δk converge donc vers une constante C1 < Log 2 + 1 lorsque n tend vers l’infini, et nous pouvons écrire :
En posant εn(y) = ∑n∞δk cela permet d’écrire :
hn + 1 est > partie entière de log(n – 1)/log 2. D’où :
Par définition, ε(y) = ∑n<y 1/n – log y + C1,
Donc lim ε(y) = 0 quand y -> +∞ , et de plus on a bien lim ε(y) log y = 0 quand y -> +∞ en vertu de lim log y / y = 0 quand y -> +∞. La première assertion du lemme est démontrée.
Démonstration de la seconde assertion : ∑n ≤ y (log n)/n – 1/2 (log y)2 tend vers une limite finie.
Or comme on l’a vu lors de la démonstration de la première assertion, log(k+1) = log k +1/k + δk , d’où :
avec C2 correspondant au cas k = 1 de la seconde somme. La somme de gauche revient à (log n)2 et en divisant le tout par 2 il vient :
Comme δk ~ 1/k2 la somme ∑2n-1 log kδk + δk/k + 1/2k2 +1/2 (δk)2 converge vers une constante C3 lorsque n tend vers l’infini, et en posant C4 = C2/2 + C3, nous pouvons écrire :
Ce qui permet de conclure que :
10- Lemme 9 : En désignant par τ(n) le nombre de diviseurs de n. On a :
Où C6 et C7 sont des constantes, et o(1) une fonction qui tend vers 0 lorsque y tend vers l’infini.
Démonstration :τ(k) est le nombre de paires d’entier a, b, telles que le produit ab = k, donc :
Cette somme comprend 3 termes : S1, S2, S3. Les 2 premiers S1 et S2 donneront des valeurs identiques, et la dernière somme S3 revient à :
Calculons d’abord la somme S4. D’après la première assertion du lemme 8, ∑n<y 1/n = log y – C1 + ε(y) donc :
Les 3 termes contenant ε(√y) sont tous les trois des o(1), y compris celui multiplié par (log y) d’après la deuxième assertion du lemme 8, donc :
Calculons maintenant S1 (qui est aussi S2) :
D’après la deuxième assertion du lemme 8, ∑n≤y (log n)/n – 1/2 (log y)2 tend vers une limite finie, donc :
La somme S1 revient donc à :
On en déduit, en regroupant les expressions de S1, S2 et S3 :
11- Lemme 10 : On a :
Autrement dit : ∑k≤xμ(k)/k log(x/k) est un o(log x).
Démonstration : d’après le lemme 8, ∑n<y 1/n = log y – C1 + ε(y)
On pose m = j*k. Chaque k est un diviseur de m. En regroupant la double somme par valeur de 1/(jk) identique , on peut écrire :
D’après le lemme 1, ∑k/mμ(k) = 0 , sauf pour m = 1, auquel cas la somme vaut 1. Donc le terme ∑m≤x1/m ∑k/mμ(k) = 1.
D’après le lemme 7, la valeur absolue de ∑k≤xμ(k)/k est ≤ 1
Il ne reste plus qu’à démontrer que ∑k≤xμ(k)/k ε(x/k) est un o(log x). Pour cela nous pouvons déjà écrire :
Soit y défini par y = x1-ρ = x/xρ avec ρ = 1/√(log x). On a y < x et pour tous les k < y on a : x/k > x/y = xρ = exp(ρ logx) = exp( √(log x)). Par conséquent x/y tend vers l’infini lorsque x tend vers l’infini, et pour k < y on aura x/k qui tendra vers l’infini lorsque x tendra vers l’infini. On obtient donc ε(x/k) tend vers 0 quand x tend vers l’infini, ce qui signifie finalement que chaque ε(x/k) = o(1). Cela permet de conclure que la somme, étendue jusqu’à y est un o(log x) :
Par ailleurs la contribution des k compris entre y et x est aussi un o(log(x) :
En conclusion, ∑k<xμ(k)/kε(x/k) est bien un o(log x). Le lemme est démontré.
12- Lemme 11 : Pour chaque entier n, on a :
Démonstration : τ(m) étant le nombre de diviseurs de m, et d1 les diviseurs de m, On se rappelle que τ(m) = ∑d1/m1 . D’où :
Pour d1 < n, la somme des μ(d) pour d diviseur de n/d1 = 0 lorsque n/d1 > 1, d’après le lemme 1. La seule contribution non nulle est celle pour d1 = n, et dans ce cas elle vaut 1, d’où le lemme.
13- Lemme 12 :
Démonstration : D’après le lemme 9,
Ce qui permet d’écrire :
D’après le lemme 10, ∑k<xμ(k)/k log(x/k) est un o(log x), et d’après le lemme 7, ∑k≤xμ(k)/k est compris entre -1 et +1. On en déduit :
Posons n = j*k.
D’après le lemme 11 :
d’où, en conjonction avec le lemme 8 :
D’où finalement le lemme :
Démonstration du Théorème des nombres premiers
ETAPE 1
Il s’agit de montrer que :
Partons de l’inégalité suivante :
D’où : V(x)/log x ≤ π(x) et donc V(x)/x ≤ π(x) (log x)/x (I)
Par ailleurs, pour ε positif < 1 nous pouvons écrire :
Pour tous y > 5 , π(y) < y, c’est-à-dire –y < –π(y). A partir de cette inégalité et en utilisant (II), on obtient le résultat (III) suivant :
On pose ε = 1 – (log x)-1/2 , et l’on a :
De (I), (III), et (IV) on tire :
En passant à la limite lorsque x tend vers l’infini, ε tend vers 1 et (u2 / eu) tend vers 0 avec u = (log x)1/2 qui tend vers l’infini (voir boîte à outils), donc :
Le reste de la démonstration a pour objet de prouver que V(x) ~ x .
ETAPE 2
Montrons que V(x)/x est borné, ce sera le lemme 3 :
Lemme 3 : il existe a et A réel positifs, avec 0 < a ≤ A tels que à partir d’un certain rang :
Dans un premier temps nous allons nous intéresser à la mise en évidence de la borne supérieure A.
Pour n entier > 0 on a : en se rappelant que la lettre p concerne les nombres premiers,
Car les nombres premiers p tels que n < p ≤ 2n au numérateur de (2n¦n)= (n+n)(n+n-1)…(n+2)(n+1)/1.2.3…n ne peuvent être effacés par le dénominateur.
Donc, en prenant le logarithme des termes de l’inégalité (la fonction logarithme qui est croissante conserve le sens de l’inégalité), on obtiendra n log4 > V(2n) – V(n).
Appliquons maintenant cette formule sur les puissances successives de 2, on obtient :
V(2k+1) – V(2k) ≤ 2k log4
V(2k) – V(2k-1) ≤ 2k-1 log4
….
V(2i) – V(2i-1) ≤ 2i-1 log4
V(2i-1) – V(2i-2) ≤ i-2 log4
…
V(22) – V(21) ≤ 21 log4
V(21) – V(20) ≤ 20 log4
Et en faisant la somme de toutes ces inégalité, cela donne : V(2k+1) – V(1)<2k+1 log4, sachant que V(1) = 0 et que somme des 2i pour i = 0 à i = k est 2k+1.
Comme pour tout x rée > 1 il existe kx tel que 2kx ≤ x < 2kx+1 , il vient par croissance de V(x):
Montrons maintenant qu’il existe aussi une constante a > 0 telle que V(x) ≥ a*x .
Pour tout nombre premier p de la série des nombres entiers 1, 2, 3, …, n, cette série contient exactement [n/p] multiples du nombre premier p, [n/p2] multiples de p2, [n/p3] multiples de p3, etc…, de sorte que si l’on considère le produit de tous les termes de 1 à n, c’est à dire n!, ce produit s’exprime sous la forme:
n! = p[n/p]p[n/p^2]p[n/p^3] … p[n/p^k]*J avec J nombre entier ne comprenant plus le nombre premier p.
Clarification de ce résultat : la contribution de chaque nombre multiple de p2 dans ce produit sera bien de p puissance 1 déjà compté à travers [n/p] puis p puissance 1 compté à travers [n/p2] ce qui donnera bien p2 au total lorsque l’on forme le produit. De même la contribution de chaque nombre multiple de p3 dans ce produit sera bien de p1 à travers [n/p] puis p1 à travers [n/p2] puis p1 à travers [n/p3] soit p3 au total, etc…
Le raisonnement précédent étant valable pour tous les nombres premiers de 1 à n, on peut donc finalement écrire :
Où knp est la plus grande puissance de p telle que [n/pknp] ≥ 1, (les puissances supérieures donneront 0).
Où knp est la plus grande puissance de p telle que [n/pknp] ≥ 1, (les puissances supérieures donneront 0).
Repartons de (2n¦n) qui est la notation pour (2n)!/(n!*n!) et notons k2np la plus grande puissance de p telle que [2n/pk2np],
Sachant que pour chaque p donné : k2np > knp, cela implique que [2n/pk2np] = 0. On peut donc aussi élargir l’écriture de n! sous la formeOn peut encore l’élargir en incluant dans le produit les nombre premiers > n jusqu’à 2n car pour ces nombres [n/p] = 0, [n/pi] = 0, et p[n/i] = 1.
On en déduit l’expression Qp de l’exposant de chaque nombre premier p compris entre 1 et n, dans (2n)!/(n!*n!).
La fonction [2y] – 2[y] est périodique de période 1, elle s’annule pour y de 0 à < 0.5 puis prend la valeur 1 de 0.5 à < 1, donc Qp est une somme de k2np termes positifs inférieurs à 1 ⟹ Qp ≤ k2np .
C’est-à-dire, sachant que [2n/pk2np] ≥ 1 implique log 2n > k2np log p, c’est à dire k2np < log 2n/log p ou encore k2np ≤ [log 2n/log p] : Qp ≤ k2np ≤ [log 2n/log p].
En prenant le log de (2n)!/(n!*n!) nous pouvons finalement écrire l’inégalité :En remarquant que pour p > √(2n) on a [log 2n/log p] = 1 et que sinon [log 2n/log p] ≤ log 2n/log p, il vient :Ainsi on trouve :Et comme √(2n) log n et √(2n) log 2 croissent moins vite que n, on aura à partir de n suffisamment grand :Ce qui donne:Donc, en considérant x suffisamment grand, c’est-à-dire tel que [x/2] soit un entier pour lequel la relation précédente s’applique, on a : n < x/2 < n + 1, soit 2n ≤ x < 2n + 2 , ce qui permet d’écrire :
Conclusion : il existe bien a et A réel positifs, avec 0 < a ≤ A tels qu’à partir d’un certain rang :
On a d’ailleurs démontré que : a > (log 2)/4 et A ≤ 4 log 2 .
ETAPE 3
Nous voilà arrivés à l’étape 3 dont l’objet est de démontrer que a + A = 2. Pour cela nous avons besoin de disposer de la formule de Selberg, et pour disposer de cette formule nous devons auparavant démontrer les 3 lemmes qui suivent . Il s’agit des lemmes 4, 5 et 6.
Lemme 4 : Pour p premier,
Démonstration : soit ε un réel positif. On a log (x/p) < log (1/ε) pour p > εxOr pour x suffisamment grand V(εx)/x < Aε et V(x)/x < A , d’où :Prenons ε(x) = 1/log x on aura :Avec X = log x.
lim (log X )/ X = 0 quand x tend vers +∞, car alors X = log x tend vers +∞. Comme également lim (1/log x ) = 0 quand x tend vers +∞, le lemme 4 est démontré.
Lemme 5 : Pour α entier et p premier,
En effet :Avec k le plus grand entier tel que 2k< x. C’est-à-dire k < (log x)/log 2. D’où :Donc lorsque x tend vers +∞ :Le lemme 5 est démontré.
Lemme 6 : La fonction f(m) introduite au lemme 2 (cf boîte à outils) vérifie :
D’après le lemme 2 nous avons :La somme comporte 3 termes que nous allons évaluer l’un après l’autre.
Evaluation du premier terme : (log x)2 est un o(x log x ) : en effet (log x)2/(x log x) = log x /x qui tend vers 0 quand x tend vers +∞.
Evaluation du deuxième terme : considérons la somme des – (log p)2 + 2 log p log x qui est établi sur les pα ≤ x, et étudions de façon séparée les cas α ≥ 2 et α < 2.
Cas α ≥ 2 :
La somme s’arrête avec k = [(log x) / log 2].
Maintenant en remplaçant p par la valeur maximale x1/i dans chacune des sous sommes cela donne l’inégalité suivante :
Puisque k = (log x) / log 2,
Donc lorsque α ≥ 2 la somme sur les 2 log p log x est bornée par : (log x)3x1/2 / log 2 qui est un o(x log x). De même la somme sur les (log p)2 sera inférieure à la somme sur les log p log x que l’on vient de calculer, ce sera donc un o(x log x). Conclusion: la somme des – (log p)2 + 2 log p log x établie sur les pα ≤ x avec α ≥ 2 est un o (x log x).
Cas α < 2 : Pour α < 2 , c’est-à-dire α = 1, la somme s’écrit :
Et l’on se rappelle que le lemme 4 a démontré que ∑p≤x log p log(x/p) est un o(x log x).
Les cas α ≥ 2 et α < 2 permettent de conclure que :
Evaluation du troisième terme: le terme en question s’écrit ∑pαqβ≤x 2(log p)(log q). Nous allons successivement regarder la contribution des cas β ≥ 2 et α ≥ 1, α ≥ 2 et β ≥ 1, puis du cas β = α = 1
Cas β ≥ 2 et α ≥ 1
Appliquons le lemme 5, avec x/qβau lieu de x :
Cela permet d’écrire :
Car log (x/qβ) ≤ log x . Par ailleurs :
Pour ε = 1/2, à partir de x suffisamment grand, noté X, on a log q /(qε) < 1, ce qui permet d’écrire :Où C1 = ∑q≤X log q /q2 et C2 = ∑q>X (1/q3/2))= ξ(3/2) sont des constantes.
Cela permet de conclure que pour ce qui est de la contribution des termes β ≥ 2 et α ≥ 1 :
Cas α ≥ 2 et β ≥ 1 : p et q, et α et β ayant des rôles symétriques, la contribution des termes α ≥ 2 et β ≥ 1 sera elle aussi un o(xlog x).
Cas α = 1 et β = 1 :
Or, nous avons vu au début du calcul du deuxième terme que pour α ≥ 2 la somme sur les (log p)2 est un o(x log x). Il reste à considérer :Nous savons que :On en déduit finalement que pour le cas α = 1 et β = 1 :Finalement, en sommant les résultats obtenus pour les 3 termes, nous obtenons bien :Le lemme 6 est démontré.
Grâce aux lemmes 3, 4, 5, 6, et des lemmes de la boîte à outils, nous voilà armés pour démontrer la formule de Selberg, à savoir :
Partons du lemme 6 :Il reste à montrer que :Calculons pour cela la somme des f(m),Or le nombre de multiples de d inférieurs à x est : partie entière de x/d, c’est-à-dire x/d à moins de 1 près. Donc :Avec η(x, d) < 1,Calcul du premier terme , qui a x en facteur :
En remplaçant Λ(d) par sa définition, puis en utilisant le lemme 12 de la boîte à outils, cela donne :
Calcul du second terme :
La valeur des x/d varie de 1 à x. Découpons l’intervalle 1 … x par tranches de puissances de 2. Pour tous les d tels que x/d est dans la tranche 2k+1 > x/d ≥ 2k on a :
et comme d ≤ x/2k , il y a au plus x/2k contributeurs dans cette tranche. Donc la contribution des valeurs de la tranche 2k – 2k+1 est au plus x (k + 1)2/2k, et la contribution totale de toutes les tranches sera :
Or à partir d’un certain rang on a (k+1)2 < 2k/2 en vertu de log(k+1) / k < log(2) / 4 à partir d’un certain rang puisque log(k+1) / k tend vers 0 quand k tend vers l’infini. On aura donc :
Et donc :Ce qui permet d’écrire :C’est ce qu’il restait à démontrer pour obtenir la fameuse formule :
La formule de Selberg est démontrée, nous pouvons passer à la suite de la démonstration et terminer l’étape 3 en montrant que : a + A = 2.
Et pour cela commençons par démontrer le lemme 13 :
Lemme 13 :
Nous avons vu au lemme 3 que :Ce qui donne, en passant au logarithme : OrLe premier terme est de la forme n*(terme borné), examinons le second,
Le second terme est lui aussi de la forme n*(terme borné).
ll vient :
Avec K terme borné.
Comme de plus :
Avec :On en déduit :
Il reste à calculer la somme des log k, et pour cela exploitons la relation suivante, vraie pour k entier ≥ 2
La somme de 2 à n des log k donnera n log n pour la sommation des 2 premiers termes de la relation, plus la sommation de 2 à n du terme (k-1) log ( 1 + 1/(k-1) ) que nous devons maintenant calculer.
On en déduit :Et donc :Ce qui permet finalement d’écrire :Et donc :Le lemme 13 est démontré.
Dans un premier temps nous allons pouvoir montrer que 2 ≥ A + a.
Pour tout δ positif, on sait, par l’étape 2 que pour x suffisamment grand et pour chaque p ≤ √x on a V(x/p) > (a – δ)*x/p, et donc :
Où nous voyons apparaitre une somme de log p / p, étendue sur les nombres premiers inférieurs à √x. D’après le lemme 13 que nous venons de voir, cette somme est de l’ordre de log (√x) à o(log(x) près, c’est à dire de l’ordre de (log x) / 2, ce qui revient à :
On en déduit :
Appliquons ce résultat à la formule de Selberg :
Il est toujours possible de choisir une sous suite de xi qui tend vers l’infini et telle que V(xi)/xi tende vers A. Avec cette suite de xi on obtient par passage à la limite lorsque les xi tendent vers l’infini :
2 ≥ A + a – δ
Et comme cela est vrai pour tout δ,
2 ≥ A + a
Recommençons le même raisonnement, mais cette fois avec l’information de l’étape 2 qui nous dit que pour x suffisamment grand et pour p ≤ √x on a V(x/p) < (A + δ)*x/p, et donc :
L’application de la formule de Selberg donne :
Il est toujours possible de choisir une sous suite de xj qui tend vers l’infini et telle que V(xj)/xj tende vers a. Avec cette série on obtient par passage à la limite lorsque les xi tendent vers l’infini :
2 ≤ A + a + δ
Et comme cela est vrai pour tout δ,
2 ≤ A + a
Conclusion : nous venons de voir successivement que 2 ≥ A + a et que 2 ≤ A + a. L’égalité 2 = A + a est démontrée. Nous pouvons passer à l’étape 4.
ETAPE 4
Montrons enfin que a = A.
La démonstration repose sur une preuve par l’absurde. Nous allons supposer que a < A, et voir que cela aura pour conséquence a ≥ A ce qui est contraire à l’hypothèse. On en déduira que a ≥ A, et comme par ailleurs nous savons que a ≤ A puisque a est la borne Min et A la borne Max de l’encadrement de V(x)/x, cela permettra de conclure immédiatement que a = A.
Supposons donc que a < A, et considérons σ réel positif, σ > 1 , tel que : σ a < A. On a A – σ a > 0, et donc il existe δ réel positif, suffisamment petit pour que A – σ a ≥ δ(σ + 2) = δσ + 2δ, c’est à dire de façon équivalente : A – δ a ≥ σ a + δσ + δ (4.1)
Soit N entier quelconque fixé, et l’ensemble E3(N) = ensemble des couples p, q, tels que p ≤ √x; q ≤ √(x/p), pq ≥ N, et qui vérifient en plus V(x/pq) ≥ (A – δ) x/pq .
Soit E4(p, q) = pour p et q de E3(N) donnés, l’ensemble des r tels que (pq) /σ < r ≤ σ pq . Cet ensemble n’est pas vide pour p et q suffisamment grands, puisque σ >1.
Étudions maintenant la somme S(x) définie par :
Nous allons montrer que S(x) est un o(log2x), c’est-à-dire que S(x)/log2 x tend vers 0 quand x tend vers l’infini.
Tout d’abord, pour chaque r de la somme sur E4(pq) nous avons : r ≤ σ pq = σ √p (√p q) = σ √p √(pq2) et comme p ≤ √x et q ≤ √(x/p) on aura r ≤ σ x1/4 √x = σx3/4 ≤ x à partir d’un certain rang.
De plus, pour x suffisamment grand, chaque r de E4(p, q) vérifie V(x/r) ≥ (a + δ ) x/r . Pour le démontrer nous allons successivement considérer les cas ou r ≤ pq et r > pq.
Cas où r ≤ pq :
V(x/r) ≥ V(x/pq) par croissance de V, et V(x/pq) ≥ (A – δ) x/(pq) , car p et q appartiennent à E3(N).
Donc V(x/r) ≥ (A – δ) x/(pq) ≥ (A – δ) x/(σr) et en se rappelant que la relation (4.1) donne (A – δ) > σa + δσ+ δ ≥ σ(a + δ) on obtient bien V(x/r) ≥ (a + δ) x/r.
Cas où r > pq :
On pose u = x/r et v = x/(pq). On a u < v (puisqu’on est dans le cas r > pq ) et v < σ u par définition de E4(p, q). Appliquons la formule de Selberg à respectivement u et v et soustrayons les 2 relations :
D’où :
v et u sont du même ordre, à un facteur plus petit que σ ou 1/σ près donc o(v log v / log u) et 2 v log (v/u) / (log u) sont aussi des o(u) car leur rapport avec u tend vers 0 quand u tend vers l’infini. On a donc finalement, sachant que (log v / log u) ≥ 1 et que V(v) ≥ (A – δ)v car v a été défini par v = x/(pq) avec pq dans E3(N) :
Et sachant que A – 2 = a, cela donne : V(u) ≥ 2u – (a + δ)v + o(u), puis en exploitant la relation v < σu : V(u) ≥ 2u – (a + δ)σu + o(u), soit : V(u) ≥ ( 2 – (a + δ)σ)u + o(u).
En utilisant maintenant la relation 4.1 qui établit que –σ a – δ a ≥ –A + δσ + δ nous avons –σ a – δ a ≥ –A + 2δ , puisque σ > 1. On en déduit : 2 – (a + δ)σ ≥ 2 – A + 2δ, d’où :
V(u) ≥ (2 – A + 2δ)u + o(u) = (a + 2δ)u + o(u) = (a + δ)u + δu + o(u).
Pour x suffisamment grand u = x/r deviendra suffisamment grand pour garantir (δu + o(u) )> 0 et on aura donc bien V(u) ≥ (a + δ)u, c’est-à-dire finalement :
V(x/r) ≥ (a + δ) x/r
Donc à partir d’un certain rang, que r soit < pq ou r ≥ pq, nous aurons pour chaque r de E4(p, q) : V(x/r) ≥ (a + δ) x/r. De plus nous avons aussi vu auparavant que pour chaque r de E4(p, q) r ≤ x à partir d’un certain rang.
Revenons maintenant à l’évaluation de la somme S(x) dont on cherche a prouver que c’est un o (log2x). Lorsque l’on développe la somme S(x), chaque terme (log r)/r de la somme sur E4(p, q) se retrouve en produit de tous les (log p)/p (log q)/q qui vérifient : p ≤ √x, q ≤ √(x/p) , pq ≥ N, r/σ < pq < σr.
En mettant chaque (log r)/r en facteur de tous les (log p)/p (log q)/q concernés, on obtiendra donc un terme de la forme :
avec E5(r) = l’ensemble des (p, q) tels que p ≤ √x, q ≤ √(x/p) , pq ≥ N, r/σ < pq < σr.
En élargissant la somme sans la limitation sur N on aura :
avec E6(r) l’ensemble des (p, q) tels que p ≤ √x, q ≤ √(x/p) , r/σ < pq < σr.
En élargissant encore la sommation de S(x) qui portait initialement sur les r de E4(p, q) à la sommation sur les r qui vérifient r ≤ x et V(x/r) ≥ (a + δ) x/r on écrit finalement, avec E7(x) = ensemble des r tels que V(x/r) > (a + δ) x/r :
Evaluons la sommation sur E6(r) :Puisqu’à partir d’un certain rang V(x) / x < A et en vertu du lemme 13, Σp<√x (log p)/p < 1/2 log x à partir d’un certain rang.
Par conséquent, en utilisant le lemme 14 en annexe qui démontre que la somme des (log r)/r sur r appartenant à E7(x) est un o(log x) on obtient le résultat 4.3 que l’on cherchait :
Introduisons maintenant la somme T(x), établie sur l’ensemble E8(p, q) des couples p, q qui vérifient p ≤ √x, q ≤ √(x/p) et pq ≥ N, . On note que E8(p, q) = E3(p, q) + les couples (p, q) qui vérifient p ≤ √x, q ≤ √(x/p) , pq ≥ N, et V(x/pq) < (A – δ)x/pq.
Restreignons la somme à l’ensemble des pq tel que : √N ≤ p ≤ √x, √N ≤ q ≤ x1/4, et pq ≥ N. Il s’agit bien d’une restriction, évidente pour les p, et pour q on a bien q ≤ x1/4 ≤ √x/√p car p < √x, et l’on a aussi pq ≥ N, donc :
D’après le lemme 13, chacun de ces 2 facteurs est au plus de l’ordre de log x, donc pour x suffisamment grand : T(x) > c2 (log x)2avec c2 constante indépendante de x.
Comme E8(p, q) = E3(p, q) + les (p,q) qui vérifient p ≤ √x, q ≤ √(x/p), pq ≥ N, et V(x/pq) < (A – δ) x/pq , en notant E9(p, q) l’ensemble des (p, q) tels que p ≤ √x, q ≤ √(x/p), pq ≥ N, et V(x/pq) < (A – δ) x/pq , on peut aussi écrire :
Or d’après le lemme 15 démontré en annexe on a:Et sachant comme on l’a vu que T(x) > c2 (log x)2 a partit d’un certain rang, on obtient donc :Car pour x suffisamment grand on aura forcément 1/2 c2log2x – o(log2x) > 0.
Revenons maintenant à S(x) en se rappelant que :
Et considérons la valeur Min des différentes sommations des log r / r sur E4(p, q). En la notant μ(x) car elle dépend de x, nous pouvons écrire :Mais la relation (4.3) nous disait aussi : S(x) ≤ o(log2x) donc :
Ce qui implique que forcément la limite de μ(x) = 0 lorsque x tend vers + ∞, avec μ(x) = Min (ΣE4 log r / r. Par définition, cette valeur Min est obtenue par au moins 1 couple (p, q) de E3 tel que (pq) /σ < r < σ pq et tel que :
On note tmin la valeur du produit pq de ce couple de E3 qui donne μ(x). On se rappelle que par définition tous les couples (p, q) de E3 vérifient pq ≥ N. Il existe donc tmin ≥ N tel que :
Et comme μ(x) tend vers 0 lorsque x tend vers l’infini, cela signifie que pour tout réel ε positif aussi petit que l’on veut et pour tout N entier il existe un réel tmin tel que :Ce qui implique :Soit :Ce qui permet de conclure que pour tout réel ε positif aussi petit que l’on veut et pour tout N entier, il existe un réel tmin tel que V(σtmin) – V(tmin/σ) < ε σtmin, c’est à dire ε σtmin > V(σtmin) – V(tmin/σ).
En prenant N suffisamment grand, tmin (qui est supérieur à N) sera suffisamment grand pour que V(σtmin) > (a – ε) σ tmin et V(tmin/σ) < (A + ε) tmin /σcompte tenu de l’encadrement obtenu à l’étape 2. D’où, en repartant du résultat du paragraphe précédent, pour tout ε > 0, ε σtmin > (a – ε) σtmin – (A + ε) tmin /σ, ce qui implique par passage à la limite : 0 ≥ aσtmin– Atmin /σ et donc : σ2a ≤ A, c’est-à-dire σ2 ≤ A/a.
Or rappelons-nous de la définition de σ au début de l’étape 4 : σ réel positif quelconque > 1 et tel que σ a < A c’est-à-dire σ< A/a.
Prenons σ(x) = A/a – e(x) avec e(x) << 1 et que nous allons faire tendre vers 0.
σ2(x) = (A/a)2 -2 e(x) A/a + e2(x) < A/a
(A/a)2 -2 e(x) A/a + e2(x) < A/a
(A/a)2 –A/a < 2 e(x) A/a – e2(x), et en passant à la limite en faisant tendre e(x) vers 0 :
(A/a)2 –A/a ≤ 0
A/a ≤ 1
C’est à dire a ≥ A
Rappelons du début de l’étape 4, nous avons supposé que a < A, et cela donne en conséquence a ≥ A ce qui est contraire à l’hypothèse. On en déduit donc que a ≥ A, et comme par ailleurs nous savons que a ≤ A puisque a est la borne Min et A la borne Max de l’encadrement de V(x)/x cela permettra de conclure immédiatement que a = A.
CQFD
Annexes
Lemme 14 :
Pour λ > a, on considère l’ensemble Eλ(x) défini par Eλ(x) = ensemble des p ≤ x tels que V(x/p) ≥ λx/p. Le lemme 14 démontre que :
En effet, examinons les différentes égalités suivantes :
L’ensemble {pq ≤ x} = l’ensemble {pq ≤ x avec p ≤ √x et √x < q ≤ x} U {pq ≤ x avec q ≤ √x et √x < p ≤ x} U {pq ≤ x avec p ≤ √x et q ≤ √x}, donc (1) s’écrit :
L’ensemble {pq ≤ x avec p ≤ √x} = {pq ≤ x avec p ≤ √x et q ≤ √x} U {pq ≤ x avec p ≤ √x et √x < q ≤ x}, donc (2) s’écrit :
Ce qui donne :De même (3) s’écrit :Ce qui donne :En remplaçant tous ces termes dans l’équation (4) cela donne :Et donc :OrD’où :Utilisons maintenant la formule de Selberg,Avec ce qui précède on peut l’écrire :Concentrons-nous sur la somme des V(x/p) log(p) pour p ≤ x.
Pour x/p suffisamment grand, disons x/p > u (avec u dépendant de δ), on a V(x/p) > (a – δ) x/p. En revanche pour x/p ≤ u on aura V(x/p) < (a – δ) x/p, mais il existe b ≥ 0 tel que pour x/p ≤ u on ait V(x/p) > (a – δ) x/p – b. Donc :
Et comme par défnition l’ensemble Eλ est inclus dans l’ensemble des p ≤ x,On en déduit :Et en reportant dans (6) :Reportons ce résultat dans (5) :V(x)/x logx , V(√x)2/x log x, sont des o(1), et de même on a d’après le lemme 13 :Cela permet d’écrire :Or on sait que l’on peut faire croitre x indéfiniment de façon que V(x)/x tende vers A, d’où :λ – a est fixe, et δ étant aussi petit que l’on veut, par exemple en peut toujours le choisir < 1/x, il en ressort que :
Lemme 15 :
Pour μ < a on considère l’ensemble Eμ(x) défini par Eμ(x) = ensemble des couples p, q, tels que p ≤ √x, q ≤ √(x/p) et qui vérifient en plus V(x/pq) ≤ μ x/pq
Le lemme 15 démontre que :
Démonstration :
Appliquons une première fois la formule de Selberg en remplaçant x par x/p :
Et maintenant injectons cette expression de V(x/p) dans la formule originale de Selberg :AvecEn vertu du lemme 13 on a :Donc :On en déduit :Creusons maintenant le calcul de Ω.Car pour x suffisamment grand, V(x/pq) ≤ (A + δ)x/pqOn note W le terme défini par :En appliquant le lemme 13 à √(x/p) on peut écrire :Soit :DoncEt donc :Revenons maintenant au calcul de V(x), à l’aide des expressions trouvées pour Ω et W.Et comme 1 / log(x/p) > 1 / log(x), on obtient :Comme enfin (A – μ) est positif et que l’inégalité est vraie quel que soit δ, cela permet de conclure :
Le premier théorème d’incomplétude de Kurt Gödel démontre que tout système logique suffisamment puissant pour démontrer les théorèmes de base de l’arithmétique admet nécessairement des énoncés qu’il ne peut ni démontrer ni réfuter. Pourtant ces énoncés ont un sens en termes d’arithmétique élémentaire et l’on pourrait s’attendre à ce qu’un système logique permette de déduire à partir de ses axiomes une réponse Vrai ou Faux à tous ces énoncés. En fait pour certains d’entre eux ce n’est pas le cas, de tels énoncés sont dits indécidables dans le système logique considéré. Cette situation est intrinsèque à tout système suffisamment puissant, un système logique augmenté de nouveaux axiomes pourrait apporter une preuve à ces énoncés, mais de nouveau, dans ce système logique augmenté il y aura forcément encore des énoncés indécidables.
En résumé, ce théorème montre qu’un système logique doté d’une certaine complexité, comme c’est le cas de l’arithmétique usuelle, est alors suffisamment puissant pour démontrer qu’il y a des énoncés vrais ou faux qu’il ne peut pas démontrer ni réfuter.
A l’inverse, le second théorème d’incomplétude de Gödel démontre qu’un système logique n’est jamais assez puissant pour démontrer sa propre cohérence.
De façon plus rigoureuse le théorème s’énonce comme suit :
SoitΛun système formel cohérent qui représente l’arithmétique. Alors Λest incomplet.
Les termes de système formel, de cohérence, et d’incomplétude qui apparaissent dans le théorème ont un sens précis qui est présenté dans le paragraphe Boîte à outils.
Histoire du théorème
Le premier théorème d’incomplétude a été présenté par Kurt Gödel alors qu’il avait 25 ans dans un article publié en 1931 dans les annales du Monatschefte für Mathematik. Il eut un très fort retentissement car il mettait un terme au projet conduit depuis le milieu du XIXe siècle par les logiciens pour établir un fondement sur la base duquel toutes les vérités mathématiques pourraient être construites.
Le second théorème, publié avec le premier, affirme que si un système logique est cohérent, alors sa propre cohérence ne peut pas en être déduite, autrement dit : une théorie cohérente ne peut pas démontrer sa propre cohérence.
Boîte à outils
Avant d’entrer dans le vif de la démonstration, nous devons clarifier plusieurs notions qui jouent un rôle fondamental dans la démonstration : il s’agit des notions de calcul, de fonctions calculables, d’ensembles énumérables, quelques notions sur les systèmes logiques, et sur ce que l’on appelle la cohérence et la complétude d’un système logique.
1) Notion de calcul :
Sans beaucoup nuire au fond de la démonstration, on peut résumer la notion de calcul à ce qui peut être programmé dans un ordinateur avec un langage informatique qui permet de travailler avec les structures de données suivantes : l’ensemble N des entiers naturels, le type booléen Bool = {Vrai, Faux} et les chaînes de caractères (sur un alphabet fini donné).
Le calcul, à proprement parler, est exécuté par un ordinateur, qui suit simplement les instructions pour lesquelles il a été programmé, sans pouvoir prendre de décisions arbitraires. Il s’agit donc d’un procédé déterministe.
Pour se rapprocher de la notion théorique de ce qu’est un calcul, il faut faire abstraction des contraintes physiques et imaginer que les programmes sont exécutés par un ordinateur idéal, qui n’aurait aucune limitation en quantité de mémoire ou de temps pour mener son calcul à terme.
Il y a, bien sûr, la possibilité qu’un calcul donné ne se termine jamais, par exemple, si le programme conduit à une boucle infinie, mais ce genre de non terminaison reste une conséquence déterministe du programme codé par le programmeur. Un programme P est dit total si son exécution (sur un ordinateur idéal) se termine en un temps fini, peu importe la valeur d’entrée qu’on donne au programme.
2) Fonctions calculables :
Intuitivement, une fonction est calculable s’il existe une procédure effective, un algorithme, pouvant la calculer. Les fonctions calculables furent d’abord modélisées par le calcul, mais d’autres formalismes comme les fonctions récursives ou les machines de Turing ont été proposés par la suite. Il a ensuite été prouvé que toutes ces définitions, bien que fondées sur des idées assez différentes, décrivent exactement le même ensemble de fonctions.
Définition 1 :Une fonction f : d’un ensemble A sur un ensemble B (A -> B) est dite calculable si on peut écrire un programme qui lorsqu’il est exécuté sur un ordinateur idéal, renvoie la valeur f(x) en temps fini, pour toute valeur d’entrée x appartenant à l’ensemble A.
Exemple d’une fonction calculable : la fonction f : de N (ensemble des entiers) vers l’ensemble Booléen (Vrai, Faux) définie comme suit :
f(n) = Vrai, si n est premier,
f(n) = Faux, sinon.
De façon contrintuitive il y a bien peu de fonctions calculables car le code source du programme qui les calcule est une chaîne de caractères et les chaînes de caractères sont dénombrables. Le cardinal des fonctions non calculables est largement supérieur à celui des fonctions calculables. Paradoxalement il n’est pas simple de trouver une fonction particulière qui ne soit pas calculable. Alan Turing en a fourni une qui est célèbre :
soit h : fonction de l’ensemble des Programmes programmables sur ordinateur (ensemble noté Prog) vers Bool, définie pour chaque programme P de Prog par :
h(P) = Vrai, si P est total,
h(P) = Faux, sinon.
3) Ensembles énumérables :
Un programme P énumèreun ensemble A s’il produit, avec le temps, une liste (an) avec n entier (une énumération) d’éléments de A, dans laquelle chaque élément apparaît au moins une fois. La liste peut être infinie, elle ne sera alors jamais achevée, mais on exige seulement que le temps de production d’un nouvel élément soit toujours fini. Un ensemble A est énumérables’il existe un programme P qui l’énumère.
L’exemple le plus commun d’un ensemble infini énumérable est l’ensemble N des entiers naturels. L’énumération c’est ce que l’on fait lorsque l’on compte : Chaque entier n de N sera, en principe, éventuellement nommé si on est disposé à compter assez longtemps. De façon similaire, l’ensemble des chaînes de caractères sur un alphabet fini donné est énumérable : on peut faire la liste de toutes les chaînes de longueur 1, puis de toutes les chaînes de longueur 2 (en ordre alphabétique) et ainsi de suite.
La notion d’ensemble énumérable semble proche de celle d’ensemble dénombrable, elle est cependant différente. La notion d’ensemble énumérable est plus restrictive que la notion d’ensemble dénombrable : Un ensemble A est dénombrable s’il existe une bijection f : de l’ensemble N des entiers vers A, et la suite des f(n) avec n entier pourrait alors faire penser à une possible énumération de A. En fait chaque ensemble énumérable est dénombrable, mais la réciproque est fausse : la propriété que l’on exige en plus d’être dénombrable pour qu’un ensemble soit énumérable, c’est que la bijection f soit calculable.
L’ensemble des fonctions calculables est dénombrable, et on en déduit alors qu’il y a seulement une quantité dénombrable d’ensembles énumérables. Il y a toutefois beaucoup plus d’ensembles dénombrables que d’ensembles énumérables (on verra au chapitre Démonstration un exemple d’ensemble dénombrable qui n’est pas énumérable).
Le lemme suivant permet de construire à partir d’un ensemble énumérable, de nouveaux ensembles énumérables.
Lemme 1 : Soit A un ensemble énumérable et Pun programme total, qui à chaque élément de Aassocie un booléen. Alors l’ensembleB= {a ∈ Atel que P(a) = Vrai} est énumérable.
Démonstration :
Soit Pun programme qui dresse la liste de tous les éléments de A. On va décrire un programme, disons PB, qui dresse la liste de tous les éléments de B. On initialise le programme PBavec une liste vide.
Pour chaque élément a de A, on lance le programme P. Si P(a) = Vrai, le programme PBrajoute l’élément a à sa liste. Sinon, il ne fait rien et passe à l’élément suivant. On énumère ainsi tous les éléments de Aqui satisfont le prédicat encodé par le programme P, c’est-à-dire, tous les éléments de l’ensemble B.
4) Syntaxe des fonctions calculables :
Pour simplifier l’exposé on se restreint ici aux fonctions calculables d’une seule variable, de N versN.
Une fonction calculable de f de N dans N est définie par une formule qui décrit le processus de calcul à effectuer sur l’entrée x, pour obtenir l’image de x notée f(x). Cette formule peut être vue comme un programme P, qui pour une valeur n d’entier donne en sortie la valeur f(n) issue du processus de calcul. Elle peut aussi être vue comme une chaîne de caractères qui décrit dans le langage de l’arithmétique et en respectant les règles de syntaxes du langage de l’arithmétique, le processus de calcul à effectuer.
Par exemple la succession des caractères ‘(5 x + 2 )*(x + 2)’respecte les règles de la syntaxe de l’arithmétique, par contre ‘5x +/ ‘ou ‘(5 x + 2’ ne les respectent pas.
On exige donc d’un système formel que l’ensemble de ses formules soient exprimées en respectant les règles définies. C’est dire à que l’on doit avoir défini un processus algorithmique (un programme) qui prend en entrée une chaîne de caractères et qui détermine, en un temps fini, si cette chaîne est une formule conforme à la syntaxe ou pas. Ce programme de contrôle de la syntaxe est très comparable à ce que fait en informatique un compilateur.
Pour les systèmes logiques auxquels on s’intéresse, comme typiquement celui de l’arithmétique que l’on connait avec ses opérations addition et multiplication, les formules sont définies par récurrence, avec un alphabet symbolique assez restreint. Il en résulte un programme très simple pour déterminer si une chaîne donnée de caractères est une formule syntaxiquement correcte pour décrire le calcul sur un entier n de N.
5) Codage :
On considère f fonction de N dans N exprimée de façon syntaxiquement correcte. Comme on vient de le voir, elle s’écrit sous la forme f(x) = ‘une succession de caractères ou symboles’, cette succession respectant certaines règles de rédaction qui assurent que la formule exprimée par cette succession de caractères a un sens mathématique : c’est l’écriture symbolique de la formule. A chacun des caractères ou symboles de l’expression de la fonction on peut associer un entier ni (par exemple le code ASCII du caractère en question). A partir de la succession des entiers ni on peut construire un entier E (n1,n2,…nk) tel que connaissant E appartenant à l’ensemble des entiers correspondant à un code on en déduit la suite des ni, et tel que connaissant les nion en déduit le nombre E.
Exemple : chaque caractère sera codé par un nombre exprimé sur 8 bits (cela donne 256 caractères possibles). L’ensemble des codes des caractères mis bout à bout donne une chaîne de k fois 8 bits, où k est le nombre de caractères, ce qui correspond à un entier exprimé en base 2, que l’on peut aussi exprimer en base 10. Réciproquement, en partant d’un nombre qui en base 2 s’exprime par un nombre s’étalant sur k fois 8 bits, on peut lui faire correspondre une succession de caractère en associant à chaque groupe de 8 bits le caractère correspondant.
Remarque : En limitant le nombre de caractère à 255, on pourra toujours s’arranger pour que le code 0 ne soit pas utilisé pour un caractère de l’alphabet, et puisse avoir une autre signification.
Le processus de décodage DECOD de N dans Booléen, définit par :
DECOD(k) = Vrai, si k est le code d’une fonction calculable exprimée de façon syntaxiquement correcte,
DECOD(k) = Faux, sinon.
est calculable, car il est exécuté par une succession finie d’opérations d’examen du respect de la syntaxe.
On note pour la suite Γ l’ensemble des entiers qui sont le code d’une fonction calculable qui respecte les règles de syntaxe imposées par le système logique, et sont produits par le processus de codage décrit précédemment. Γ ne contient que des entiers, mais Γ n’est qu’un sous ensemble de N car tout entier, après décodage, ne produit pas forcément une écriture symbolique valide / applicable.
6) Cohérence et complétude
Définition 3 : Un système Λ est incohérent s’il existe un énoncé St qui est à la fois démontré et réfuté par Λ. Si Λ n’est pas incohérent, on dit qu’il est cohérent.
Il va de soi que la cohérence est une propriété souhaitable en vertu du principe « ex falso sequitur quodlibet » (d’une contradiction découle n’importe quoi). Dans un tel système, l’incohérence entraîne que tout, et son contraire, se démontre trivialement, ce qui en détruit l’intérêt.
Définition 4 : Un système formel Λ est complet si pour tout énoncé St, ou bien Λ démontre St, ou alors Λ réfute St. Si Λ n’est pas complet, on dit qu’il est incomplet.
Démonstration du 1er théorème d’incomplétude de Gödel
La démonstration présentée dans cet article est une reformulation simplifiée construite à partir des articles listés dans la bibliographie. Elle perd en rigueur et en généralité ce qu’elle gagne en accessibilité pour un public de lecteurs élargi.
Avant d’entrer dans le vif de la démonstration, nous faisons une première approche du raisonnement en se concentrant sur la démonstration d’un premier théorème qui est facilement accessible. Cela permettra de mieux comprendre le mécanisme utilisé par la suite.
Théorème : Il existe des sous-ensemble de N qui sont dénombrables, mais non énumérables.
Démonstrations :
On considère que l’on dispose d’une fonction de codage telle que pour chaque k, on sait dire si k est valide pour une fonction, et on en déduit la formule de la fonction.
Pour la suite, une fonction f de N dans N correspondant au code k sera notée : fk. Et l’on sait donc, à partir de k appartenant à Γ l’ensemble des entiers qui correspondent à un code, exprimer la fonction fk, et réciproquement connaissant fk exprimer k.
On considère le sous-ensemble de N, noté L défini par :
L = { n de Γ; n ∉ Image de fn }
Cet ensemble est mathématiquement défini : pour tout n de Γ on peut construire la fonction fn et lancer l’opération de calcul des fn(x).
Cet ensemble n’est pas vide : Par exemple le code des fonctions du type f(x) = x Mod 2, f(x) = x Mod 3 etc aura forcément un numéro de code très supérieur à 1 respectivement 2, car ces codes auront été déjà pris par des fonctions d’un seul caractère => les numéros de code de ces fonctions seront dans L.
Cet ensemble n’est pas non plus N : soit k1 le code de la fonction f(x) = x, k2 celui de la fonction f(x) = x + 1, k1 et k2 seront dans l’image de f, et donc les entiers k1 et k2 ne sont pas dans L.
L est un sous-ensemble de N, il est donc dénombrable, mais L n’est pas énumérable , en effet :
Si L est énumérable, alors il existe une succession finie d’opérations logiques qui pour chaque élément i de Γ est capable de dire en temps fini que cet élément n’est pas dans l’image de fi c’est à dire que la fonction g de N dans N définie par :
g(i) = ( i ∈ Γ = Vrai )*( i ∉ Image de fi = Vrai )*i
produira tous les éléments de L et eux seulement ∪ {0} (∪ symbole de Union). Cette fonction fait partie des fonctions calculables de N dans N, elle a donc un code dans Γ, disons que c’est le numéro k, il n’est pas nul. La fonction fk a pour image tous les éléments de L ∪ {0}, c’est à dire qu’elle liste tous les éléments de L ∪ {0}
Dans l’hypothèse où L est énumérable, l’énoncé ‘k ∈ L’ pour k de N non nul est-il vrai ?
Hypothèse 1 : k ∈ L
On en déduit, par définition de L que k n’est pas dans l’image de fk, donc fk ne produit jamais le numéro k, donc on n’a jamais fk(x) = k, or comme fk liste tous les éléments de L lorsque k est non nul, cela signifie que k ∉ L, en contradiction avec l’hypothèse.
Hypothèse 2 : k ∉ L
k étant un élément de Γ, on en déduit, par définition de L que k est produit par fk, c’est-à-dire qu’il existe x tel que fk(x) = k, et par définition de fk on en déduit que k est un élément de L, ce qui est en contradiction avec l’hypothèse.
En conclusion, si L est énumérable alors cela induit des conséquences contradictoires, donc, pour rester dans une théorie cohérente, on en déduit que L est un ensemble précisément défini, qui n’est pas vide, qui est dénombrable, mais qui n’est pas énumérable. Le théorème est démontré.
Appliquons maintenant le même type de raisonnement, mais en travaillant non plus seulement sur les fonctions arithmétiques et leurs opérations sur des entiers, mais aussi sur des propositions logiques et sur leurs démonstrations.
Notions complémentaires sur les systèmes logiques :
Outre les opérations de calcul sur les entiers ou booléens, le langage d’un système logique tel que l’arithmétique doit aussi être doté de la capacité :
à exprimer des ‘propositions logiques’ ou des énoncés que nous appellerons pour la suite des formules,
à démontrer certaines formules, c’est à dire fournir une suite valide de déductions logiques qui aboutit à la conclusion ‘La formule = Vrai’. Les règles de déductions à respecter sont définies par le système logique.
Les formules :
Les formules d’un système formel Λ peuvent être vues comme des chaînes de caractères conçues pour exprimer les propriétés de certains objets mathématiques ; elles peuvent donc être ou bien vraies, ou bien fausses. Les formules sont les phrases syntaxiquement correctes, ou expressions bien formées, d’un langage symbolique, telles que celle-ci :
f(n) = « ∀ d, (d | n) ⟹ (d = 1) ou (d = n) »
qui exprime la propriété mathématique ‘n est un nombre premier’ (cela peut être vrai ou faux selon la valeur de n). En revanche, des certaines chaînes de caractères telles que « ^9∃9n = U+ » ne sont pas des formules, même si elles utilisent le même alphabet, car elles ne sont pas construites en suivant les règles syntaxiques.
On exige donc d’un système formel Λ que l’ensemble F de ses formules soit exprimées en respectant des règles bien définies. C’est dire à que, là encore, comme pour l’écriture des fonctions arithmétiques avec leurs opérations et leurs variables, on doit avoir défini un processus algorithmique (un programme) qui prend en entrée une chaîne de caractères et qui détermine, en un temps fini, si cette chaîne respecte la syntaxe et est une formule ou pas.
Comme pour les fonctions de N dans N, il est possible de définir un code , nombre entier qui sera associé à chaque formule en suivant la même démarche que celle utilisée pour les formules.
Notons que puisque l’ensemble des chaînes de caractères est énumérable, alors par le Lemme 1, cette exigence entraîne que l’ensemble F des formules est énumérable à son tour.
Les démonstrations :
Les démonstrations, ou preuves, d’un système Λ sont constituées d’une succession logique de formules qui respectent les règles de déduction du système en question. Sans perte de généralité́, les preuves peuvent être amalgamées en une chaîne de caractères, comme un texte est un amalgame de phrases. Comme pour les formules, on exige donc que L soit accompagné d’un programme qui vérifie, étant donné une chaîne de caractères, s’il s’agit bien d’une preuve valide, auquel cas ce programme doit aussi pouvoir déterminer quelle est la conclusion (un énoncé, c’est-à-dire une formule qui n’a plus de variable libre) que cette preuve démontre. Si un énoncé́ φ s’avère être la conclusion d’une preuve valide, on dit qu’il s’agit d’un théorème du système Λ, ou encore, que Λdémontre φ.
Proposition 1 : Soit Λ un système formel. Alors l’ensemble des théorèmes de Λ est énumérable.
Démonstration : On procède de façon similaire au Lemme 1 pour décrire un programme, Thm, qui construit progressivement la liste de tous les théorèmes de Λ. On initialise le programme avec une liste vide.
On a déjà̀ vu que l’ensemble de toutes les chaînes de caractères étaient énumérables. Sur chaque élément de la liste des chaînes de caractères, on peut donc lancer le programme qui détermine si cette chaîne représente une preuve et qui, le cas échéant, trouve sa conclusion. Chaque fois que ce programme trouve une conclusion, qui est donc un théorème de Λ, le programme Thm rajoute celle-ci à sa liste. Sinon, il ne fait rien et passe à la chaîne suivante.
Puisque chaque théorème de Λ doit être la conclusion d’au moins une preuve, on obtient ainsi chaque théorème au moins une fois dans la liste de théorèmes produite par Thm.
Supposons donc que Λ soit un système formel cohérent. Alors on peut définir un programme Dem de l’ensemble des énoncés (c’est-à-dire des formules fermées) vers les booléens Vrai/ Faux, avec le résultat suivant : Dem(φ) = Vrai, si Λ démontre φ,
Dem(φ) = Faux, si Λ réfute φ.
En effet, puisque l’ensemble des théorèmes de Λ est énumérable (Proposition 1), il suffit donc de faire fonctionner le programme Thm jusqu’à voir passer la formule φ ou bien la formule qui exprime le contraire de φ (notée ¬φ) Le programme Dem surveille cette énumération et renvoie Vrai dès qu’il voit passer φ et Faux dès qu’il voit passer ¬φ. Ces deux situations ne peuvent pas toutes deux se produire pour une même instance, puisque Λ est cohérent. De plus l’une 2 sorties (Vrai ou Faux) va forcément se produire si le système est complet puisque dans un système complet toute formule Vrai peut être démontrée comme étant vraie et toute formule Faux peut être démontrée comme étant fausse. Dans un système cohérent et complet, le programme Dem est donc total, il ne peut y avoir de boucle infinie.
Nous voilà armés pour démontrer le théorème.
Démonstration du Théorème :
Nous nous plaçons dans le cas le cas où le système logique Λ est celui de l’arithmétique, ou un équivalent. Supposons que le système Λ soit cohérent et complet. Considérons les 2 ensembles G et E suivants :
G = { (n,m) de N2 ; ∃ ϕ formule d’1 variable, telle que ( m = code(ϕ) ) & ( Dem(ϕ(n)) = Vrai) }
En claire, G est l’ensemble des couples d’entiers (n,m) tels que m est le code d’une formule ϕ d’1 variable et cette formule ϕ qui a pour code m est démontrée = Vrai lorsque la variable prend la valeur n, c’est-à-dire ϕ(n) est Vrai, c’est-à-dire ϕ(n) est prouvable dans le système logique Λ. Si le système logique est cohérent et complet Les processus de vérification que m est le code d’une formule et (Dem(ϕ(n)) = Vrai) sont calculable et l’ensemble G est énumérable.
E = { n ∈ N; ∃ ϕ formule d’1 variable telle que (n = code(ϕ) ) & (Dem(ϕ(n)) = Faux) }.
Ce qui signifie que E est l’ensemble des entiers n tels que n est le code d’une formule ϕ d’1 variable, et ϕ est démontrée Faux lorsque la variable prend la valeur n, c’est-à-dire ϕ(n) est Faux, c’est-à-dire ϕ(n) n’est pas prouvable dans le système logique. Là encore l’ensemble E est énumérable dans l’hypothèse où le système logique est cohérent et complet.
Soit maintenant la formule Ψ(x) de la variable x définit par : ‘x ∈ E’. On note nx le code de cette formule.
Dans l’hypothèse où Λ est cohérent et complet, nous allons voir que la formule Ψ(x) appliquée à nx c’est-à-dire l’énoncé ‘nx ∈ E’ , n’est pas démontrable, c’est-à-dire que l’énoncé Ψ(nx) n’est pas prouvable dans le système logique.
Hypothèse 1 : Dem (Ψ (nx) ) = Vrai.
Donc la formule ‘nx ∈ E’ est démontrée Vrai pour nx, c’est-à-dire (Ψ(nx) est prouvable dans le système logique de l’arithmétique de Peano.
⟹ nx ∈ E
⟹ ∃ ϕ formule d’1 variable telle que (nx = code(ϕ) ) & (Dem(ϕ(nx)) = Faux)
⟹ (nx, nx) ∉ G, par définition de G,
⟹ ¬(∃ ϕ formule d’1 variable telle que ( nx = code(ϕ) ) & (Dem(ϕ(nx)) = Vrai) ) par définition de G
⟹ ∀ ϕ formule d’1 variable : (nx n’est pas le code de ϕ) ou (Dem(ϕ(nx)) = Faux)
Ce résultat est donc applicable à Ψ : ⟹ (nx n’est pas le code de Ψ) ou (Dem(Ψ(nx)) = Faux )
Or par définition de nx, nx est le code de Ψ, cela implique Dem(Ψ(nx)) = Faux
En synthèse : Dem (Ψ(nx) ) = Vrai ⟹ Dem (Ψ(nx) ) = Faux
Hypothèse 2 : Dem (Ψ(nx) ) = Faux
Donc la formule ‘nx ∈ Q’ est démontrée Faux pour nx
⟹ nx ∉ E
⟹ ¬(∃ ϕ formule d’1 variable telle que (nx = code(ϕ) ) & (Dem(ϕ(nx)) = Faux) )
⟹ ∀ ϕ formule d’1 variable : ¬ ( ( nx = code(ϕ) ) & (Dem(ϕ(nx)) = Faux) par définition de E
⟹ ∀ ϕ formule d’1 variable : ( nx n’est pas le code de (ϕ) ) ou (Dem(ϕ(nx)) = Vrai) par définition de E
On applique cette formule à Ψ : (nx n’est pas le code de Ψ) ou (Dem(Ψ(nx)) = Vrai)
Or par définition de nx, nx est le code de Ψ, cela implique Dem(Ψ(nx)) = Vrai
En synthèse : Dem (Ψ(nx) ) = Faux ⟹ Dem (Ψ(nx) ) = Vrai
Ainsi à partir de l’hypothèse que le système est cohérent et complet on obtient que le système devient incohérent. Si l’on fait l’hypothèse (souhaitable) que le système est cohérent, alors on est obligé d’admettre qu’il est incomplet et donc qu’il y a des formules indémontrables. Ces formules peuvent être vraies ou fausses, mais on ne peut démontrer ni l’un ni l’autre.
Exemple de problème non résoluble
Lors de la publication des théorèmes d’incomplétude de Gödel, la majorité des mathématiciens ont pensé que ces théorèmes indémontrables consistaient en des constructions abstraites auto-référentes formant une zone à part, sans signification mathématiquement réellement intéressante. Cette zone serait totalement invisible et on ne la rencontrerait jamais dans les mathématiques usuelles.
Le cas du théorème de Goodstein montre qu’il n’en est rien. Ce théorème que l’on va présenter et dont l’énoncé est naturel a été démontré en 1944 par Reuben Goodstein. Sa démonstration est construite dans le système logique de la théorie des ensembles qui est un système logique plus puissant que l’arithmétique ordinaire, dite de Peano.
En 1982, les mathématiciens Laurence Kirby et Jeffrey Paris démontrèrent que le théorème de Goodstein était indémontrable dans l’arithmétique de Peano.
Définition d’une suite de Goodstein :
Avant de définir une suite de Goodstein, définissons d’abord ce que l’on appelle la notation héréditaire en base b.
Pour écrire un entier naturel n avec une telle notation, on l’écrit d’abord sous sa forme classique de décomposition en base b :
n = akbk+ ak-1bk-1 + … + a1 b + a0,
où chaque ai est un entier compris entre 0 et b-1, mais où les exposants k sont en général exprimés en base 10.
Par exemple 1027 = 210 + 21 + 1
La notation héréditaire en base b exige que les exposants k soient eux aussi exprimés par une décomposition héréditaire en base b. Cela conduit à un traitement itératif des exposants k jusqu’à ce qu’ils soient tous exprimés en notation héréditaire en base b. On obtient à la fin une expression constituée uniquement d’entiers entre 0 et b-1.
Reprenons l’exemple de 1027, et donnons sa notation héréditaire en base 2 :
Première itération 1027 = 210 + 21 + 1
Deuxième itération 1027 = 22^3 + 2 + 21 + 1 (on a exprimé l’exposant 10 en base 2)
Troisième itération 1027 = 22^(2^1+1) + 2 + 21 + 1 (on a exprimé l’exposant 3 en base 2 et il ne reste plus que des exposants exprimés en notation héréditaire de base 2).
La suite de Goodstein d’un entier m, notée G(m), est définie comme suit :
Le premier élément de la suite est m. G1(m) = m. On écrit G1(m) en notation héréditaire en base 2.
Pour obtenir le deuxième élément de la suite, G2(m), on remplace dans l’expression de G1(m) tous les 2 par des 3 et on soustrait 1 au résultat. On exprime le résultat de la soustraction en notation héréditaire de base 3.
Pour obtenir le troisième élément de la suite, G3(m), on remplace dans l’expression de G2(m) tous les 3 par des 4 et on soustrait 1 au résultat. On exprime le résultat de la soustraction en notation héréditaire de base 4.
Et ainsi de suite…
Plus formellement, la suite G(m) est définie par :
G1(m) = m, écrire G1(m) en base 2,
Les Gn(m) suivant sont donnés par l’itération à chaque étape n des 2 opérations suivantes :
Prendre l’entier Gn-1(m) écrit en notation héréditaire de base (n). Remplacer tous les n par (n+1)
Soustraire 1 et exprimer le résultat avec la notation héréditaire de base (n+1). Cela donne Gn+1(m)
La suite s’arrête dès que l’on arrive à une étape qui donne Gi(m) = 0.
Les toutes premières suites de Goodstein par exemple les suites G(1), G(2), ou G(3) se terminent rapidement.
Ainsi la suite G(1) donne :
Etape 1 : G1(1) = 1 qui en notation héréditaire en base 2 = 1
Etape 2 : G2(1) = 1 – 1 = 0 la suite s’arrête
La suite G(2) donne :
Etape 1 : G1(2) = 2 qui en notation héréditaire en base 2 = 21
Etape 2 : G2(2) = 31 – 1 = 2 qui en notation héréditaire en base 3 = 2
Etape 3 : G3(2) = 21 – 1 = 1 qui en notation héréditaire en base 4 = 1
Etape 4 : G4(2) = 1 – 1 = 0 La suite s’arrête
La suite G(3) donne :
Etape 1 : G1(3) = 3 qui en notation héréditaire en base 2 = 21 + 1
Etape 2 : G2(3) = 31 + 1 – 1 = 3 qui en notation héréditaire en base 3 = 31
Etape 3 : G3(3) = 41 – 1 = 3 qui en notation héréditaire en base 4 = 3
Etape 4 : G4(3) = 3 – 1 = 2 qui en notation héréditaire en base 5 = 2
Etape 5 : G5(3) = 2 – 1 = 1 qui en notation héréditaire en base 6 = 1
Etape 6 : G6(3) = 1 – 1 = 0 La suite s’arrête
Mais les suites de Goodstein croissent en général pendant un grand nombre d’étapes, Par exemple, la suite G(4) commence comme suit :
N° de l’étape
Valeur de G(4) à l’étape
1
4 = 22
2
26 =2·32 + 2·3 + 2
3
41 =2·42 + 2·4 + 1
4
60 =2·52 + 2·5
5
83= 2·62 + 6 + 5
6
109 = 2·72 + 7 + 4
…
…
10
253 =2·112 + 11
11
299 =2·122 + 11
…
…
22
1058 = 2·232
23
1151 = 242+23·24+23
…
…
Le numéro de l’étape pour lequel la suite G(4) se termine possède plus de 120 millions de chiffres, ce qui signifie que le nombre de termes de la suite G(4) est de l’ordre de 10120 000 000.
De son côté la suite G(5) ne croît pas beaucoup plus vite, mais elle le fait bien plus longuement, au point que les notations usuelles ne permettent même plus d’exprimer le numéro de l’étape à pour laquelle la valeur de la suite G(5) est maximale. Elle finit néanmoins aussi par atterrir sur 0.
Cependant, ces deux exemples ne sont rien par rapport à G(19) dont la croissance est faramineuse : elle est en n à la puissance n à la puissance 7. Ce qui donne :
G1(19) = 19
G2(19) = 7 625 597 484 990
G3(19) = environ 1,3 × 10154
…
G8(19) = environ 4,3 × 10369 693 099
Et cette croissance se poursuit ainsi pendant un nombre d’étapes lui-même faramineux. Néanmoins elle finit par revenir à 0.
Théorème de Goodstein :
Quelle que soit la valeur initiale de m, la suite de Goodstein G(m) se termine par 0.
Compte tenu de ce que l’on vient de voir sur les exemples de suite G(4), G(5), G19, on comprend que ce théorème n’avait rien d’évident. Il y a pourtant une démonstration qui prouve qu’il est vraie en utilisant la théorie des ensembles. En revanche ce résultat est indémontrable avec l’arithmétique usuelle.
Bibliographie
Cet article a été construit principalement à partir des 2 premières références listées dans cette bibliographie.
Le théorème, formulé dans une version un peu provoquante affirme que si nous, les humains, avons notre libre arbitre, alors les particules élémentaires ont forcément leur propre part d’un libre arbitre du même type. Plus précisément, si l’expérimentateur peut librement choisir les directions dans lesquelles orienter son appareil pour faire une certaine mesure, alors la réponse de la particule (pour être plus exact, la réponse de l’univers autour de la particule) n’est pas déterminée par toute l’histoire antérieure de l’univers.
Autrement dit, s’il y a un peu de libre arbitre pour les gros systèmes physiques que nous sommes, alors l’Univers est plein de libre arbitre et celui-ci est aussi microscopique.
Sous une forme plus rigoureuse, le théorème repose sur 3 axiomes nommés SPIN, TWIN, et MIN. Les 2 premiers sont liés à la mécanique quantique, et le dernier est lié à la relativité et à l’idée que l’expérimentateur est libre de ses choix. Il affirme alors :
Les axiomes SPIN, TWIN, et MIN impliquent que la réponse d’une particule de spin 1 à une triple expérience est libre, c’est-à-dire qu’elle n’est pas fonction des propriétés de cette partie de l’univers qui est antérieure à cette réponse et cela par rapport à n’importe quel référentiel inertiel.
Histoire du théorème
« Le théorème du libre arbitre » est le résultat de l’association de 2 mathématiciens John H. Conway et Simon B. Kochen, ce dernier étant aussi spécialistes de mécanique quantique. Une première version a été présentée dans un article publié dans Foundations of Physics en 2006. Une version dite renforcée a été ensuite produite en 2009. Renforcée dans le sens où l’un des 3 axiomes nécessaires à la démonstration a été remplacé par un axiome plus faible (c’est-à-dire moins exigeant). Concrètement l’axiome FIN avec l’hypothèse du libre choix des expérimentateurs et de la causalité temporelle (ce qui paraissait déjà raisonnable) a été remplacé par l’axiome MIN qui permet aux réactions des particules de dépendre des demi-espaces passés plutôt que seulement des cônes de lumière passés (c’est-à-dire que la vitesse de la lumière n’est plus supposée limitée, elle pourrait être infinie).
Il est l’aboutissement d’une série de théorèmes apparus depuis le début des années 1960 sur la mécanique quantique avec en particulier le théorème de Bell en 1964, et le paradoxe Kochen-Specker en 1967 qui est un élément central de la démonstration.
Le principe de la démonstration
La démonstration présentée ici suit scrupuleusement l’article publié par les auteurs John Conway et Simon Kochen en 2009 pour le théorème dans sa version forte.
Le théorème se base sur l’idée que deux expérimentateurs humains nommés A et B séparés par une certaine distance vont procéder à des mesures sur des particules atomiques, a et b, et utiliser leur libre-arbitre pour choisir, au dernier moment, quelle mesure ils vont faire. Plus précisément, ils vont effectuer chacun des mesures de spin sur une particule élémentaire, à savoir l’expérimentateur A sur la particule a et l’expérimentateur B sur la particule b, mais ces deux particules seront « intriquées ». Les deux expérimentateurs vont faire ces mesures quasi simultanément, de telle sorte que chaque expérimentateur n’a pas la possibilité de transmettre l’information « je vais faire la mesure suivant cet axe » à l’autre avant que ce dernier n’ait enregistré le résultat de sa mesure.
Le théorème repose sur trois axiomes nommés « Spin », « Twin », et « Min ».
« Spin » : le carré des composantes de spin de certaines particules de spin 1, mesuré dans trois directions orthogonales, est toujours une permutation de (1,1,0).
« Twin » : Il est possible « d’intriquer » deux particules élémentaires et de les séparer spatialement ensuite, de telle manière que si on mesure ensuite leur spin selon deux directions identiques (c’est-à-dire parallèles), les carrés de la composante de spin suivant cette direction seront identiques pour les 2 particules.
« Min » : cet axiome combine principe de causalité temporelle et principe de libre arbitre des expérimentateurs. Pour ce qui est du principe de causalité temporelle, il fait l’hypothèse que l’avenir ne peut pas modifier le passé. Exprimé sous sa forme relativiste cela signifie qu’un événement ne peut pas être influencé par ce qui se passe plus tard dans un référentiel inertiel donné quel qu’il soit. Une autre hypothèse, généralement tacitement utilisée, est que les expérimentateurs sont libres de choisir entre les expériences possibles. Cela conduit à pouvoir dire que le choix d’un expérimentateur n’est pas fonction du passé. L’axiome MIN repose sur quelques cas très particuliers de ces hypothèses.
Ces trois axiomes sont parfaitement « raisonnables » au sens où les physiciens quantiques les considèrent comme vrais tous les trois. En particulier si « Spin » ou « Twin » étaient faux les fondements même de la mécanique quantique seraient ébranlés. Ilssont utilisés dans une expérience de pensée au cours de laquelle les expérimentateurs A et B font des mesures de spin suivant des directions qui sont choisies parmi un ensemble particulier de directions, à savoir la configuration de Peres : elle comprend 33 axes d’orientation différentes et est associée à 40 trièdres orthogonaux.
La démonstration du théorème proprement dit et courte et découle très directement de l’application des 3 axiomes mis en œuvre avec la configuration de Peres. Cette configuration n’est pas compatible avec une certaine propriété, dite 101, or si l’on admet les conséquences logiques des 3 axiomes alors nous devons admettre le libre arbitre de la paire de particule intriquée a, b (libre arbitre au sens de Conway/Kochen) car sinon la configuration de Peres aurait la propriété 101.
La configuration de Peres et ses propriétés sont un passage obligé pour appréhender ensuite la démonstration, et sont longuement présentées dans le paragraphe Boîte à outils.
Boîte à outils
1) Définition du libre arbitre au sens de Conway/Kochen :
Dire que le choix de x, y, z de A est libre signifie pour les auteurs qu’il n’est pas déterminé par (c’est à dire n’est pas une fonction de) ce qui s’est passé auparavant (dans n’importe quel référentiel inertiel). Le théorème établit la conséquence surprenante que la réponse d’une particule doit être libre dans exactement le même sens, que cette réponse n’est pas une fonction de ce qui s’est passé plus tôt (par rapport à n’importe quel référentiel inertiel).
Ce libre arbitre, qui n’a rien à voir avec les notions de probabilités puisqu’il affirme juste la non-existence d’une certaine fonction. Il s’agit d’un indéterminisme logique (ou si l’on veut préciser, fonctionnel). Cet indéterminisme est l’impossibilité́ logique qu’il existe certaines fonctions reliant les états de l’Univers, impossibilité́ qui signifie que d’instant en instant l’Univers n’est pas contraint par son passé, mais libre de son évolution.
2) La configuration de Peres et la propriété 101 :
Considérons un cube de centre C et les 3 axes x, y, z parallèles aux arrêtes du cube.
Figure 1
Les axes x, y et z sont 3 axes de symétrie de ce cube. Les points d’intersection de ces axes avec le cube sont indiqués en noir. Le cube a 10 autres axes de symétrie, donnés par les directions en bleu de la figure suivante. Les intersections de ces axes de symétrie avec le cube sont données par les points en bleu.
Figure 2
Ces 13 axes définissent 13 directions, numérotées de 1 à 13 dans la figure 3 qui associe à chaque axe le point d’intersection avec le cube, et le numéro d’axe correspondant. Parmi ces axes, plusieurs triplets forment un repère orthogonal : par exemple (8,9,3), (1,13,7), (11,2,5), …
Figure 3
Faisons maintenant tourner de 45° autour de z l’ensemble de ces 13 axes (figure 4).
Figure 4
Suite à cette rotation :
L’axe 3 reste sur 3,
L’axe 1 devient 9, 9 devient 2, 2 devient 8, et 8 devient 1,
L’axe 4 se retrouve dans le plan (x,z) et coupe le cube initial en un nouveau point 4z,
L’axe 5 se retrouve sur le plan formé par z et la diagonale des axes x et y. Il coupe le cube en un nouveau point 5z.
De même les axes 6, 7 10, 11, 12, 13 se retrouvent sur des directions nouvelles par rapport aux 13 directions de départ, et intersectent le cube en des nouveaux points 6z, 7z, 10z, 11z, 12z, 13z.
Par cette opération nous avons construit les axes 3, 9, 2, 8, 1 ainsi que 8 axes supplémentaires, identifiés par les points 4z, 5z, 6z, 7z, 10z, 11z, 12z, 13z. Nous disposons des axes construits suivants : 1, 2, 3, 8, 9, 4z, 5z, 6z, 7z, 10z, 11z, 12z, 13z.
Effectuons une rotation de 45° autour de l’axe x pour les 13 axes de départ (figure 5).
Figure 5
Suite à cette rotation :
L’axe 1 reste sur 1,
L’axe 2 devient 7, 7 devient 3, 3 devient 13, et 13 devient 2,
L’axe 4 se retrouve dans le plan (x,y) en diagonale des directions x et y, et coupe le cube initial en un nouveau point 4x,
L’axe 5 se retrouve en 5x.
De même les axes 6, 8, 9, 10, 11, 12 se retrouvent sur des directions nouvelles par rapport aux 13 directions de départ, et intersectent le cube en des nouveaux points 6x, 8x, 9x, 10x, 11x, 12x.
Nous avons ainsi construit les axes 1, 7, 3, 13, 2, 4x, 5x, 6x, 8x, 9x, 10x, 11x, 12x. Les axes construits par les rotations z plus ceux construits par les rotations x sont au nombre de 23, il s’agit de :
Effectuons maintenant une rotation de 45° autour de l’axe y pour les 13 axes de départ (figure 6).
Figure 6
Suite à cette rotation :
L’axe 2 reste sur 2,
L’axe 1 devient 11, le 11 devient 3, le 3 devient 5, et le 5 devient 1.
Nous faisons apparaître cette fois les nouveaux axes 4y, 6y, 7y, 8y, 9y, 10y, 12y, et 13y.
Par cette rotation nous avons ainsi construit les axes : 2, 11, 3, 5, 1, 4y, 6y, 7y, 8y, 9y, 10y, 12y, et 13y.
Le total des axes images des 13 axes initiaux, par les rotations autour de z, par les rotations autour de x, et par les rotations autour de y sont au nombre de 33, il s’agit de :
Ces 33 axes sont les axes de symétrie de la figure géométrique constituée par la superposition des cubes bleu, rouge et vert tels que présentés dans la figure 7 et qui sont chacun les images du cube initial par rotation de 45° autour de z (cube bleu), de 45° autour de x (cube rouge) et de 45° autour de y (cube vert).
Figure 7
La figure 8 représente les 33 points d’intersection des 33 axes avec le cube initial. La direction de chacun des axes est donnée par la droite passant par le centre du cube et le point d’intersection (nous confondons le nom du point et le nom de l’axe). Ces 33 axes constituent ce que l’on appelle la configuration de Peres.
Figure 8
La configuration de Peres contient 16 triplets orthogonaux, à savoir :
Ces trièdres sont chacun construits à partir de 3 axes orthogonaux appartenant à la configuration. Nous notons E16 cet ensemble de trièdres. Nous allons maintenant nous intéresser à un ensemble de trièdres plus large, qui est l’ensemble des trièdres qui peuvent être construits à partir d’au moins 2 axes orthogonaux appartenant à la configuration de Peres. Cet ensemble contient déjà les 16 triplets orthogonaux de E16. Il doit aussi contenir tous les trièdres qui ont 1 axe orthogonal à seulement une paire d’axes orthogonaux qui appartiennent la configuration de Peres.
Cela signifie par exemple que :
Il doit contenir le trièdre formé à partir des axes 5x et 9y auxquels on ajoute l’orthogonal au plan 5x, 9y
Il doit contenir le trièdre formé à partir des axes 8x et 7y auxquels on ajoute l’orthogonal au plan 8x, 7y
Idem pour les trièdres qui seront construits à partir de 11x, 8y ou 9x, 13y etc…
Nous trouvons dans la configuration de Peres 24 paires d’axes dont l’axe orthogonal à la paire en question ne fait pas déjà partie de la configuration. Ces paires sont facilement identifiables en prenant d’abord le plan contenant l’axe 3 et les 3 points 5x, 4y, et 8x, ainsi que le plan contenant l’axe 3 et les 3 points 7y, 12x et 9y. Comme ces 2 plan sont orthogonaux, chaque paire de points constituées d’un point du premier plan et d’un point du second plan donne une paire d’axes orthogonaux. Cela donne 9 paires, dont une, la paire 4y, 12x doit être éliminée car le trièdre 4y, 12x, 3 est dans E16. Nous obtenons ainsi 8 paires dont l’axe orthogonal à la paire en question n’est pas dans la configuration de Pères (on ne trouve pas ces paires dans l’un des 16 trièdres de E16). Les mêmes opérations répétées en utilisant les plans contenant l’axe 2 puis les plans contenant l’axe 1 donneront chacune 8 paires.
Chacune de ces paires permet de construire un trièdre qui n’est pas dans E16. Ces 24 trièdres sont forcément tous différents, en effet si 2 paires différentes conduisaient à construire le même axe orthogonal, cela signifierait que ces paires d’axes sont dans le même plan, et on peut vérifier que cela n’est pas le cas. Ajoutés aux 16 trièdres précédents, ces 24 nouveaux trièdres permettent de constituer un ensemble de 40 trièdres, que nous nommerons E40.
Convenons maintenant d’assigner à chaque axe d’un trièdre quelconque une valeur 0 ou 1. Pour tout trièdre nous dirons qu’il possède la propriété 101 si 2 des 3 axes du trièdre ont la valeur 1 et le troisième la valeur 0. Autrement dit, on ne trouve jamais 2 fois la valeur 0 pour toute paire d’axes orthogonaux de ce trièdre.
Théorème d’incompatibilité : il est impossible de distribuer des valeurs 1 ou 0 sur les 33 axes de la configuration de Peres d’une façon telle que tous les éléments de E40 aient la propriété 101.
Démonstration de l’incompatibilité :
Partons du triplet (1, 2, 3) et supposons qu’il ait la propriété 101, c’est-à-dire, sans perte de généralité, que les axes 1 et 3 prennent la valeur 1, et l’axe 2 la valeur 0.
Axe 2 à 0 implique que les axes 5 et 11 ont tous les 2 pour valeur 1.
L’axe 11, avec sa valeur 1, forme un trièdre avec les axes 7y et 9y (cf figure 6) donc : l’un de ces 2 axes 7y et 9y prend pour valeur 0 et l’autre 1. (1)
De la même façon 5 forme un trièdre avec 8y et 13y et l’un des 2 axes prend pour valeur 0 donc : l’un des 2 axes 8y et 13y prend pour valeur 0 et l’autre 1. (2)
Par rotation de 90° autour de 3, les axes 5x, 4y, 8x se retrouvent en 7y, 12x, 9y, ce qui montre que 4y est orthogonal à 7y et à 9y (le plan 5x, 4y, 8x passant par C et le plan 7y, 12x, 9y passant par C sont orthogonaux).
cas où 7y = 0 et 9y = 1 : 4y prend la valeur1 car 4y et 7y étant orthogonaux, ils ne peuvent pas être simultanément à 0 (cf lemme).
Cas ou 7y = 1 et 9y = 0 : 4y prend la valeur1 car 4y et 9y étant orthogonaux, ils ne peuvent pas être simultanément à 0.
Dans les 2 cas : 4y vaut 1.
Comme 3 et 4y valent 1 on en déduit que 12x vaut 0 par le triplet 3, 4y, 12x. 8x et 5x sont orthogonaux à 12x qui vaut 0, donc 8x et 5x ont pour valeur 1.
Raisonnons maintenant de la même façon pour les axes 9x, 6y, 11x qui, après rotation de 90° autour de 3 se retrouvent en 8y, 4x, 13y. Cette fois 6y est orthogonal à 8y et 13y qui valent (cf (2) ) 0 et 1 ou 1 et 0, donc 6y vaut 1. Le triplet 3, 6y, 4x est un triplet orthogonal, donc 4x vaut 0. 9x et 11x sont orthogonaux à 4x, ils sont donc tous les deux à 1.
Or, les axes 9x, 8x, 13 forment un triplet orthogonal, qui est l’image de 5, 11, 2 par la rotation de 45° autour de x. De même 5x, 11x, 7 est un triplet orthogonal image de 5, 11, 2 par la rotation -45° autour de x. On en déduit que 13 vaut 0, et que 7 vaut 0, donc le triplet 1, 7, 13 qui est orthogonal n’a pas la propriété 101. CQFD
Nota : il est impossible d’affecter des 0 ou 1 aux 33 axes de la configuration de Peres tout en ayant la propriété 101 pour les 40 trièdres de E40, en revanche il est possible d’affecter des 0 ou 1 aux 33 axes de la configuration tout en ayant la propriété 101 si l’on se limite aux 16 trièdres de E16.
Démonstration du théorème du libre arbitre
Quelques précisions sur les termes. Les mots « propriétés », « événements » et « information » sont utilisés presque de façon interchangeable, ‘un événement s’est produit ‘ est considéré comme une propriété et ‘une propriété est obtenue’ peut être codé par un bit d’information. Le sens général exact de ces termes, qui peut être différents dans certaines théories qui considèrent ces concepts, n’est pas important, car ils ne sont ici employés que dans le contexte spécifique des trois axiomes.
Pour ce qui est du sens à donner à la notion de libre arbitre, il faut se référer au paragraphe 1 de la Boîte à outil qui traite cette question.
Commençons par énoncer les 3 axiomes :
Axiome SPIN :
L’axiome implique l’opération appelée « mesure du spin carré d’une particule de spin 1 », qui produit toujours le résultat 0 ou 1. Un noyau d’hélium est par exemple une particule de spin 1.
Énoncé de l’axiome SPIN : Pour une particule de spin 1, la mesure des carrés des composants du spin suivants 3 directions orthogonales donnent toujours les réponses 1, 0, 1 dans un certain ordre.
La mécanique quantique prédit cet axiome puisqu’elle dit que pour une particule de spin 1 les composantes Sx, Sy Sz du spin suivants les axes x, y, et z vérifient: Sx2+Sy2+Sz2 = 2 avec x, y, z interchangeables, quel que soit le repère orthogonal de mesure.
Cette « propriété 101» est paradoxale puisque l’on vient de voir qu’elle ne peut mathématiquement pas être respectée suivant toutes les directions possibles alors que la mécanique quantique affirme elle que la relation Sx2+Sy2+Sz2 = 2 est vraie quelle que soit la direction. Malgré ce paradoxe aucun physicien ne remettrait en question la vérité de l’axiome SPIN, car il découle de la mécanique quantique, qui est l’une des théories scientifiques les plus fortement étayées de tous les temps. La notion de libre arbitre telle qu’utilisée dans le théorème donne la clé pour surmonter la contradiction.
Axiome TWIN
Un des faits les plus curieux de la mécanique quantique a été mis en évidence par Einstein, Podolsky, et Rosen en 1935. Il établit que bien que les résultats de certaines observations distantes ne peuvent pas être prédits individuellement à l’avance, ils peuvent être corrélés.
En particulier, il est possible de produire une paire de particules de spin 1 « jumelées » ou dites intriquées (en les plaçant dans un état de spin total nul) qui donnera pour des directions parallèles les mêmes réponses aux mesures de spin carré ci-dessus. L’axiome « TWIN » est inclus dans cette assertion.
Énoncé de l’axiome TWIN : Soit des particules jumelées de spin 1, et 2 expérimentateurs A et B. Supposons que l’expérimentateur A effectue une triple expérience de mesure sur le carré de la composante du spin de la particule a selon trois directions orthogonales x, y, z, tandis que l’expérimentateur B mesure la particule jumelée b dans une direction, w. Si w se trouve dans la même direction que l’une des mesures de x, y, z, alors l’expérimentateur B donnera nécessairement la même réponse que la mesure correspondante faite par l’expérimentateur A.
En fait, nous allons restreindre w, la direction choisie par l’expérimentateur B, à l’une des 33 directions de la configuration de Pères, et x, y, z, le triplet choisi par l’expérimentateur A, à l’un des 40 triplets orthogonaux de l’ensemble E40.
Axiome MIN :
L’un des paradoxes introduits par la théorie de la relativité fut le fait que l’ordre temporel dépend du choix du référentiel inertiel dans lequel les mesures sont faites. Si deux événements sont espacés, alors ils apparaîtront dans un ordre temporel dans certains référentiels inertiels, mais dans l’ordre inverse dans d’autres. Les deux événements que nous considérerons seront les mesures de spin jumelées telles que définies précédemment.
Il est habituel de supposer tacitement le principe de causalité temporelle qui est que l’avenir ne peut pas modifier le passé. Sa forme relativiste est qu’un événement ne peut pas être influencé par ce qui se passe plus tard dans un référentiel inertiel donné quel qu’il soit. Une autre hypothèse généralement tacite est que les expérimentateurs sont libres de choisir entre les expériences possibles. Dans cet article, libre choix s’entend au sens que le choix d’un expérimentateur n’est pas fonction du passé. L’axiome MIN n’utilise explicitement que quelques cas très particuliers de ces hypothèses.
Énoncé de l’axiome MIN : Supposons que les expériences effectuées par A et B sont séparées dans l’espace. Alors l’expérimentateur B peut librement choisir n’importe laquelle des 33 directions particulières w, et la réponse de la particule a est indépendante de ce choix. De même et indépendamment, A peut librement choisir l’un des 40 triplets d’axes x, y, z, et la réponse de la particule b est indépendante de ce choix.
C’est le libre arbitre des expérimentateurs qui permet les choix libres et indépendants du triplet d’axe x, y, z et de l’axe w. Mais dans un référentiel inertiel — appelons-le le référentiel « A d’abord » — l’expérience de B ne se produira qu’un peu plus tard que A, et donc la réponse de A ne peut pas, par causalité temporelle, être affecté par le choix ultérieur de B de w. Dans un référentiel « B d’abord » la situation est inversée, justifiant la dernière partie de MIN.
Démonstration :
Les conditions de l’expérience sont les suivantes :
les expérimentateurs A et B sont séparés dans l’espace par une distance suffisante pour que les choix et conditions de l’expérience faites par A respectivement B n’interfèrent par sur B respectivement A.
A et B vont faire des mesures de spin sur une paire de particule a et b qui sont intriquées : l’expérimentateur A fait des mesures sur a et B sur b.
A choisit de faire les mesures de spin de la particule a selon 3 axes x, y, z qui sont l’un des 40 triplets de E40 construits à partir de la configuration de Pères. La réponse (le carré du spin) suivant ces 3 axes sera (1,0,1), ou (1,1,0), ou (1,0,1).
B choisit de la mesure de spin de la particule b selon l’axe w qui est l’un des 33 axes de la configuration de Pères. La réponse (le carré du pin) suivant cet axe sera 0 ou 1.
Nous supposons vrais les 3 axiomes et raisonnons par l’absurde en faisant l’hypothèse que les particules en question n’ont pas leur libre arbitre, c’est-à-dire :
que la réponse (i, j, k) d’une particule a à la triple expérience de mesure suivant les axes x, y, z est donnée par une fonction de plusieurs propriétés α1, α2, … définies dans un repère inertiel F et dont l’état est défini antérieurement à cette réponse. Nous noterons cela sous la forme θFa(α) = réponse à l’expérience = détermination du triplet qui sortira parmi les 3 possibles (0,1,1) ou (1,0,1) ou (1,1,0) (pour alléger la notation a représente ici l’ensemble des propriétés αi)
que la réponse de la particule b suivant la direction w (réponse qui est soit 0 soit 1) est donnée par une fonction de plusieurs propriétés β1, β2, … définies dans un repère inertiel G possiblement différent de F et dont l’état est défini antérieurement à cette réponse. Ce que nous noterons de la même façon : θGb(β) = réponse à l’expérience = 0 ou 1.
A partir de maintenant, nous pouvons supposer qu’aucun nouveau bit d’information n’influence les réponses des particules, et donc que α et β sont des fonctions des choix des expérimentateurs respectifs et des événements antérieurs à ces choix. Il se peut qu’une des propriétés α varie aussi selon les axes x, y, z et elle peut, ou non, varier aussi avec w. Dans tous les cas, que la fonction varie avec eux ou non, nous allons voir que nous pouvons introduire tous les x, y, z, w comme nouveaux arguments et réécrire θFa comme une nouvelle fonction (nous lui donnons le même nom pour plus de commodité) dont les arguments ne sont plus les αi mais seront x, y, z, w, et des propriétés αi’ indépendantes de x, y, z, w.
θFa(x, y, z, w ; α’ ) (*) , fonction de x, y, z, w et des propriétés αi’ indépendantes de x, y, z, w.
En effet, pour les αi qui dépendent effectivement de x, y, z, w nous pouvons éliminer cette dépendance en injectant à la place les valeurs constantes qui peuvent être prises par x, y, z, w : il y a 40 x 33 = 1320 valeurs de quadruplets possibles pour les x, y, z, w que nous utiliserons. Sinon, pour toute fonction α qui serait purement une fonction α(x, y, z, w) de x, y, z, w, nous pouvons retirer ces fonctions de la partie α dans (*) pour ne laisser dans α’ que des bits d’information indépendants de x, y, z, w.
De la même façon nous pouvons réécrire θGbcomme la fonction θGb(x, y, z, w ; β’) de x, y, z, w et des propriétés β’ indépendantes de x, y, z, w.
Pour le choix particulier que fera B, il y a une valeur β0’ de β’ pour laquelle θGb(x, y, z, w ; β0’) est défini. Compte tenu de l’indépendance de β’ par rapport à w vue précédemment la fonction θGb(x, y, z, w ; β0’) peut être définie avec la même valeur β0’ pour toutes les 33 valeurs de w (le fait que l’axiome MIN permette à B de modifier librement son choix de w rend cela intuitivement clair). Nous remarquons aussi que l’axiome MIN permet de dire que la réponse de la particule b ne peut pas varier en fonction de x, y, z. Donc θGb(x, y, z, w ; β0’) est seulement fonction de w. Nous écrirons θGb(x, y, z, w ; β0’) =θG0(w).
De la même façon il y a une valeur α0’ de α’ pour laquelle la fonction θF1(x, y, z) = θFa(x, y, z, w ; α0’) est définie pour les 40 triplets x, y, z et qui est aussi indépendante de w, ce qui permet dès lors d’omettre cet argument.
Mais par l’axiome TWIN nous avons l’équation :
θFa(x, y, z, w ; α0’) = θGb(x, y, z, w ; β0’), ce qui donne :
θF1(x, y, z) = θG0(x) si w = x, θG0(y) si w = y, θG0(z) si w = z.
Nous avons donc une fonction mathématique θGo qui pour chaque axe w de la configuration de Peres attribue la valeur 0 ou 1 (= réponse de la mesure à l’expérience) et telle que ses composantes suivant 2 axes orthogonaux à w vérifient avec w la propriété 101. Cela signifie que la fonction mathématique θGo permet d’attribuer la propriété 101 à tous les trièdres de E40. Or nous avons vu dans le chapitre Boîte à outil que cela n’est pas possible. CQFQ.
Conclusion : Sous réserve d’accepter les 3 axiomes, on se doit de conclure qu’il ne peut pas y avoir de fonction mathématique qui décrive ce que va être le résultat de l’expérience, le résultat ne peut pas être une fonction mathématique du passé ou même de l’instant auquel est faite la mesure. Le résultat n’émerge d’aucune logique accessible, d’aucun passé exprimable, comme s’il n’était que le choix de la particule elle-même, ou plus exactement le choix du couple de particule intriqué a, b.
Annexe
Commentaires des auteurs John Conway et Simon Kochel sur le théorème.
A-1) Sur la démonstration elle-même :
Si l’une de ces fonctions θFa(a), ou θGb(b), est influencée par une information « libre » (libre dans le sens où cette information ne résulte pas du choix fait par A sur les directions et événements préalablement à ce choix vu du repère F), alors il y a un instant t0 au plus tôt, après lequel cette information est disponible pour la particule a. Comme les informations « non libres » sont aussi disponibles à t0, tous les bits d’information, libres et non libres, ont une valeur définie 0 ou 1 qui entrent en argument de la fonction θFa (de même que θGb). On considère donc que la réponse de la particule a démarré à l’instant t0. Si en effet, il y a un bit libre qui influence la particule a, l’univers a, par définition, pris une décision libre autour du temps t0, et l’on attribuera cette décision simplement à la particule a plutôt que de l’attribuer de façon plus précise mais pédante à l’univers qui est en toute proximité de la particule.
(i) Étant donné que la scène observée sur l’écran est le résultat d’une cascade d’événements légèrement antérieurs, il est difficile de définir précisément quand « la réponse » commence vraiment. Nous allons maintenant expliquer pourquoi on peut considérer la réponse de a comme ayant déjà commencé à n’importe quel instant postérieur au choix de A alors que tous les bits d’information libres qui l’influencent sont devenus disponibles à a.
Soient N(a) et N(b) des régions convexes de l’espace-temps juste assez grandes pour être « dans le voisinage des expériences respectives », c’est-à-dire qu’elles contiennent les informations de réglages choisis pour l’appareillage de mesure et les réponses associées de la particule. Notre preuve a montré que si le demi-espace temporel arrière t < tF déterminé par un temps tF dans un référentiel F donné est disjoint de N(a), alors l’information disponible qu’il contient n’est pas suffisante pour déterminer la réponse de a. D’un autre côté, si chacun des 2 deux demi-espaces (F et G) contient juste son voisinage respectif, alors bien sûr, ils contiennent chacun déjà les réponses. En faisant varier F et G, cela permet de localiser les décisions libres dans chacun des voisinages, ce qui justifie notre attribution du libre arbitre aux particules elles-mêmes.
(ii) Nous remarquons que nous n’avons pas besoin d’interdire à toute l’information contenue dans le demi-espace G-En-Arrière d’être disponibles pour b, car en fait MIN empêche la fonction θGb de la particule b d’utiliser le choix des directions x, y, z fait par l’expérimentateur A. La raison sous-jacente est bien sûr que la relativité nous permet de voir la situation à partir d’un référentiel B-d’abord, dans lequel le choix de A n’est effectué qu’après la réponse de b, de sorte que A est toujours libre de choisir arbitrairement un des 40 triplets. Cependant, et c’est là notre seule utilisation de l’invariance relativiste, le raisonnement utilisé permet en fait à toute information qui ne révèle pas le choix de A d’être transmise à une vitesse supérieure à celle de la lumière, ou même à l’envers dans le temps.
(iii) Bien que nous ayons exclu la possibilité que θGb puisse varier avec le choix des directions fait par A, il est concevable qu’il puisse néanmoins varier avec la réponse (future!) de a. Cependant, θGb ne peut pas être affecté par la réponse de a à un triplet inconnu choisi par A, puisque la même information est transmise par les réponses (0, 1, 1), à (x, y, z), (1, 0, 1) à (z, x, y) et (1, 1, 0) à (y, z, x). Pour une raison similaire θFa ne peut pas utiliser la réponse de b, puisque l’expérience de B pourrait consister à examiner des triplets orthogonaux u, v, w et rejeter les réponses correspondant à u et v.
(iv) On pourrait objecter que le libre arbitre lui-même pourrait en quelque sorte dépendre du référentiel. Mais notre preuve repose sur le choix libre des directions, qui, puisqu’il se concrétise dans l’orientation de certains appareils macroscopiques, doit être le même que vu de n’importe quel référentiel.
(v) Enfin, nous notons que la preuve présentée implique quatre référentiels inertiels : A-premier, B-premier, F, et G. Ce nombre ne peut être réduit sans affaiblir notre théorème, puisque nous voulons qu’il s’applique aux cadres arbitraires F et G, y compris par exemple ceux dans lesquels les deux expériences sont presque simultanées.
A-2) Sur les conséquences philosophiques du théorème sur la question du libre arbitre vs déterminisme :
Certains lecteurs pourraient s’élever contre notre utilisation du terme « libre arbitre » pour décrire l’indéterminisme de la réponse des particules. Notre attribution provocante de la notion de libre arbitre aux particules élémentaires est délibérée, puisque notre théorème affirme que si les expérimentateurs ont une certaine liberté, alors les particules ont exactement le même genre de liberté. Effectivement il est naturel de supposer que cette liberté (la même notion de liberté que celle attribuée aux particules) est l’explication ultime de la nôtre.
Les humains qui choisissent x, y, z et w peuvent bien sûr être remplacés par un programme informatique contenant un générateur de nombres pseudo-aléatoires. Si nous rejetons comme ridicule l’idée que les particules pourraient être au courant de ce programme, alors notre preuve reste valide. Cependant, le libre arbitre serait toujours nécessaire pour choisir le générateur de nombres aléatoires, seul un déterministe déterminé pourrait soutenir que ce choix a été fixé dès l’aube du temps.
Nous avons supposé que les choix d’orientation des expérimentateurs de la configuration Pères sont totalement libres et indépendants. Cependant, la liberté que nous avons déduite pour les particules est plus limitée, puisqu’elle est limitée par l’axiome TWIN. Nous avons introduit le terme « semi-libre » dans notre article de démonstration dans sa version faible pour indiquer que c’est vraiment la paire de particules qui prend conjointement une décision libre.
Historiquement, ce genre de corrélation a été une grande surprise, que de nombreux auteurs ont tenté d’expliquer en disant que l’une des particules influence l’autre. Cependant, comme nous l’expliquons en détail dans notre première démonstration, la corrélation est relativistiquement invariante, contrairement à toute explication de cette sorte. Notre attitude est différente : suivant le fameux dicton de Newton « Hypotheses non fingo », nous ne tentons aucune explication, mais acceptons la corrélation comme un fait de la vie.
Certains croient que l’alternative au déterminisme est le hasard, et ajoutent que « permettre au hasard d’entrer dans le monde n’aide pas vraiment à comprendre le libre arbitre ». Cependant, cette objection ne s’applique pas aux réponses libres des particules que nous avons décrites. Il est peut-être vrai que les processus stochastiques classiques comme le lancer d’une pièce (vraie) n’aident pas à expliquer le libre arbitre, mais l’ajout du hasard n’explique pas non plus les effets mécaniques quantiques décrits dans notre théorème. C’est précisément la nature « semi-libre » des particules jumelées, et plus généralement de l’enchevêtrement, qui montre que quelque chose de très différent du stochasticisme classique est en jeu ici.
Bien que le théorème du libre arbitre nous suggère que le déterminisme n’est pas une option viable, il nous permet néanmoins de convenir avec Einstein que « Dieu ne joue pas aux dés avec l’Univers ». Dans l’état actuel des connaissances, il est certainement au-delà de nos capacités de comprendre la connexion entre les décisions libres des particules et des humains, mais le libre arbitre d’aucun de ces deux éléments n’est expliqué par le simple hasard.
La tension entre le libre arbitre humain et le déterminisme physique a une longue histoire. Il y a longtemps, Lucretius a fait « dévier » de façon imprévisible ses particules qui auraient été sinon déterministes pour permettre le libre arbitre.
Ce fut en grande partie le grand succès de la physique classique déterministe qui a conduit à l’adoption du déterminisme par tant de philosophes et de scientifiques, en particulier dans les domaines éloignés de la physique actuelle. Cette remarque s’applique également au « compatibalisme », une tentative maintenant inutile de permettre le libre arbitre humain dans un monde déterministe.
Bien que le déterminisme puisse formellement être démontré comme étant cohérent, il n’y a désormais plus de preuve ou évidence qui le soutienne, compte tenu du fait que la physique classique a été remplacée par la mécanique quantique, une théorie non déterministe.
L’importance du théorème du libre arbitre est qu’il montre que ce n’est pas seulement la théorie quantique actuelle, mais le monde lui-même qui est non-déterministe, de sorte qu’aucune théorie future ne peut nous ramener à un univers mécanique.

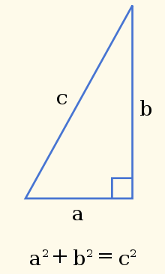
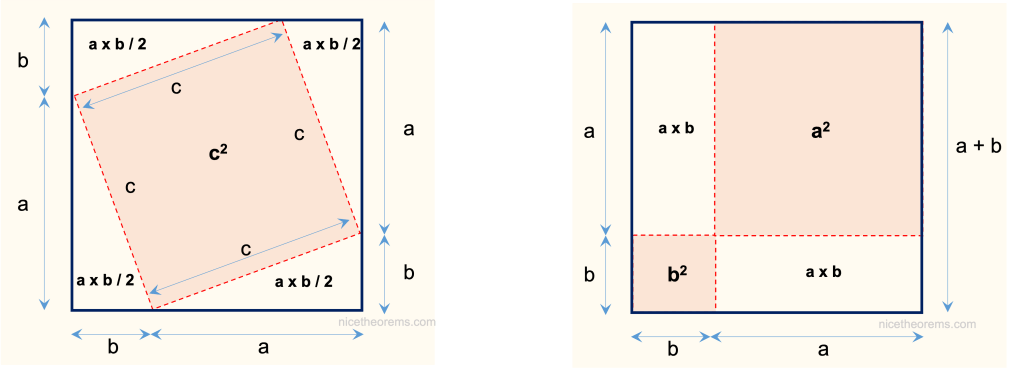


 .
.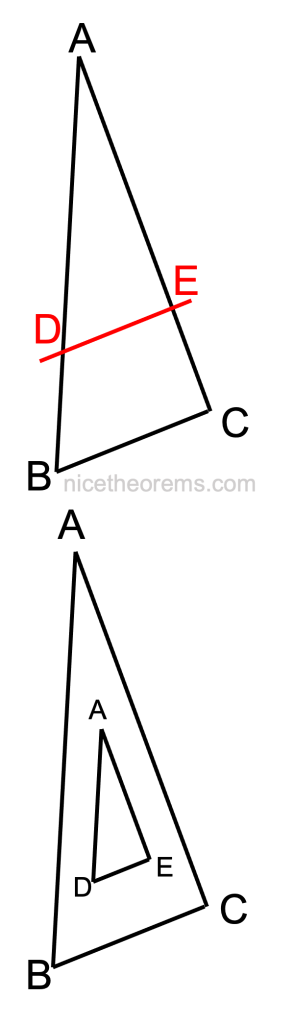
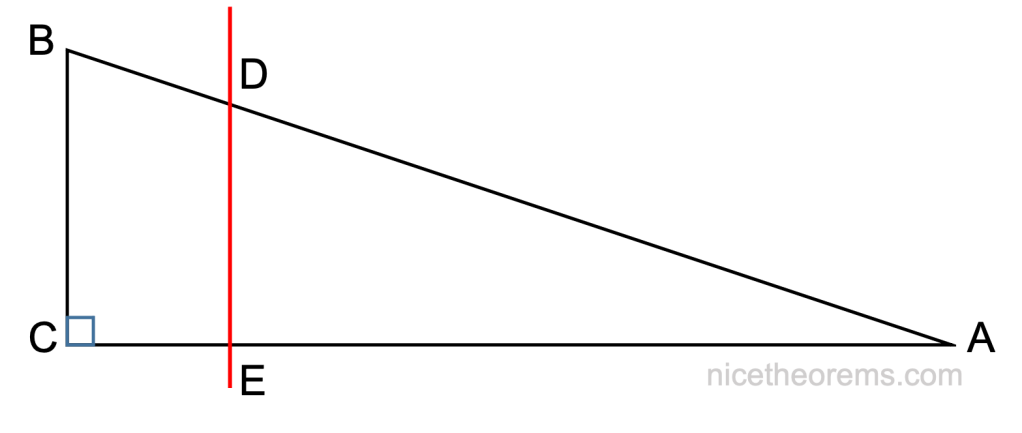
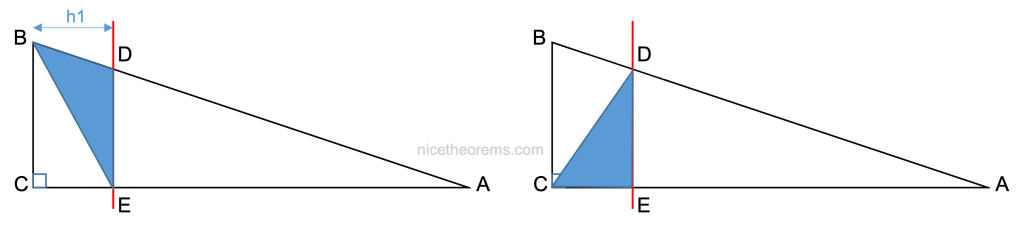
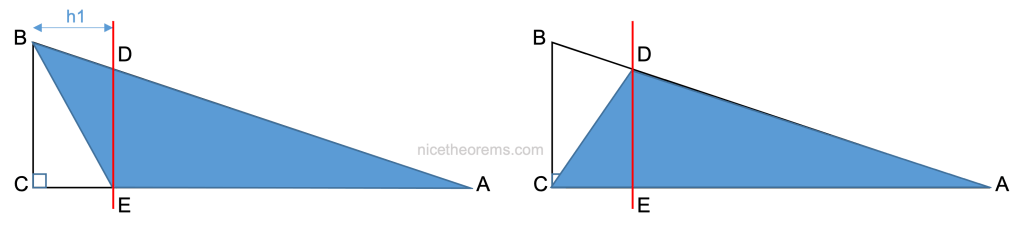
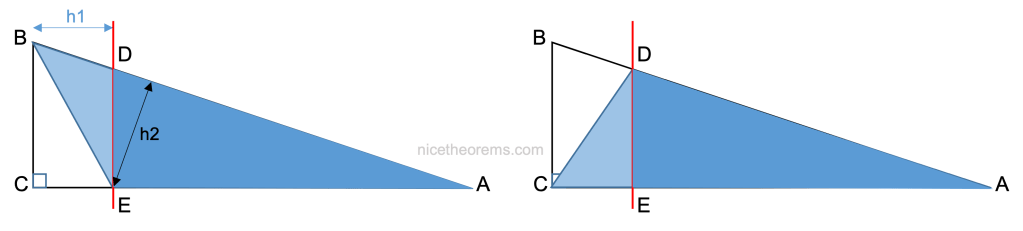
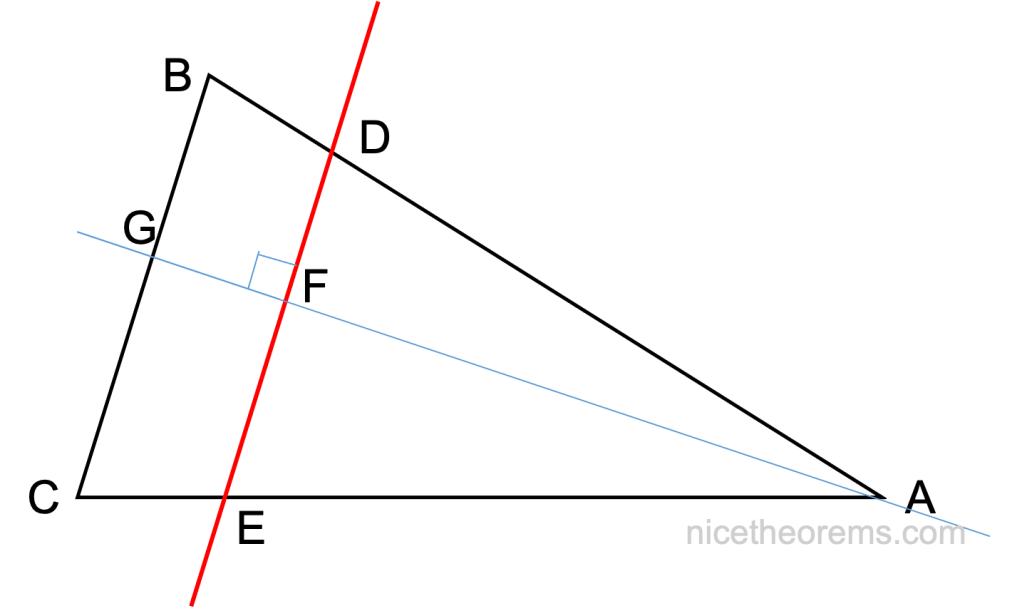
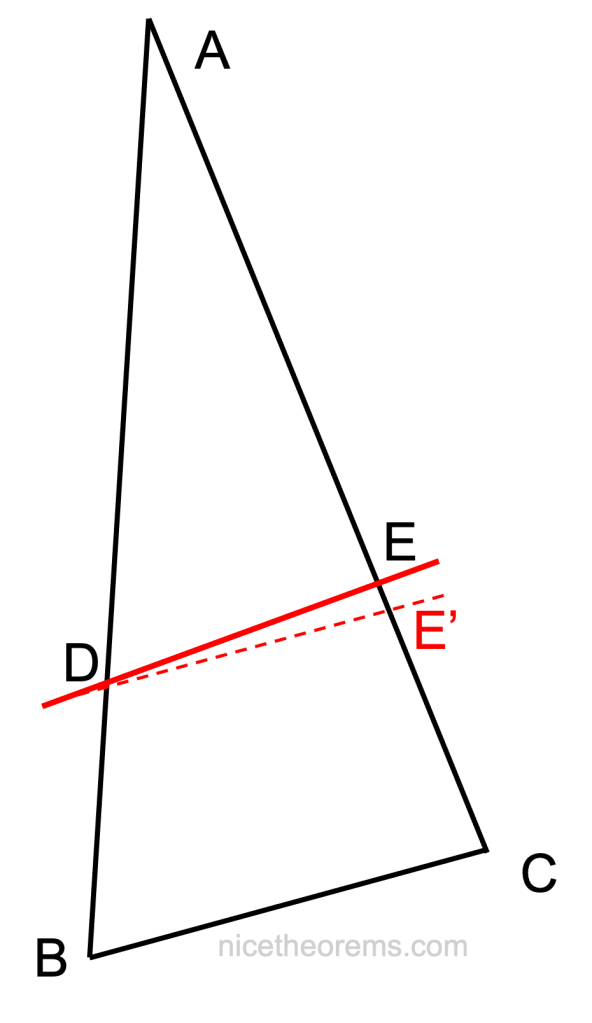
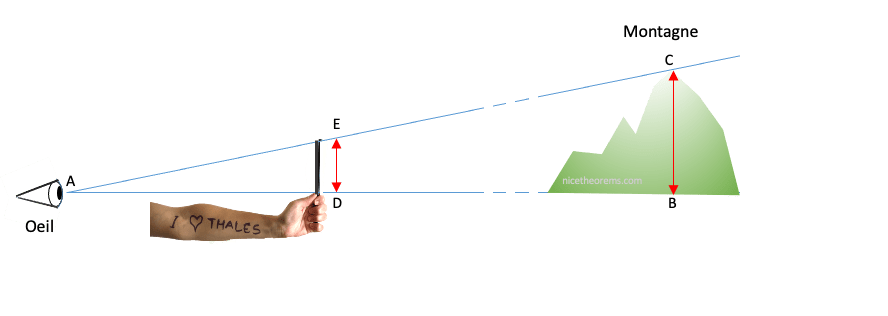

 P(x) = (x – 1) (x – 2) (x – 3) …(x – k)…(x – (p – 2)) (x – (p – 1)).
P(x) = (x – 1) (x – 2) (x – 3) …(x – k)…(x – (p – 2)) (x – (p – 1)).